단어 추출 도구(1): 단어 추출 도구 개요
데이터 표준화 작업, 특히 표준 단어 후보군 작성에 유용하게 활용할 수 있는 단어 추출 도구 개요 를 살펴본다.
1. 단어 추출 도구 개요
1.1. 단어 추출 도구를 개발한 이유
데이터 표준화 초기 작업 중 가장 어려운 작업은 표준 단어로 등록할 후보군을 가능한 많이, 그리고 빨리 수집하는 작업이다. 데이터 표준점검 도구(참조: 데이터 표준점검 도구_1.개요)를 표준 단어 후보군을 추출하는데 활용할 수 있으나, 다음의 어려움이 있다.
- Database table, column comment 자료에 특수문자(#, $, %, ., \ 등의 기호와 행분리 문자 등)가 많이 포함되어 있는 경우 이를 제거하거나 정제하는 노력이 상당히 필요함
- 단어의 빈도수를 알기 어려워서 단일 단어로만 등록할지, 복합어로만 등록할지, 또는 단일 단어와 복합어 모두 등록할지에 대한 판단이 어려움
- 표준 단어가 확정된 이후 나중에 복합어가 식별되어 이미 등록되어 있는 표준 용어의 물리명에 영향을 미치는 경우 표준 명명규칙에 예외가 생겨 관리가 어려워 질 수 있음
단어 추출 도구는 이런 어려움을 조금이나마 해소하고자 개발하였다. 특히 다음과 같은 경우에 도움이 될 것으로 기대한다.
- 현행 데이터 표준 사전이 없거나 있더라도 표준단어의 개수가 적은 경우
- 업무가 매우 독특하여 참조하기에 적합한 데이터 표준 사전이 없는 경우
- Database table, column comment가 너무 방대하여 수작업으로 단어를 추출하는 데 많은 시간이 걸리는 경우
- 또는 그 반대로 Database table, column comment에 내용이 거의 없어서 표준 단어를 추출하기에 부적하고 업무 매뉴얼 등의 문서에서 추출하는 것이 적합한 경우
- 그 외, 문서로부터 단어와 빈도 추출이 필요한 경우
1.2. 단어 추출 도구 개념
단어 추출 도구는 여러 형식의 파일을 입력으로 받아서 자연어 처리 형태소 분석기를 이용하여 단어, 복합어를 추출하고 그 빈도와 출처(파일명, table명, column명 등)를 엑셀파일로 출력하는 도구이다.
한국어 자연어 처리(NLP, Natural Language Processing) 형태소 분석기인 Mecab을 사용하고, Python v3.8에서 개발하였다. 한국어 자연어 처리 형태소 분석기중 공개된 library는 Kkma, Komoran, Hannanum, Okt(예전 명칭 Twitter), Mecab이 대표적이다. 이 중에서 Mecab을 선택한 이유는 성능이 가장 좋기 때문이다.
자연어 처리 형태소 분석기들의 성능 비교는 아래 Link에서 확인할 수 있다.
참조: https://konlpy.org/ko/latest/morph/#comparison-between-pos-tagging-classes
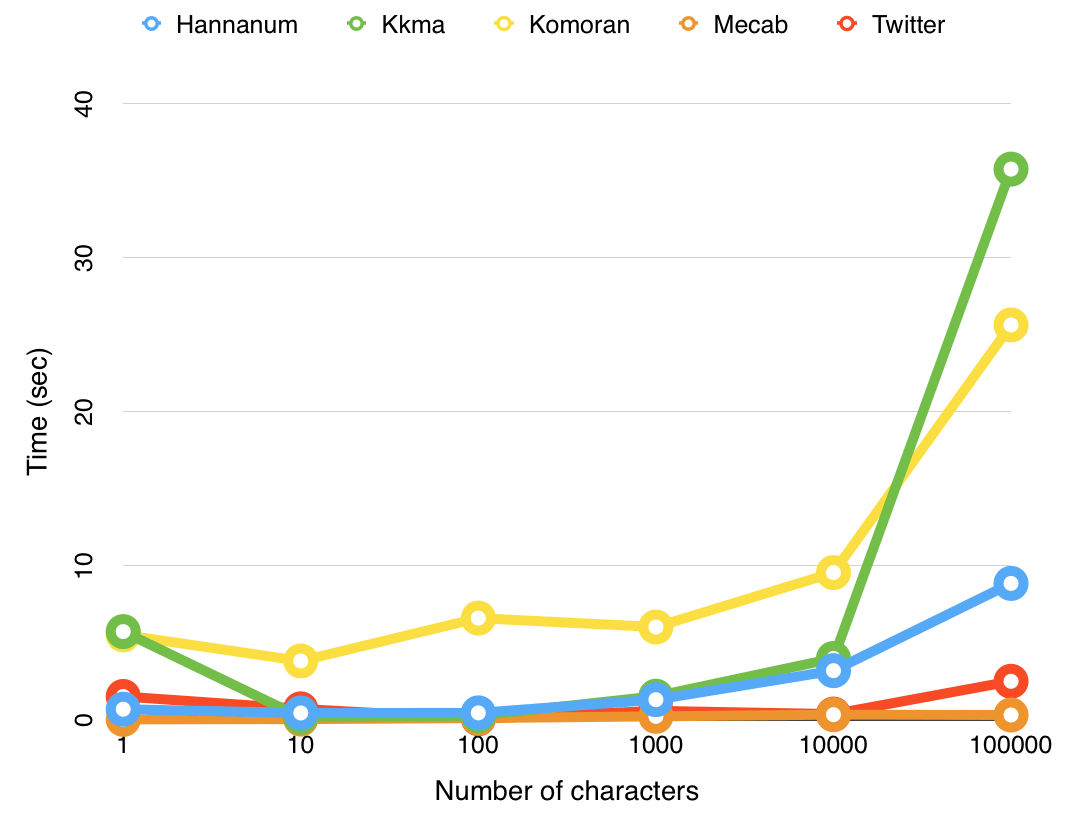
입력 문자수 증가에 따른 실행 시간은 다음과 같이 정리할 수 있다. (좌에서 우로 갈수록 실행시간이 단축되고 성능이 좋아짐)
Kkma > Komoran > Hannanum > Okt(Twitter) > Mecab
참고로, 위 Link는 KoNLPy package를 개발한 분의 사이트이다. KoNLPy는 Python 기반으로 여러 형태소 분석기를 하나로 묶어서 제공하는 package이다.
KoNLPy: https://konlpy.org/ko/latest/
1.3. 단어 추출 도구 동작 방식
입력 자료, 처리 로직, 출력 자료에 대해 간략히 살펴본다.
1.3.1. 단어 추출 도구 입력 자료
입력 자료는 다음 두 가지 중 하나이거나 둘 다 지정할 수 있다.
- 문서 자료: MS Word, PowerPoint, Text 파일
- 이 글을 작성하는 현재 시점(2021-08-29)에는 HWP, PDF 형식은 아직 지원하지 않는다.
- DB Table, Column comment 자료: Excel 파일
- Table comment 자료 항목: Database, Schema, Table Name, Table Comment
- Column comment 자료 항목: Database, Schema, Table Name, Table Comment, Column Name, Column Comment
▼ Table comment 자료의 예시는 다음과 같다.
| Database | Schema | Table Name | Table Comment |
| DB1 | OWNER1 | COMTCADMINISTCODE | 행정코드 |
| DB1 | OWNER1 | COMTCADMINISTCODERECPTNLOG | 행정코드수신로그 |
| DB1 | OWNER1 | COMTCCMMNCLCODE | 공통분류코드 |
| DB1 | OWNER1 | COMTCCMMNCODE | 공통코드 |
| DB1 | OWNER1 | COMTCCMMNDETAILCODE | 공통상세코드 |
▼ Column comment 자료의 예시는 다음과 같다. 위 Table 목록 중 COMTCADMINISTCODE(행정코드)의 column 목록이다.
| Database | Schema | Table Name | Column Name | Column Comment |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE | 행정구역구분 |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE | 행정구역코드 |
| DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT | 사용여부 |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM | 행정구역명 |
| DB1 | OWNER1 | COMTCADMINISTCODE | UPPER_ADMINIST_ZONE_CODE | 상위행정구역코드 |
| DB1 | OWNER1 | COMTCADMINISTCODE | CREAT_DE | 생성일 |
| DB1 | OWNER1 | COMTCADMINISTCODE | ABL_DE | 폐지일 |
| DB1 | OWNER1 | COMTCADMINISTCODE | FRST_REGIST_PNTTM | 최초등록시점 |
| DB1 | OWNER1 | COMTCADMINISTCODE | FRST_REGISTER_ID | 최초등록자ID |
| DB1 | OWNER1 | COMTCADMINISTCODE | LAST_UPDT_PNTTM | 최종수정시점 |
| DB1 | OWNER1 | COMTCADMINISTCODE | LAST_UPDUSR_ID | 최종수정자ID |
* 위 예시 자료는 전자정부 표준프레임워크 v3.8의 “공통컴포넌트 테이블 구성 정보” 페이지에서 table, column comment script를 활용하여 작성하였다.
(출처: https://www.egovframe.go.kr/wiki/doku.php?id=egovframework:com:v3.8:init_table)
1.3.2. 단어 추출 도구 처리 로직
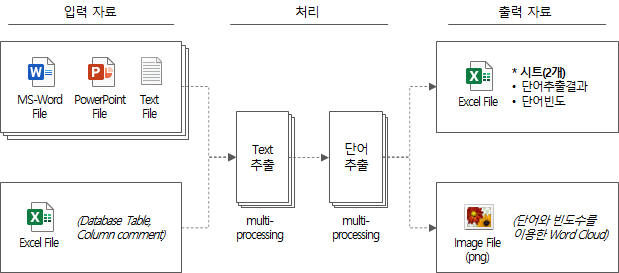
전체 처리 로직을 간략하게 요약하면 다음과 같다.
- 입력 자료를 차례로 열어서 텍스트(행단위, table/column 단위) 추출
- 자연어 형태소 분석기 package인 Mecab을 이용하여 명사1개, 명사n개, 접두사+명사n개, 명사n개+접미사, 접두사+명사n개+접미사의 형태인 단어 후보군 추출
- 전체 입력자료에서 추출한 단어의 빈도를 구하고, 단어 추출결과를 출력 파일로 저장
- 단어 목록과 빈도로 word cloud를 png 파일로 생성하여 저장
- 전체 소요시간을 출력하고 종료
위 처리 과정을 간략하게 도식화하면 다음과 같다.
1.3.3. 단어 추출 도구 출력 자료
입력 자료를 처리한 결과인 출력 자료는 Excel 파일과 Word cloud 형태의 이미지(png) 파일 두 개이다.
Excel 파일은 두 개의 시트로 구성되어 있다. 아래는 DB Table, Column comment 자료를 입력으로 한 경우 예시이다.
▼ “단어추출결과” 시트 예시
| No | Word | FileName | FileType | Page | Text | DB | Schema | Table | Column |
| 1 | 행정 | table,column comments.xlsx | column | 0 | 행정구역구분 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 2 | 구역 | table,column comments.xlsx | column | 0 | 행정구역구분 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 3 | 구분 | table,column comments.xlsx | column | 0 | 행정구역구분 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 4 | 행정구역구분[복합어] | table,column comments.xlsx | column | 0 | 행정구역구분 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 5 | 행정 | table,column comments.xlsx | column | 0 | 행정구역코드 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 6 | 구역 | table,column comments.xlsx | column | 0 | 행정구역코드 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 7 | 코드 | table,column comments.xlsx | column | 0 | 행정구역코드 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 8 | 행정구역코드[복합어] | table,column comments.xlsx | column | 0 | 행정구역코드 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 9 | 사용 | table,column comments.xlsx | column | 0 | 사용여부 | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 10 | 여부 | table,column comments.xlsx | column | 0 | 사용여부 | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 11 | 사용여부[복합어] | table,column comments.xlsx | column | 0 | 사용여부 | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 12 | 행정구 | table,column comments.xlsx | column | 0 | 행정구역명 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 13 | 역명 | table,column comments.xlsx | column | 0 | 행정구역명 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 14 | 행정구역명[복합어] | table,column comments.xlsx | column | 0 | 행정구역명 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
- “Text”열: 입력 자료에서 추출한 원본 값이고 이 예시의 경우 table, column comment에 해당한다.
- “Word”열: Text에서 Mecab을 사용하여 추출한 단어 후보이다. 복합어는 suffix로 “[복합어]”를 지정한다.
- 12행 “행정구”, 13행 “역명”은 Mecab에서 “행정구역명”으로부터 추출한 단어이다.
- 실제 사용하는 단어와는 다르게 추출되어 정확도가 100%는 아닌 것을 알 수 있다.
▼ “단어빈도” 시트 예시
| 단어 | Freq | Source |
| 코드 | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(행정구역코드) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(변경구분코드) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(시도코드) … |
| 번호 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(작업일련번호) DB1.OWNER1.COMTCZIP.ZIP(우편번호) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(승인번호) … |
| 명 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(주소록명) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(분류코드명) DB1.OWNER1.COMTCCMMNDETAILCODE.CODE_NM(코드명) … |
| 일 | 85 | DB1.OWNER1.COMTCADMINISTCODE.CREAT_DE(생성일) DB1.OWNER1.COMTCADMINISTCODE.ABL_DE(폐지일) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OCCRRNC_DE(발생일) … |
| 정보 | 77 | DB1.OWNER1.COMTHDBMNTRNGLOGINFO.LOG_INFO(로그정보) DB1.OWNER1.COMTNBACKUPRESULT.ERROR_INFO(오류정보) DB1.OWNER1.COMTNINDVDLINFOPOLICY.INDVDL_INFO_POLICY_ID(개인정보정책ID) … |
| 여부 | 75 | DB1.OWNER1.COMTCADMINISTCODE.USE_AT(사용여부) DB1.OWNER1.COMTNANNVRSRYMANAGE.REPTIT_AT(반복여부) DB1.OWNER1.COMTNBANNER.REFLCT_AT(반영여부) … |
- “단어”열: “단어추출결과” 시트의 “Word’열을 중복제거한 문자열값이다. 이 값이 표준 단어로 등록할 후보이다.
- “Freq”열: 단어가 몇 번 사용되었는지 나타내는 빈도수이다. 결과 목록은 이 빈도수가 높은 단어로부터 낮은 단어로 역순 정렬되어 있다.
- “Source”열: 해당 단어의 출처를 나타낸다. 최대 10개의 출처를 표시한다.
- 출처가 Table인 경우 형식: DB.Schema.TableName(Table comment)
- 출처가 Column인 경우 형식: DB.Schema.TableName.ColumnName(Column comment)
- 출처가 File인 경우 형식: 파일명:페이지번호:Text
추출 단어의 빈도수로 생성한 Word cloud 이미지 예시는 다음과 같다. 빈도수가 많은 단어가 크게 표시된다.

단어 추출 도구는 Python으로 개발된 도구이고, 실행에 앞서 Python과 필요한 package 설치 등의 환경 구성 과정이 필요하다. 다음에는 환경 구성 과정에 대해 살펴보겠다.
<< 관련 글 목록 >>

















