단어 추출 도구 v0.41 배포: 단어의 DBSchema 발생 빈도 항목을 추가
* 버그를 수정하여 새로 배포한 v0.42도 함께 참조하기 바란다.
단어 추출 도구 v0.42 배포: Bug fix – 생산성 Skill (prodskill.com)
기존에 배포한 단어 추출 도구(v0.40)에서 단어의 DBSchema 발생 빈도 항목을 추가하여 추출하도록 기능을 보완하여 배포한다. DBSchema_Freq 항목은 해당 단어의 출처가 몇 개의 DB-Schema에 분포해 있는지 알려준다.

출처: https://stocksnap.io/photo/dictionary-page-ELRF6CYOHI
1. 단어 추출 도구 결과 변경 내용
이전에 배포했던 도구의 단어 추출 결과 예시는 다음과 같다.
▼ 변경전 “단어빈도” 시트 예시 (v0.40)
| 단어 | Freq | Source |
| 코드 | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(행정구역코드) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(변경구분코드) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(시도코드) … |
| 번호 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(작업일련번호) DB1.OWNER1.COMTCZIP.ZIP(우편번호) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(승인번호) … |
| 명 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(주소록명) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(분류코드명) DB1.OWNER1.COMTCCMMNDETAILCODE.CODE_NM(코드명) … |
v0.41에서 추출한 결과에는 다음과 같이 DBSchema_Freq 항목이 추가된다.
▼ 변경 후 “단어빈도” 시트 예시 (v0.41)
| 단어 | Freq | Source | DBSchema_Freq |
| 코드 | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(행정구역코드) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(변경구분코드) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(시도코드) … | 10 |
| 번호 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(작업일련번호) DB1.OWNER1.COMTCZIP.ZIP(우편번호) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(승인번호) … | 9 |
| 명 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(주소록명) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(분류코드명) DB1.OWNER1.COMTCCMMNDETAILCODE.CODE_NM(코드명) … | 5 |
DBSchema_Freq 항목은 해당 단어의 출처가 몇 개의 DB-Schema에 분포해 있는지 알려준다. 표준 단어 후보군을 선별하는데 필요한 정보를 조금 더 상세하게 제공해 줄 수 있다.
- 빈도(Freq)는 높으나 DBSchema 빈도(DBSchema_Freq)는 낮은 경우
- 해당 단어는 특정 DB-Schema에만 집중적으로 발생하고 있음
- 빈도(Freq)와 DBSchema 빈도(DBSchema_Freq)가 모두 높은 경우
- 해당 단어는 전체 DB-Schema에 골고루 분포되어 있음
- 빈도(Freq)는 낮으나 DBSchema 빈도(DBSchema_Freq)가 상대적으로 높은 경우
- 해당 단어는 표준 단어 후보에 제외하지 않고 포함 검토
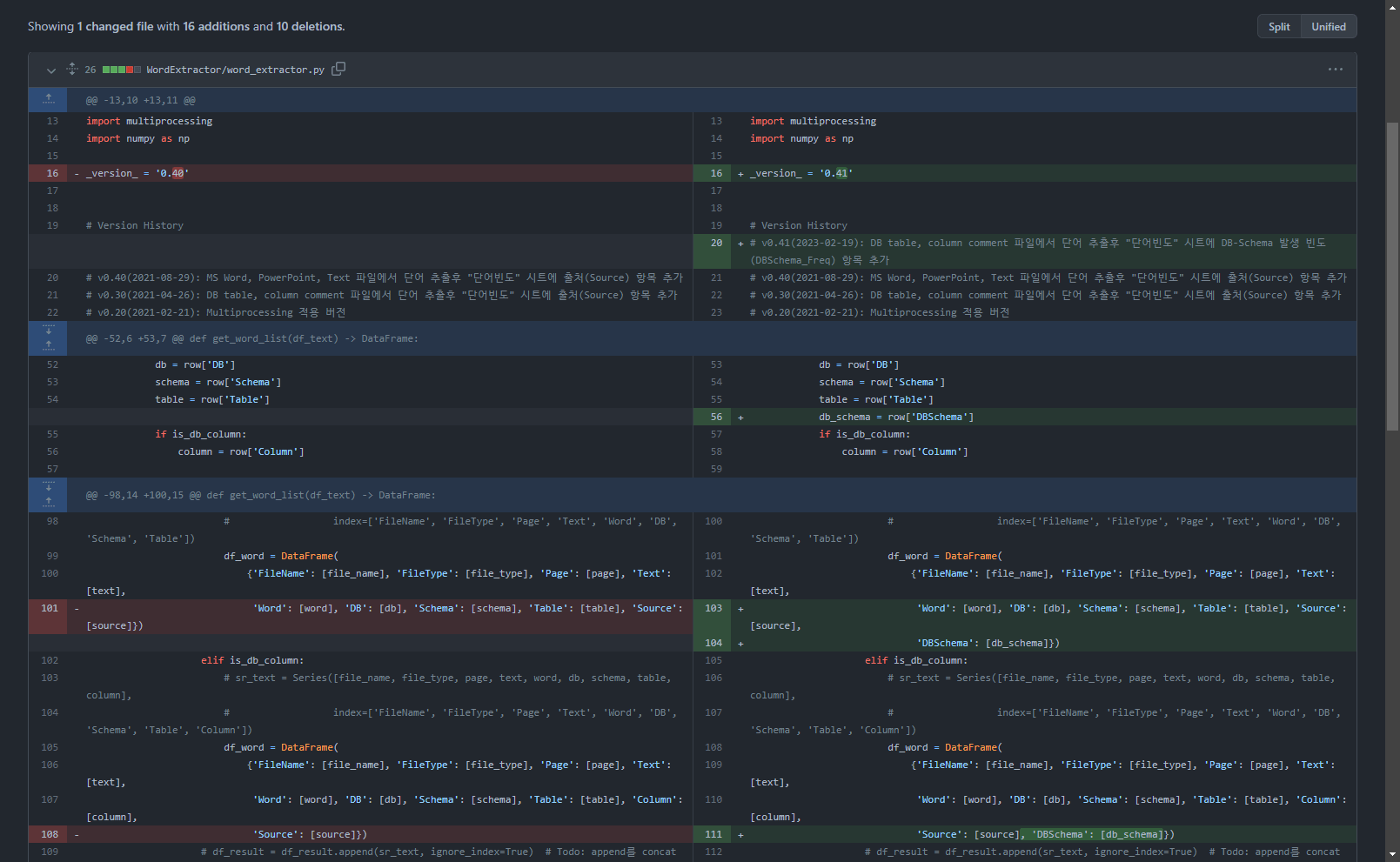
2. 소스 코드 변경 내용
세 개 함수에 변경이 있다.
2.1. get_db_comment_text 함수 변경
343행 추가: 텍스트 추출결과를 담고 있는 dataframe 변수 df_text에 DBSchema 컬럼을 만들고 값을 생성
df_text['DBSchema'] = df_text['DB'] + '.' + df_text['Schema'] # DB.Schema 값 생성(2023-02-19)
2.2. get_word_list 함수 변경
104, 111행 추가: 단어 추출결과 dataframe에 DBSchema 값 추가
if len(words) >= 1:
# print(nouns, text)
for word in words:
# print(noun, '\t', text)
if not is_db:
# sr_text = Series([file_name, file_type, page, text, word],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'Source': [source]})
elif is_db_table:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Source': [source],
'DBSchema': [db_schema]})
elif is_db_column:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table, column],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table', 'Column'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Column': [column],
'Source': [source], 'DBSchema': [db_schema]})
2.3. main 함수 변경
2.3.1. 변경 전 main 함수 내용
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
2.3.2. 변경 후 main 함수 내용
df_group = df_result.groupby('Word').agg({
'Word': 'count',
'Source': lambda x: '\n'.join(list(x)[:10]),
'DBSchema': 'nunique'
}).rename(columns={
'Word': 'Freq',
'Source': 'Source',
'DBSchema': 'DBSchema_Freq'
})
이 코드는 단어 추출결과 dataframe 변수인 df_result에서 Word(단어)로 묶고(groupby) DBSchema 값의 중복을 제거한 개수(nunique)를 구하여 그 항목의 명칭을 DBSchema_Freq로 명명한다.
참고로, 이 코드는 작성한 테스트 코드를 ChatGPT에게 주고, 단순화(simplification) 해달라고 요청하여 받은 코드이다. 단순화 전에는 두 개의 dataframe으로 나누어서 각각 lambda와 nunique를 적용한 다음 다시 하나로 merge하는 복잡한 코드였다. 요즘 ChatGPT 능력에 감탄하는 중이다.
2.4. v0.41에서 달라진 소스코드 전체 상세보기
아래 github 링크에서 변경된 내용을 상세하게 확인할 수 있다.
3. 단어 추출 도구(v0.41) 다운로드와 실행
아래 링크에서 변경된 word_extractor.py 파일을 확인할 수 있다.
ToolsForDataStandard/word_extractor.py at main · DAToolset/ToolsForDataStandard (github.com)
실행방법은 v0.40과 동일하다. 아래 내용을 참고하기 바란다.
단어 추출 도구 v0.41은 충분히 테스트되지 않아서 오류 또는 버그가 발생할 수 있다. 사용중 오류, 버그, 문의 등은 댓글로 남겨주기 바란다.


















안녕하세요!
3가지 실행 방법 중 1번인 DB comment 없이 File에서 단어를 추출하는 방식을 사용했을 때
(python word_extractor.py –in_path .\in –out_path .\out)
txt, word, ppt 모두
miniconda3\envs\wordextr\lib\site-packages\pandas\core\apply.py”, line 601, in normalize_dictlike_arg raise KeyError(f”Column(s) {cols_sorted} do not exist”)
KeyError: “Column(s) [‘DBSchema’] do not exist”
에러가 발생하면서 종료되고 있습니다.
DB comment 파일이 들어가는 2번, 3번 실행 방법은 에러 없이 작동하고 있습니다.
97번 라인에 ‘DBSchema’: [db_schema] 를 넣어보았는데 이번엔
in get_grouper raise KeyError(gpr) KeyError: ‘Word’ 라는 에러가 뜬 상황입니다.
감사합니다.
버그 알려주셔서 감사합니다.
File에서만 단어를 추출하는 경우를 테스트하지 않고 배포했군요.
조만간 테스트하고 버그 수정한 버전을 다시 배포하겠습니다.
버그를 수정한 v0.42를 다시 배포했습니다.
https://prodskill.com/ko/word-extractor-v0-42-bug-fix-for-dbschema/
감사합니다.