데이터 표준점검 도구 v1.35_20230321 배포
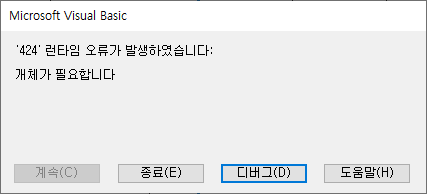
물리명 기준의 표준점검 기능 사용시 “‘424’ 런타임 오류가 발생하였습니다. 개체가 필요합니다.” 메시지의 오류가 발생하는 경우가 있다. 이 오류를 수정한 데이터 표준점검 도구 v1.35_20230321 를 배포한다.
*(참고) 지난 번 배포 글: 데이터 표준점검 도구 v1.34_20221215 배포
1. 현상
“표준점검(물리명기준)” 시트에서 C열(컬럼명(물리명))에 컬럼명을 입력하고 표준 점검 버튼을 클릭하면 다음과 같은 “‘424’ 런타임 오류가 발생하였습니다. 개체가 필요합니다.” 오류가 발생한다.
2. 원인
이 오류는 항상 발생하는 것은 아니고, 물리명을 구분자(_, underscore)로 나누었을 때 각 token이 단어사전의 물리명에 없을 때 발생한다.
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx)) '<-- 오류 발생
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sLName = sLName + IIf(sLName = "", "", "_") + oStdWord.m_s단어논리명
End If
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
위 코드 15행에서 aColNamePart(lColNamePartIdx)는 underscore 문자로 나누어진 token들의 n번째 값을 의미한다. 이 값이 oStdWordDic(단어사전 dictionary 개체)의 ItemP(물리명을 key로, 단어개체를 value로 관리하는 dictionary 개체)에 존재하지 않을 때 오류가 발생한다.
3. 조치 내용
다음과 같이 코드를 변경하였다.
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
Dim sTokenP As String, sTokenL As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
sTokenP = aColNamePart(lColNamePartIdx)
sTokenL = ""
If oStdWordDic.ExistsP(sTokenP) Then '단어 물리명이 사전에 있는 경우
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx))
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sTokenL = oStdWord.m_s단어논리명
End If
Else
'단어 물리명이 사전에 없는 경우
sTokenL = "[" + sTokenP + "]"
End If
sLName = sLName + IIf(sLName = "", "", "_") + sTokenL
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
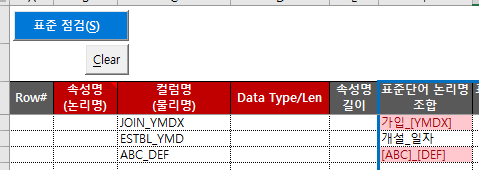
단어 물리명이 사전에 있는 경우(18행)와 없는 경우(25행)를 구분하여 오류가 없도록 하고, 사전에 없는 경우 “[…]” 형태로 변형하여 조건부서식에 의해 눈에 띄도록 하였다.
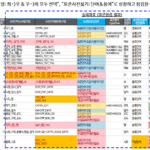
단어 물리명이 사전에 없는 경우는 다음 예시와 같이 표시된다. 일부러 단어 사전에 없는 YMDX, ABC, DEF를 입력한 예시이다.
4. 데이터 표준점검 도구 v1.35_20230321 다운로드
패치버전을 github에 올려 두었고, 아래 URL에서 다운로드할 수 있다.
https://github.com/DAToolset/ToolsForDataStandard/raw/main/속성%20표준점검%20도구_v1.35_20230321_1.xlsm


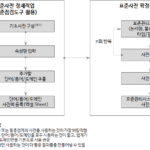
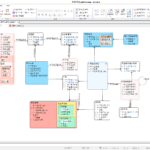










표준사전 Repository 관련 Config 에 표준사전 쿼리 입니다.
Repository DB : PostgreSQL, 표준화 대상 DB : SQL Server
–표준단어사전 Query
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS “단어논리명”
,D.DIC_PHY_NM AS “단어물리명”
,D.DIC_PHY_FLL_NM AS “단어영문명”
,D.DIC_DESC AS “단어설명”
,D.STANDARD_YN AS “표준여부”
,(case D.ATTR_CLSS_YN when ‘Y’ then ‘Y’ else ‘N’ END) AS “속성분류어여부”
,CASE
WHEN D.STANDARD_YN = ‘Y’ AND SIM.표준논리명 IS NULL THEN D.DIC_LOG_NM
WHEN D.STANDARD_YN = ‘Y’ AND SIM.표준논리명 IS NOT NULL THEN SIM.표준논리명
ELSE SIM.표준논리명
END “표준논리명”
,SIM.동의어
,G.DOM_GRP_NM AS “도메인분류명”
/*
,D.ENT_CLSS_YN AS “엔터티분류어여부
*/
FROM dataware.STD_AREA A
,dataware.STD_DIC D
left outer join
(SELECT DM.KEY_DOM_NM
,MAX(DM.DOM_GRP_ID) DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
FROM dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
WHERE DM.STD_AREA_ID = ‘키값 확인 필요!!!’
AND DM.AVAL_END_DT = ‘99991231235959’
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = ‘99991231235959’
AND DM.DOM_GRP_ID = DG.DOM_GRP_ID
GROUP BY DM.KEY_DOM_NM) G
on D.DIC_LOG_NM = G.KEY_DOM_NM
left outer join
(
— 표준인 경우
SELECT A.P_DIC_ID “그룹ID”
,A.P_DIC_ID DIC_ID
,P.DIC_LOG_NM “표준논리명”
,STRING_AGG(C.DIC_LOG_NM, ‘,’ ORDER BY A.C_DIC_ID) “동의어”
FROM dataware.STD_DIC_REL A
left outer join dataware.STD_DIC P
on A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = ‘99991231235959’
left outer join dataware.STD_DIC C
on A.C_DIC_ID = C.DIC_ID and C.AVAL_END_DT = ‘99991231235959’
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘표준사전’)
AND A.AVAL_END_DT = ‘99991231235959’
GROUP BY A.P_DIC_ID, P.DIC_LOG_NM
UNION ALL
— 비표준인 경우
SELECT AA.P_DIC_ID “그룹ID”
,A.C_DIC_ID DIC_ID
,P.DIC_LOG_NM “표준논리명”
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ‘,’ ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN ‘0’ ELSE AA.C_DIC_ID END) “동의어”
FROM dataware.STD_DIC_REL A
,dataware.STD_DIC_REL AA
,dataware.STD_DIC P
,dataware.STD_DIC C
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘표준사전’)
AND A.AVAL_END_DT = ‘99991231235959’
AND A.P_DIC_ID = AA.P_DIC_ID
AND AA.P_DIC_ID = P.DIC_ID
AND P.AVAL_END_DT = ‘99991231235959’
AND AA.C_DIC_ID = C.DIC_ID
AND C.AVAL_END_DT = ‘99991231235959’
GROUP BY AA.P_DIC_ID, A.C_DIC_ID, P.DIC_LOG_NM
) SIM
on D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = ‘표준사전’
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = ‘99991231235959’
AND D.DIC_GBN_CD = ‘0001’ /* ‘0001’: 단어 */
/* AND D.STANDARD_YN = ‘Y’ 표준단어만 추출 */
ORDER BY D.DIC_LOG_NM, (case D.STANDARD_YN when ‘Y’ then 1 else 2 end)
;
–표준용어사전 Query
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS “용어논리명”
,
(
SELECT STRING_AGG(X.DIC_LOG_NM, ‘_’)
FROM
(
SELECT WRD.DIC_LOG_NM
FROM STD_DIC AS WRD
LEFT OUTER JOIN STD_WORD_COMBI AS C
ON WRD.STD_AREA_ID = C.STD_AREA_ID
AND WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘표준사전’)
AND C.TERM_ID = D.DIC_ID
AND C.AVAL_END_DT = ‘99991231235959’
ORDER BY C.ORDER_NO
) AS X
) AS “단어논리명조합”
,D.DIC_PHY_NM AS “용어물리명”
,D.DIC_DESC AS “용어설명”
,DM.DOM_NM AS “도메인논리명”
,UPPER(DT.DATA_TYPE) AS “데이터타입”
— ,DM.DATA_LEN AS “길이”
,(case when DM.DATA_LEN = -1 then ‘MAX’ else text(DM.DATA_LEN) END) AS “길이”
,DM.DATA_SCALE AS “정도”
, ” as “업무정의”
,UPPER(DT.DATA_TYPE)
||case
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) not in (‘INT’, ‘DATETIME2’) then null
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) in (‘INT’, ‘DATETIME2’) then ”
WHEN DM.DATA_LEN = -1 AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in (‘VARCHAR’, ‘VARBINARY’) THEN ‘(MAX’
else ‘(‘||DM.DATA_LEN
end
||CASE WHEN DM.DATA_LEN IS NOT NULL AND DM.DATA_SCALE IS NULL THEN ‘)’
WHEN DM.DATA_LEN IS NOT NULL and DM.DATA_LEN > 0 AND DM.DATA_SCALE IS NOT NULL THEN ‘,’||DM.DATA_SCALE||’)’
WHEN DM.DATA_LEN IS NULL AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in (‘INT’, ‘DATETIME2’) THEN ”
ELSE NULL end
AS “TypeSize”
FROM dataware.STD_AREA A
,dataware.STD_DIC D
,dataware.STD_DOM DM
,dataware.STD_DATATYPE DT
WHERE A.STD_AREA_NM = ‘표준사전’
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = ‘99991231235959’
AND D.DIC_GBN_CD = ‘0002’ /* ‘0002’: 용어 */
AND D.STANDARD_YN = ‘Y’ /* 표준용어만 추출 */
AND DM.STD_AREA_ID = D.STD_AREA_ID
AND DM.AVAL_END_DT = ‘99991231235959’
AND DM.DOM_ID = D.DOM_ID
AND DT.DB_TYPE = ‘0006’ –SQL SERVER
AND DT.CD_NO = DM.DATA_TYPE_CD
;
–표준도메인사전 Query
SELECT ROW_NUMBER() OVER (ORDER BY DG.DOM_GRP_NM, DM.DOM_NM) AS NO
,DG.DOM_GRP_NM AS “도메인분류명”
,DM.DOM_NM AS “도메인논리명”
,DM.KEY_DOM_PHY_NM AS “키도메인물리명”
,(case DM.DOM_DESC when null then DM.KEY_DOM_NM else DM.DOM_DESC END) AS “도메인설명”
,UPPER(DT.DATA_TYPE) AS “데이터타입명”
,(case when DM.DATA_LEN = -1 then ‘MAX’ else text(DM.DATA_LEN) END) AS “길이”
,DM.DATA_SCALE AS “정도”
,UPPER(DT.DATA_TYPE)
||case
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) not in (‘INT’, ‘DATETIME2’) then null
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) in (‘INT’, ‘DATETIME2’) then ”
WHEN DM.DATA_LEN = -1 AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in (‘VARCHAR’, ‘VARBINARY’) THEN ‘(MAX’
else ‘(‘||DM.DATA_LEN
end
||CASE WHEN DM.DATA_LEN IS NOT NULL AND DM.DATA_SCALE IS NULL THEN ‘)’
WHEN DM.DATA_LEN IS NOT NULL and DM.DATA_LEN > 0 AND DM.DATA_SCALE IS NOT NULL THEN ‘,’||DM.DATA_SCALE||’)’
WHEN DM.DATA_LEN IS NULL AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in (‘INT’, ‘DATETIME2’) THEN ”
ELSE NULL end
AS “TypeSize”
/*
,DM.KEY_DOM_NM AS “키도메인명”
*/
FROM dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
,dataware.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘표준사전’)
AND DM.AVAL_END_DT = ‘99991231235959’
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = ‘99991231235959’
AND DG.DOM_GRP_ID = DM.DOM_GRP_ID
AND DT.DB_TYPE = ‘0006’
AND DT.CD_NO = DM.DATA_TYPE_CD
;
표준사전 조회 SQL 공유해 주셔서 감사합니다.
저도 PostgreSQL 버전 사용시 활용하겠습니다.
댓글에 공백문자 들여쓰기가 표시 안되네요.
방법을 찾아보겠습니다.
표준 점검시 속성명(CUSTOMER NUMBER)을 영문단어로만 조합된 된 경우 표준용어를 등록해 놓아도 표준단어 조합하고 표준영어 일치는 체크를 못하는 증상이 있습니다. 구분자를 언더바, 스페이스로 처리하는 로직?과 관련이 있지 않나 싶습니다.
EX)
*표준단어, 약어
CUSTOMER, CUST
NUMBER, NO
*표준용어, 도메인
CUSTOMER NUMBER, NUMBER V10
*표준도메인, 데이터 타입
NUMBER V10, VARCHAR(10)
https://prodskill.com/ko/data-standard-checker-4-case-study/#33_%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80_%EC%98%88%EC%8B%9C_Case_2_%ED%91%9C%EC%A4%80%EB%8B%A8%EC%96%B4_%EC%A1%B0%ED%95%A9
이 글에 다음과 같은 내용이 있습니다.
—————————————————————
속성 “개인대상 여부” (Row# 9)는 공백을 포함하고 있다. “표준단어 논리명 조합” 항목에 “[개인대상]_여부”로 표시된 것은, “[개인대상]”은 표준단어사전에 없고, “여부”는 표준단어사전에 있다는 의미이다. 이 cell도 미등록문자가 포함되어 있어 배경색이 붉은 색으로 설정되었다. 속성명에 구분자를 포함하는 경우 “속성명 점검 결과” 항목에 “(사용자 지정)”으로 표시한다.
—————————————————————
표준 점검 대상 속성명에 공백 문자는 의도적으로 단어를 구분하는 의미로 사용하고 있습니다.
현재 구현된 기능으로는 표준용어 논리명에 공백을 허용하는 경우 표준용어 기준으로 일치여부 점검이 되지 않습니다.
점검 대상 속성명에 입력된 공백을 “의도된 단어 구분자”로 다룰지, “공백문자” 그 자체로 다룰지 선택하는 옵션을 만들어서 처리하면 원하시는 점검이 가능할 것 같네요.
필요하신가요? ^^
영문으로 모델링 하는 경우는 속성명을 한글 단어 처럼 붙쳐 사용하면 단어 식별이 힘들기 때문에 영문 단어 사이를 빈칸(Space) 로 구분해야 하는 경우 옵션 필요할 것 같습니다.. ^^;;
https://github.com/DAToolset/ToolsForDataStandard/raw/main/%EC%86%8D%EC%84%B1%20%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80%20%EB%8F%84%EA%B5%AC_v1.36_20230426_1.xlsm
v1.36에 표준점검 대상 속성명의 공백문자를 단어 구분자로 처리하지 않도록 변경했습니다.
이에 따라 점검대상 속성명 작성 규칙도 다음과 같이 변경되었습니다.
※ 속성명 작성 규칙
1. 단어 사이에 공백 없이 입력: 기본
– 예: 작업자동실행여부
2. 단어 사이에 공백 입력: 속성 논리명을 영문으로 작성하는 경우
– 예: CUSTOMER NUMBER
3. “_”로 구분하여 입력: 단어 구성을 지정할 경우
– 예: 작업_자동_실행_여부
테스트해보시고 의견 부탁드립니다.
속성명 : CUSTOMER SPLIT NUMBER
표준 점검 시 속성명 점검 결과는 표준단어 조합으로 표시되나, 표준단어 논리명 조합, 물리명 조합 결과가 잘못 처리 됨
CUSTOMER, SPLIT, NUMBER : 3개 표준단어가 등록된 상태
표준단어 논리명 조합 : CUSTOMER_[ ]_SPLIT_[ ]_NUMBER
표준단어 물리명 조합 : CUST_[ ]_SPLT_[ ]_NO
너무 간단히 봤군요 ^^;;
조금 더 테스트해 보고 다시 배포하겠습니다.
v1.36 다시 배포했습니다.
https://prodskill.com/ko/data-standard-checker-v1-36/
Repository DB : PostgreSQL, 표준화 대상 DB : PostgreSQL
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS “단어논리명”
,D.DIC_PHY_NM AS “단어물리명”
,D.DIC_PHY_FLL_NM AS “단어영문명”
,D.DIC_DESC AS “단어설명”
,D.STANDARD_YN AS “표준여부”
,(case D.ATTR_CLSS_YN when ‘Y’ then ‘Y’ else ‘N’ END) AS “속성분류어여부”
,CASE
WHEN D.STANDARD_YN = ‘Y’ AND SIM.표준논리명 IS NULL THEN D.DIC_LOG_NM
WHEN D.STANDARD_YN = ‘Y’ AND SIM.표준논리명 IS NOT NULL THEN SIM.표준논리명
ELSE SIM.표준논리명
END “표준논리명”
,SIM.동의어
,G.KEY_DOM_NM AS “도메인분류명”
/*
,D.ENT_CLSS_YN AS “엔터티분류어여부
*/
FROM dataware.STD_AREA A
,dataware.STD_DIC D
left outer join
(SELECT DM.KEY_DOM_NM
,MAX(DM.DOM_GRP_ID) DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
FROM dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
WHERE DM.STD_AREA_ID = ‘47430eed-15a9-4697-90e3-a70040266517’
AND DM.AVAL_END_DT = ‘99991231235959’
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = ‘99991231235959’
AND DM.DOM_GRP_ID = DG.DOM_GRP_ID
GROUP BY DM.KEY_DOM_NM) G
on D.DIC_LOG_NM = G.KEY_DOM_NM
left outer join
(
–표준인 경우
SELECT A.P_DIC_ID “그룹ID”
,A.P_DIC_ID DIC_ID
,P.DIC_LOG_NM “표준논리명”
,STRING_AGG(C.DIC_LOG_NM, ‘,’ ORDER BY A.C_DIC_ID) “동의어”
FROM dataware.STD_DIC_REL A
left outer join dataware.STD_DIC P
on A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = ‘99991231235959’
left outer join dataware.STD_DIC C
on A.C_DIC_ID = C.DIC_ID and C.AVAL_END_DT = ‘99991231235959’
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘0.표준사전’)
AND A.AVAL_END_DT = ‘99991231235959’
GROUP BY A.P_DIC_ID, P.DIC_LOG_NM
UNION ALL
–비표준인 경우
SELECT AA.P_DIC_ID “그룹ID”
,A.C_DIC_ID DIC_ID
,P.DIC_LOG_NM “표준논리명”
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ‘,’ ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN ‘0’ ELSE AA.C_DIC_ID END) “동의어”
FROM dataware.STD_DIC_REL A
,dataware.STD_DIC_REL AA
,dataware.STD_DIC P
,dataware.STD_DIC C
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘0.표준사전’)
AND A.AVAL_END_DT = ‘99991231235959’
AND A.P_DIC_ID = AA.P_DIC_ID
AND AA.P_DIC_ID = P.DIC_ID
AND P.AVAL_END_DT = ‘99991231235959’
AND AA.C_DIC_ID = C.DIC_ID
AND C.AVAL_END_DT = ‘99991231235959’
GROUP BY AA.P_DIC_ID, A.C_DIC_ID, P.DIC_LOG_NM
) SIM
on D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = ‘0.표준사전’
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = ‘99991231235959’
AND D.DIC_GBN_CD = ‘0001’ /* ‘0001’: 단어 */
/* AND D.STANDARD_YN = ‘Y’ 표준단어만 추출 */
ORDER BY D.DIC_LOG_NM, (case D.STANDARD_YN when ‘Y’ then 1 else 2 end)
;
–표준용어사전 Query
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS “용어논리명”
,
(
SELECT STRING_AGG(X.DIC_LOG_NM, ‘_’)
FROM
(
SELECT WRD.DIC_LOG_NM
FROM STD_DIC AS WRD
LEFT OUTER JOIN STD_WORD_COMBI AS C
ON WRD.STD_AREA_ID = C.STD_AREA_ID
AND WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘0.표준사전’)
AND C.TERM_ID = D.DIC_ID
AND C.AVAL_END_DT = ‘99991231235959’
AND WRD.AVAL_END_DT = ‘99991231235959’
ORDER BY C.ORDER_NO
) AS X
) AS “단어논리명조합”
,D.DIC_PHY_NM AS “용어물리명”
,D.DIC_DESC AS “용어설명”
,DM.DOM_NM AS “도메인논리명”
,UPPER(DT.DATA_TYPE) AS “데이터타입”
— ,DM.DATA_LEN AS “길이”
,(case when DM.DATA_LEN = -1 then ‘MAX’ else text(DM.DATA_LEN) END) AS “길이”
,DM.DATA_SCALE AS “정도”
, ” as “업무정의”
, replace(
UPPER(DT.DATA_TYPE)
||'(‘
|| case when DM.DATA_LEN is null then ” else cast(DM.DATA_LEN as text) end
|| case when DM.DATA_SCALE is null then ” else cast(DM.DATA_SCALE as text) end
||’)’
, ‘()’, ”) AS “TypeSize”
FROM dataware.STD_AREA A
,dataware.STD_DIC D
,dataware.STD_DOM DM
,dataware.STD_DATATYPE DT
WHERE A.STD_AREA_NM = ‘0.표준사전’
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = ‘99991231235959’
AND D.DIC_GBN_CD = ‘0002’ /* ‘0002’: 용어 */
AND D.STANDARD_YN = ‘Y’ /* 표준용어만 추출 */
AND DM.STD_AREA_ID = D.STD_AREA_ID
AND DM.AVAL_END_DT = ‘99991231235959’
AND DM.DOM_ID = D.DOM_ID
AND DT.DB_TYPE = ‘0024’
AND DT.CD_NO = DM.DATA_TYPE_CD
;
–표준도메인사전 Query
SELECT ROW_NUMBER() OVER (ORDER BY DG.DOM_GRP_NM, DM.DOM_NM) AS NO
,DM.key_dom_nm AS “도메인분류명”
,DM.DOM_NM AS “도메인논리명”
,DM.KEY_DOM_PHY_NM AS “키도메인물리명”
,(case DM.DOM_DESC when null then DM.KEY_DOM_NM else DM.DOM_DESC END) AS “도메인설명”
,UPPER(DT.DATA_TYPE) AS “데이터타입명”
,DM.DATA_LEN AS “길이”
,DM.DATA_SCALE AS “정도”
, replace(
UPPER(DT.DATA_TYPE)
||'(‘
|| case when DM.DATA_LEN is null then ” else cast(DM.DATA_LEN as text) end
|| case when DM.DATA_SCALE is null then ” else cast(DM.DATA_SCALE as text) end
||’)’
, ‘()’, ”) AS “TypeSize”
, dg.dom_grp_nm as “표준도메인그룹명”
/*
,DM.KEY_DOM_NM AS “키도메인명”
*/
FROM dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
,dataware.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = ‘99991231235959’ AND STD_AREA_NM = ‘0.표준사전’)
AND DM.AVAL_END_DT = ‘99991231235959’
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = ‘99991231235959’
AND DG.DOM_GRP_ID = DM.DOM_GRP_ID
AND DT.DB_TYPE = ‘0024’
AND DT.CD_NO = DM.DATA_TYPE_CD
;
공유해 주셔서 감사합니다.