Herramienta de verificación de estándares de distribución de datos v1.35_20230321
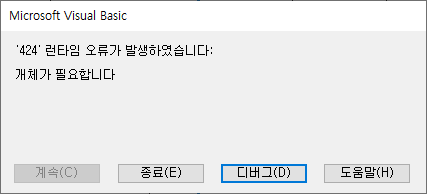
Al utilizar la función de verificación estándar basada en el nombre físico, se produjo un error de tiempo de ejecución "'424'. Necesitamos un objeto”. Hay casos en los que se produce un error en el mensaje. Distribuimos la herramienta de verificación estándar de datos v1.35_20230321, que corrige este error.
*(Referencia) Último artículo distribuido: Implementar herramienta de verificación de estándares de datos v1.34_20221215
1. Fenómeno
Cuando ingresa un nombre de columna en la columna C (nombre de columna (nombre físico)) en la hoja "Verificación estándar (basada en el nombre físico)" y hace clic en el botón de verificación estándar, se produce el siguiente error de tiempo de ejecución "424". Necesitamos un objeto”. Se produce un error.
2. causa
Este error no siempre ocurre y ocurre cuando el nombre físico se divide por un delimitador (_, guión bajo) y cada token no está en el nombre físico en el diccionario de palabras.
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx)) '<-- 오류 발생
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sLName = sLName + IIf(sLName = "", "", "_") + oStdWord.m_s단어논리명
End If
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
En la línea 15 del código anterior, aColNamePart(lColNamePartIdx) significa el enésimo valor de los tokens dividido por el carácter de subrayado. Se produce un error cuando este valor no existe en ItemP (un objeto de diccionario que administra nombres físicos como claves y objetos de palabras como valores) de oStdWordDic (objeto de diccionario de palabras).
3. Medidas
El código se cambió de la siguiente manera.
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
Dim sTokenP As String, sTokenL As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
sTokenP = aColNamePart(lColNamePartIdx)
sTokenL = ""
If oStdWordDic.ExistsP(sTokenP) Then '단어 물리명이 사전에 있는 경우
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx))
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sTokenL = oStdWord.m_s단어논리명
End If
Else
'단어 물리명이 사전에 없는 경우
sTokenL = "[" + sTokenP + "]"
End If
sLName = sLName + IIf(sLName = "", "", "_") + sTokenL
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
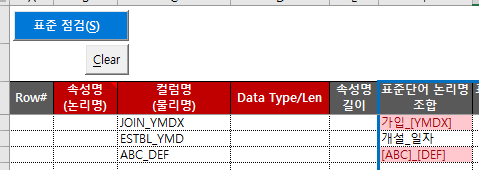
Para evitar errores, distinguimos entre casos donde el nombre físico de una palabra está en el diccionario (línea 18) y casos donde no está (línea 25), y cuando no está en el diccionario, “[…]” ]” y lo hizo destacar usando formato condicional.
Si el nombre físico de una palabra no está en el diccionario, se muestra como en el siguiente ejemplo. Este es un ejemplo de cómo ingresar intencionalmente YMDX, ABC y DEF, que no están en el diccionario.
4. Descargue la herramienta de verificación estándar de datos v1.35_20230321
La versión del parche se cargó en github y se puede descargar desde la siguiente URL.
https://github.com/DAToolset/ToolsForDataStandard/raw/main/속성%20표준점검%20도구_v1.35_20230321_1.xlsm
Artículos relacionados:
 Implementar herramienta de verificación de estándares de datos v1.34_20221215
Implementar herramienta de verificación de estándares de datos v1.34_20221215
 Herramienta de verificación estándar de datos Descripción Contenido, Descargar
Herramienta de verificación estándar de datos Descripción Contenido, Descargar
 Herramienta de verificación estándar de datos_4.Adjunto
Herramienta de verificación estándar de datos_4.Adjunto
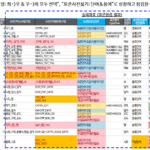 Herramienta de inspección estándar de datos_3. Resultados de inspección estándar por caso
Herramienta de inspección estándar de datos_3. Resultados de inspección estándar por caso
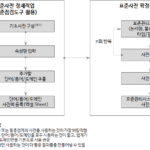
 Herramienta de inspección de estándares de datos_2.3 Composición del diccionario de estándares de datos
Herramienta de inspección de estándares de datos_2.3 Composición del diccionario de estándares de datos
 Herramienta de verificación estándar de datos_1.Descripción general
Herramienta de verificación estándar de datos_1.Descripción general
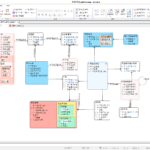
 Macro DA# (2): Función macro DA# (1) - Función común, Entidad Get/Set
Macro DA# (2): Función macro DA# (1) - Función común, Entidad Get/Set
 Macro DA#(1): DA#, API DA#, descripción general de la macro DA#
Macro DA#(1): DA#, API DA#, descripción general de la macro DA#










Esta es una consulta de diccionario estándar en Config relacionada con el repositorio de diccionario estándar.
Base de datos de repositorio: PostgreSQL, base de datos de destino de estandarización: SQL Server
– Consulta de diccionario de palabras estándar
SELECCIONE ROW_NUMBER() SOBRE (ORDENAR POR D.DIC_LOG_NM) COMO NO
,D.DIC_LOG_NM AS “nombre lógico de palabra”
,D.DIC_PHY_NM AS “Nombre de física de palabras”
,D.DIC_PHY_FLL_NM AS “nombre de palabra en inglés”
,D.DIC_DESC AS “Descripción de palabra”
,D.STANDARD_YN AS “Si es estándar”
,(caso D.ATTR_CLSS_YN cuando 'Y' luego 'Y' en caso contrario 'N' END) AS “Si es una palabra de clasificación de atributos”
,CASO
CUANDO D.STANDARD_YN = 'Y' Y SIM.El nombre lógico estándar ES NULO ENTONCES D.DIC_LOG_NM
CUANDO D.STANDARD_YN = 'Y' AND SIM.El nombre lógico estándar NO ES NULO ENTONCES SIM.El nombre lógico estándar
ELSE SIM.Nombre lógico estándar
FIN “Nombre lógico estándar”
,SIM.Sinónimo
,G.DOM_GRP_NM AS “Nombre de clasificación del dominio”
/*
,D.ENT_CLSS_YN AS “¿Palabra de clasificación de entidad o no?
*/
DESDE software de datos.STD_AREA A
, software de datos.STD_DIC D
izquierda combinación externa
(SELECCIONE DM.KEY_DOM_NM
,MAX(DM.DOM_GRP_ID) DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
DESDE software de datos.STD_DOM DM
, software de datos.STD_DOM_GRP DG
WHERE DM.STD_AREA_ID = '¡¡¡Necesita comprobar el valor de la clave!!!'
Y DM.AVAL_END_DT = '99991231235959'
Y DG.STD_AREA_ID = DM.STD_AREA_ID
Y DG.AVAL_END_DT = '99991231235959'
Y DM.DOM_GRP_ID = DG.DOM_GRP_ID
GRUPO POR DM.KEY_DOM_NM) G
en D.DIC_LOG_NM = G.KEY_DOM_NM
izquierda combinación externa
(
— Si es estándar
SELECCIONE A.P_DIC_ID “ID de grupo”
,AP_DIC_ID DIC_ID
,P.DIC_LOG_NM “Nombre lógico estándar”
,STRING_AGG(C.DIC_LOG_NM, ',' ORDER BY A.C_DIC_ID) “Sinónimo”
DESDE software de datos.STD_DIC_REL A
dataware de unión externa izquierda.STD_DIC P
en A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = '99991231235959'
dataware de unión externa izquierda.STD_DIC C
en A.C_DIC_ID = C.DIC_ID y C.AVAL_END_DT = '99991231235959'
DONDE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Diccionario estándar')
Y A.AVAL_END_DT = '99991231235959'
GRUPO POR A.P_DIC_ID, P.DIC_LOG_NM
UNIÓN TODOS
— Si no es estándar
SELECCIONE AA.P_DIC_ID “ID de grupo”
,AC_DIC_ID DIC_ID
,P.DIC_LOG_NM “Nombre lógico estándar”
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ',' ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN '0' ELSE AA.C_DIC_ID END) “Sinónimo”
DESDE software de datos.STD_DIC_REL A
, software de datos.STD_DIC_REL AA
, software de datos.STD_DIC P
, software de datos.STD_DIC C
DONDE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Diccionario estándar')
Y A.AVAL_END_DT = '99991231235959'
Y A.P_DIC_ID = AA.P_DIC_ID
Y AA.P_DIC_ID = P.DIC_ID
Y P.AVAL_END_DT = '99991231235959'
Y AA.C_DIC_ID = C.DIC_ID
Y C.AVAL_END_DT = '99991231235959'
GRUPO POR AA.P_DIC_ID, A.C_DIC_ID, P.DIC_LOG_NM
) Tarjeta SIM
en D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = 'Diccionario estándar'
Y A.STD_AREA_ID = D.STD_AREA_ID
Y D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0001' /* '0001': palabra */
/* AND D.STANDARD_YN = Extrae sólo palabras estándar 'Y' */
ORDER BY D.DIC_LOG_NM, (caso D.STANDARD_YN cuando 'Y' y luego 1 más 2 terminan)
;
–Consulta del diccionario de terminología estándar
SELECCIONE ROW_NUMBER() SOBRE (ORDENAR POR D.DIC_LOG_NM) COMO NO
,D.DIC_LOG_NM AS “Nombre lógico del término”
,
(
SELECCIONE STRING_AGG(X.DIC_LOG_NM, '_')
DE
(
SELECCIONE WRD.DIC_LOG_NM
DESDE STD_DIC COMO WRD
UNIÓN EXTERNA IZQUIERDA STD_WORD_COMBI AS C
EN WRD.STD_AREA_ID = C.STD_AREA_ID
Y WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Diccionario estándar')
Y C.TERM_ID = D.DIC_ID
Y C.AVAL_END_DT = '99991231235959'
PEDIDO POR C.ORDER_NO
) COMO
) COMO “Combinación de nombres lógicos de palabras”
,D.DIC_PHY_NM AS “Nombre de física del término”
,D.DIC_DESC AS “Glosario”
,DM.DOM_NM AS “Nombre lógico de dominio”
,UPPER(DT.DATA_TYPE) COMO “tipo de datos”
— ,DM.DATA_LEN COMO “Longitud”
,(caso en que DM.DATA_LEN = -1 y luego 'MAX' en caso contrario text(DM.DATA_LEN) END) AS “Longitud”
,DM.DATA_SCALE AS “grado”
”, como “Definición de trabajo”
, SUPERIOR (DT.DATA_TYPE)
||caso
cuando DM.DATA_LEN es nulo y UPPER(DT.DATA_TYPE) no está en ('INT', 'DATETIME2'), entonces nulo
cuando DM.DATA_LEN es nulo y UPPER(DT.DATA_TYPE) en ('INT', 'DATETIME2') entonces "
CUANDO DM.DATA_LEN = -1 Y DM.DATA_SCALE ES NULL y SUPERIOR (DT.DATA_TYPE) en ('VARCHAR', 'VARBINARY') ENTONCES '(MAX'
más '('||DM.DATA_LEN
fin
||CASO CUANDO DM.DATA_LEN NO ES NULO Y DM.DATA_SCALE ES NULO ENTONCES ')'
CUANDO DM.DATA_LEN NO ES NULO y DM.DATA_LEN > 0 Y DM.DATA_SCALE NO ES NULO ENTONCES ','||DM.DATA_SCALE||')'
CUANDO DM.DATA_LEN ES NULO Y DM.DATA_SCALE ES NULO y SUPERIOR (DT.DATA_TYPE) en ('INT', 'DATETIME2') ENTONCES "
ELSE FINAL NULO
COMO “Tamaño de tipo”
DESDE software de datos.STD_AREA A
, software de datos.STD_DIC D
, software de datos.STD_DOM DM
, software de datos.STD_DATATYPE DT
WHERE A.STD_AREA_NM = 'Diccionario estándar'
Y A.STD_AREA_ID = D.STD_AREA_ID
Y D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0002' /* '0002': término */
AND D.STANDARD_YN = 'Y' /* Extraer solo términos estándar */
Y DM.STD_AREA_ID = D.STD_AREA_ID
Y DM.AVAL_END_DT = '99991231235959'
Y DM.DOM_ID = D.DOM_ID
Y DT.DB_TYPE = '0006' –SERVIDOR SQL
Y DT.CD_NO = DM.DATA_TYPE_CD
;
–Consulta de diccionario de dominio estándar
SELECCIONE ROW_NUMBER() SOBRE (ORDENAR POR DG.DOM_GRP_NM, DM.DOM_NM) COMO NO
,DG.DOM_GRP_NM AS “Nombre de clasificación del dominio”
,DM.DOM_NM AS “Nombre lógico de dominio”
,DM.KEY_DOM_PHY_NM AS “Nombre físico del dominio clave”
,(caso DM.DOM_DESC cuando es nulo y luego DM.KEY_DOM_NM en caso contrario DM.DOM_DESC END) COMO “Descripción del dominio”
,UPPER(DT.DATA_TYPE) AS “Nombre del tipo de datos”
,(caso en que DM.DATA_LEN = -1 y luego 'MAX' en caso contrario text(DM.DATA_LEN) END) AS “Longitud”
,DM.DATA_SCALE AS “grado”
, SUPERIOR (DT.DATA_TYPE)
||caso
cuando DM.DATA_LEN es nulo y UPPER(DT.DATA_TYPE) no está en ('INT', 'DATETIME2'), entonces nulo
cuando DM.DATA_LEN es nulo y UPPER(DT.DATA_TYPE) en ('INT', 'DATETIME2') entonces "
CUANDO DM.DATA_LEN = -1 Y DM.DATA_SCALE ES NULL y SUPERIOR (DT.DATA_TYPE) en ('VARCHAR', 'VARBINARY') ENTONCES '(MAX'
más '('||DM.DATA_LEN
fin
||CASO CUANDO DM.DATA_LEN NO ES NULO Y DM.DATA_SCALE ES NULO ENTONCES ')'
CUANDO DM.DATA_LEN NO ES NULO y DM.DATA_LEN > 0 Y DM.DATA_SCALE NO ES NULO ENTONCES ','||DM.DATA_SCALE||')'
CUANDO DM.DATA_LEN ES NULO Y DM.DATA_SCALE ES NULO y SUPERIOR (DT.DATA_TYPE) en ('INT', 'DATETIME2') ENTONCES "
ELSE FINAL NULO
COMO “Tamaño de tipo”
/*
,DM.KEY_DOM_NM AS “Nombre de dominio clave”
*/
DESDE software de datos.STD_DOM DM
, software de datos.STD_DOM_GRP DG
, software de datos.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Diccionario estándar')
Y DM.AVAL_END_DT = '99991231235959'
Y DG.STD_AREA_ID = DM.STD_AREA_ID
Y DG.AVAL_END_DT = '99991231235959'
Y DG.DOM_GRP_ID = DM.DOM_GRP_ID
Y DT.DB_TYPE = '0006'
Y DT.CD_NO = DM.DATA_TYPE_CD
;
Gracias por compartir el SQL de búsqueda de diccionario estándar.
También lo usaré cuando use la versión PostgreSQL.
La sangría de los espacios no se muestra en los comentarios.
Encontremos una manera.
Al verificar el estándar, si el nombre de la propiedad (NÚMERO DE CLIENTE) se combina solo con palabras en inglés, hay un síntoma de que la combinación de palabras estándar y la coincidencia en inglés estándar no se pueden verificar incluso si el término estándar está registrado. Me pregunto si tiene algo que ver con la lógica que trata a los delimitadores como guiones bajos y espacios.
EX)
*Palabras estándar, abreviaturas
CLIENTES, CLIENTES
NÚMERO, NO
*Término estándar, dominio
NÚMERO DE CLIENTE, NÚMERO V10
*Dominio estándar, tipo de datos
NÚMERO V10, VARCHAR(10)
https://prodskill.com/ko/data-standard-checker-4-case-study/#33_%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80_%EC%98%88%EC%8B%9C_Case_2_%ED%91%9C%EC%A4%80%EB%8B%A8%EC%96%B4_%EC%A1%B0%ED%95%A9
Este artículo contiene lo siguiente:
—————————————————————
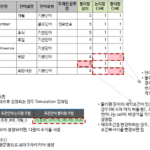
El atributo “Personal o no” (Fila# 9) contiene un espacio. El hecho de que "[Asunto personal]_Si" se muestra en la sección "Combinación de nombres lógicos de palabras estándar" significa que "[Asunto personal]" no está en el diccionario estándar y "si" está en el diccionario estándar. Esta celda también contiene caracteres no registrados, por lo que el color de fondo se establece en rojo. Si se incluye un delimitador en el nombre de la propiedad, "(Especificado por el usuario)" se muestra en el elemento "Resultado de la verificación del nombre de la propiedad".
—————————————————————
Los caracteres de espacio en los nombres de atributos sujetos a inspección estándar se utilizan intencionalmente para separar palabras.
Con la función implementada actualmente, si se permite un espacio en el nombre lógico de un término estándar, no se verifica la coincidencia según el término estándar.
Parece que la inspección deseada se puede realizar creando una opción para seleccionar si se deben tratar los espacios ingresados en el nombre de la propiedad para ser inspeccionados como "delimitadores de palabras previstos" o como "caracteres de espacio" en sí mismos.
¿Lo necesitas? ^^
En el caso de modelar en inglés, es difícil identificar palabras si el nombre de la propiedad se adjunta como una palabra coreana, por lo que si necesita separar las palabras en inglés con un espacio, necesitará una opción. ^^;;
https://github.com/DAToolset/ToolsForDataStandard/raw/main/%EC%86%8D%EC%84%B1%20%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80%20%EB%8F%84%EA%B5%AC_v1.36_20230426_1.xlsm
En la versión 1.36, los caracteres de espacio en los nombres de atributos sujetos a inspección estándar se cambiaron para que no se traten como separadores de palabras.
En consecuencia, las reglas para escribir nombres de atributos sujetos a inspección también han cambiado de la siguiente manera.
※ Reglas para escribir nombres de atributos
1. Ingresa sin espacios entre palabras: Básico
– Ejemplo: si el trabajo se ejecuta automáticamente o no
2. Ingrese espacios entre palabras: Al escribir el nombre lógico del atributo en inglés
– Ejemplo: NÚMERO DE CLIENTE
3. Ingrese separado por “_”: Al especificar la composición de palabras
– Ejemplo: si se debe ejecutar la tarea automáticamente
Por favor pruébalo y da tu opinión.
Nombre del atributo: NÚMERO DE DIVISIÓN DEL CLIENTE
Al realizar una verificación estándar, los resultados de la verificación del nombre del atributo se muestran como una combinación de palabras estándar, pero los resultados de la combinación de nombre lógico de palabra estándar y la combinación de nombre físico se procesan incorrectamente.
CLIENTE, DIVISIÓN, NÚMERO: 3 palabras estándar registradas
Combinación de nombre lógico de palabra estándar: CLIENTE_[ ]_SPLIT_[ ]_NUMBER
Combinación de palabras estándar y nombres físicos: CUST_[ ]_SPLT_[ ]_NO
Lo vi demasiado brevemente ^^;;
Lo probaré un poco más y lo implementaré nuevamente.
v1.36 relanzado.
https://prodskill.com/ko/data-standard-checker-v1-36/
Base de datos de repositorio: PostgreSQL, base de datos de destino de estandarización: PostgreSQL
SELECCIONE ROW_NUMBER() SOBRE (ORDENAR POR D.DIC_LOG_NM) COMO NO
,D.DIC_LOG_NM AS “nombre lógico de palabra”
,D.DIC_PHY_NM AS “Nombre de física de palabras”
,D.DIC_PHY_FLL_NM AS “nombre de palabra en inglés”
,D.DIC_DESC AS “Descripción de palabra”
,D.STANDARD_YN AS “Si es estándar”
,(caso D.ATTR_CLSS_YN cuando 'Y' luego 'Y' en caso contrario 'N' END) AS “Si es una palabra de clasificación de atributos”
,CASO
CUANDO D.STANDARD_YN = 'Y' Y SIM.El nombre lógico estándar ES NULO ENTONCES D.DIC_LOG_NM
CUANDO D.STANDARD_YN = 'Y' AND SIM.El nombre lógico estándar NO ES NULO ENTONCES SIM.El nombre lógico estándar
ELSE SIM.Nombre lógico estándar
FIN “Nombre lógico estándar”
,SIM.Sinónimo
,G.KEY_DOM_NM AS “Nombre de clasificación de dominio”
/*
,D.ENT_CLSS_YN AS “¿Palabra de clasificación de entidad o no?
*/
DESDE software de datos.STD_AREA A
, software de datos.STD_DIC D
izquierda combinación externa
(SELECCIONE DM.KEY_DOM_NM
,MAX(DM.DOM_GRP_ID) DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
DESDE software de datos.STD_DOM DM
, software de datos.STD_DOM_GRP DG
DONDE DM.STD_AREA_ID = '47430eed-15a9-4697-90e3-a70040266517'
Y DM.AVAL_END_DT = '99991231235959'
Y DG.STD_AREA_ID = DM.STD_AREA_ID
Y DG.AVAL_END_DT = '99991231235959'
Y DM.DOM_GRP_ID = DG.DOM_GRP_ID
GRUPO POR DM.KEY_DOM_NM) G
en D.DIC_LOG_NM = G.KEY_DOM_NM
izquierda combinación externa
(
–Si es estándar
SELECCIONE A.P_DIC_ID “ID de grupo”
,AP_DIC_ID DIC_ID
,P.DIC_LOG_NM “Nombre lógico estándar”
,STRING_AGG(C.DIC_LOG_NM, ',' ORDER BY A.C_DIC_ID) “Sinónimo”
DESDE software de datos.STD_DIC_REL A
dataware de unión externa izquierda.STD_DIC P
en A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = '99991231235959'
dataware de unión externa izquierda.STD_DIC C
en A.C_DIC_ID = C.DIC_ID y C.AVAL_END_DT = '99991231235959'
DONDE 1=1
AND A.P_STD_AREA_ID = (SELECCIONE STD_AREA_ID DE DATAWARE.STD_AREA DONDE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Diccionario estándar')
Y A.AVAL_END_DT = '99991231235959'
GRUPO POR A.P_DIC_ID, P.DIC_LOG_NM
UNIÓN TODOS
–En caso de no estándar
SELECCIONE AA.P_DIC_ID “ID de grupo”
,AC_DIC_ID DIC_ID
,P.DIC_LOG_NM “Nombre lógico estándar”
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ',' ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN '0' ELSE AA.C_DIC_ID END) “Sinónimo”
DESDE software de datos.STD_DIC_REL A
, software de datos.STD_DIC_REL AA
, software de datos.STD_DIC P
, software de datos.STD_DIC C
DONDE 1=1
AND A.P_STD_AREA_ID = (SELECCIONE STD_AREA_ID DE DATAWARE.STD_AREA DONDE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Diccionario estándar')
Y A.AVAL_END_DT = '99991231235959'
Y A.P_DIC_ID = AA.P_DIC_ID
Y AA.P_DIC_ID = P.DIC_ID
Y P.AVAL_END_DT = '99991231235959'
Y AA.C_DIC_ID = C.DIC_ID
Y C.AVAL_END_DT = '99991231235959'
GRUPO POR AA.P_DIC_ID, A.C_DIC_ID, P.DIC_LOG_NM
) Tarjeta SIM
en D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = '0.Diccionario estándar'
Y A.STD_AREA_ID = D.STD_AREA_ID
Y D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0001' /* '0001': palabra */
/* AND D.STANDARD_YN = Extrae sólo palabras estándar 'Y' */
ORDER BY D.DIC_LOG_NM, (caso D.STANDARD_YN cuando 'Y' y luego 1 más 2 terminan)
;
–Consulta del diccionario de terminología estándar
SELECCIONE ROW_NUMBER() SOBRE (ORDENAR POR D.DIC_LOG_NM) COMO NO
,D.DIC_LOG_NM AS “Nombre lógico del término”
,
(
SELECCIONE STRING_AGG(X.DIC_LOG_NM, '_')
DE
(
SELECCIONE WRD.DIC_LOG_NM
DESDE STD_DIC COMO WRD
UNIÓN EXTERNA IZQUIERDA STD_WORD_COMBI AS C
EN WRD.STD_AREA_ID = C.STD_AREA_ID
Y WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECCIONE STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Diccionario estándar')
Y C.TERM_ID = D.DIC_ID
Y C.AVAL_END_DT = '99991231235959'
Y WRD.AVAL_END_DT = '99991231235959'
PEDIDO POR C.ORDER_NO
) COMO
) COMO “Combinación de nombres lógicos de palabras”
,D.DIC_PHY_NM AS “Nombre de física del término”
,D.DIC_DESC AS “Glosario”
,DM.DOM_NM AS “Nombre lógico de dominio”
,UPPER(DT.DATA_TYPE) COMO “tipo de datos”
— ,DM.DATA_LEN COMO “Longitud”
,(caso en que DM.DATA_LEN = -1 y luego 'MAX' en caso contrario text(DM.DATA_LEN) END) AS “Longitud”
,DM.DATA_SCALE AS “grado”
”, como “Definición de trabajo”
, reemplazar(
SUPERIOR(DT.DATA_TYPE)
||'(''
|| caso en el que DM.DATA_LEN es nulo, entonces "de lo contrario se emite (DM.DATA_LEN como texto) fin
|| caso cuando DM.DATA_SCALE es nulo, entonces "de lo contrario, finaliza (DM.DATA_SCALE como texto)
||')'’
, '()', ”) COMO “Tamaño de tipo”
DESDE software de datos.STD_AREA A
, software de datos.STD_DIC D
, software de datos.STD_DOM DM
, software de datos.STD_DATATYPE DT
WHERE A.STD_AREA_NM = '0.Diccionario estándar'
Y A.STD_AREA_ID = D.STD_AREA_ID
Y D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0002' /* '0002': término */
AND D.STANDARD_YN = 'Y' /* Extraer solo términos estándar */
Y DM.STD_AREA_ID = D.STD_AREA_ID
Y DM.AVAL_END_DT = '99991231235959'
Y DM.DOM_ID = D.DOM_ID
Y DT.DB_TYPE = '0024'
Y DT.CD_NO = DM.DATA_TYPE_CD
;
–Consulta de diccionario de dominio estándar
SELECCIONE ROW_NUMBER() SOBRE (ORDENAR POR DG.DOM_GRP_NM, DM.DOM_NM) COMO NO
,DM.key_dom_nm AS “Nombre de clasificación de dominio”
,DM.DOM_NM AS “Nombre lógico de dominio”
,DM.KEY_DOM_PHY_NM AS “Nombre físico del dominio clave”
,(caso DM.DOM_DESC cuando es nulo y luego DM.KEY_DOM_NM en caso contrario DM.DOM_DESC END) COMO “Descripción del dominio”
,UPPER(DT.DATA_TYPE) AS “Nombre del tipo de datos”
,DM.DATA_LEN COMO “Longitud”
,DM.DATA_SCALE AS “grado”
, reemplazar(
SUPERIOR(DT.DATA_TYPE)
||'(''
|| caso en el que DM.DATA_LEN es nulo, entonces "de lo contrario se emite (DM.DATA_LEN como texto) fin
|| caso cuando DM.DATA_SCALE es nulo, entonces "de lo contrario, finaliza (DM.DATA_SCALE como texto)
||')'’
, '()', ”) COMO “Tamaño de tipo”
, dg.dom_grp_nm como “nombre de grupo de dominio estándar”
/*
,DM.KEY_DOM_NM AS “Nombre de dominio clave”
*/
DESDE software de datos.STD_DOM DM
, software de datos.STD_DOM_GRP DG
, software de datos.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECCIONE STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Diccionario estándar')
Y DM.AVAL_END_DT = '99991231235959'
Y DG.STD_AREA_ID = DM.STD_AREA_ID
Y DG.AVAL_END_DT = '99991231235959'
Y DG.DOM_GRP_ID = DM.DOM_GRP_ID
Y DT.DB_TYPE = '0024'
Y DT.CD_NO = DM.DATA_TYPE_CD
;
Gracias por compartir.