단어 추출 도구(6): 단어 추출 도구 부가 설명
이전 글에 이어 단어 추출 도구 부가 설명 에 대해 살펴본다.
단어 추출 도구(5): 단어 추출 도구 소스코드 설명(2)
5. 단어 추출 도구 부가 설명
5.1. OLE Automation을 사용하는 이유
OLE Aumation은 위키백과에 다음과 같이 정의되어 있다.
마이크로소프트 윈도우 애플리케이션 프로그래밍에서 OLE 자동화(OLE Automation, 나중에는 간단히 자동화로 이름이 변경됨[1][2])는 마이크로소프트가 개발한 프로세스 간 통신(IPC) 매커니즘이다. 컴포넌트 오브젝트 모델(COM)의 하위 집합에 기반을 두며, 스크립트 언어(원래는 비주얼 베이직)를 통해 사용되도록 고안되었으나 지금은 윈도우에서 여러 언어를 통해 사용할 수 있다.
출처: https://ko.wikipedia.org/wiki/OLE_자동화
Python에서는 win32com package를 이용하여 OLE Automation이 가능하다. MS-Office 응용 프로그램을 제어하여 원하는 기능을 수행할 수 있다.
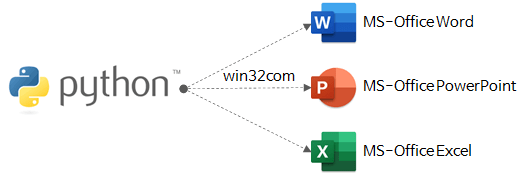
단어 추출 도구에는 다음과 같은 이유로 OLE Aumation을 사용했다.
- MS-Word, PowerPoint를 읽고 쓸 수 있는 다음과 같은 전용 package가 있으나 일부러 사용하지 않았다.
- MS-Word: python-docx, python-docx2txt
- PowerPoint: python-pptx
- Excel: openpyxl, xlsxwriter, pyxlsb
- 대부분의 기업 환경은 DRM 소프트웨어 설치를 강제하고 있어 문서 파일들은 암호화 된다.
- 전용 package를 사용하면 암호화된 파일을 읽을 수 없다.
- pywin32 package로 OLE Automation 방법을 사용하면 Office 프로그램을 통하여 파일을 읽을 수 있다.
- OLE Automation을 사용하면 성능은 조금 손해볼 수 있으나, 결과를 보장할 수 있다.
MS-Word, PowerPoint, Excel을 제어하는 Python 코드는 다음 글을 참고하기 바란다.
- MS-Word Automation: 4.3.1. get_doc_text 함수
- PowerPoint Automation: 4.3.2._get_ppt_text_함수
- Excel Automation: 4.3.4._get_db_comment_text_함수
5.2. Text 파일 인코딩 관련 (UTF-8만 지원함)
- 입력 text file의 encoding은 UTF-8만 지원하도록 되어 있다.
- 만약 입력 파일 중 text 파일이 ANSI encoding이라면 cp949이고 non-Unicode encoding이므로 다음과 같은 오류가 발생할 것이다.
- UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb4 in position 5: invalid start byte
- 실행시 이와 비슷한 오류가 발생한다면 text 파일을 UTF-8로 저장하고 재실행한다.
5.3. multi processing 사용 이유
이전 글 “단어 추출 도구(4): 단어 추출 도구 소스코드 설명(1)“에서 multi processing을 사용한 코드를 설명했다.
4.2.3. Multi processing으로 get_file_text 실행
4.2.4. Multi processing으로 get_word_list 실행
처음 이 도구를 만들었을 때는 텍스트 추출과 단어 추출 모두 single processing이었다. 2021년 초 K사 프로젝트에서 처음 사용했을 때 약 16만개 column comment에서 표준 단어 후보군을 추출하는 작업을 노트북(CPU i5, 16GB Ram)으로 실행했을 때, 약 20시간이 걸렸다.
테스트를 포함하여 여러 번 반복실행하다 보니, 실행시간을 단축할 필요가 생겼다. 병렬처리를 위해 Thread를 사용하려고 구글링을 해보니 Python에서는 GIL(Global Interpreter Lock) 개념이 있어서 multi threading 보다는 multi processing이 적합하다고 판단했다.
약간의 코드 수정을 통해 텍스트 추출과 단어 추출 모두 multi processing을 적용했고, 실행시 병렬도를 지정할 수 있는 argument(multi_process_count)도 만들어 두었다.
multi_process_count를 8로 지정하고 실행하니, 20시간 걸리던 작업이 약 40분 정도로 단축되어 충분히 효과가 있었다.
5.4. 복합어 추출 관련 참고사항
Mecab의 주요 함수중 nouns, pos, morphs에 대한 설명은 다음과 같다.
| 함수 | 설명 |
| nouns(text) | text를 구문분석하고 명사(noun)만 추출하여 list 반환 |
| pos(text) | text를 구문분석하고 (형태소, 품사Tag) 형태의 list 반환 |
| morphs(text) | text를 구문분석하고 형태소만 추출하여 list 반환 |
각 함수의 실행결과는 아래 입력 문자열에 대한 예시와 같다.
* 입력 문자열: 사용자는 기능적 요구사항과 비기능적 요구사항을 정의한다.
| 함수 | 실행결과 |
| nouns(text) | [‘사용’, ‘기능’, ‘요구’, ‘사항’, ‘기능’, ‘요구’, ‘사항’, ‘정의’] |
| pos(text) | [(‘사용’, ‘NNG’), (‘자’, ‘XSN’), (‘는’, ‘JX’), (‘기능’, ‘NNG’), (‘적’, ‘XSN’), (‘요구’, ‘NNG’), (‘사항’, ‘NNG’), (‘과’, ‘JC’), (‘비’, ‘XPN’), (‘기능’, ‘NNG’), (‘적’, ‘XSN’), (‘요구’, ‘NNG’), (‘사항’, ‘NNG’), (‘을’, ‘JKO’), (‘정의’, ‘NNG’), (‘한다’, ‘XSV+EF’), (‘.’, ‘SF’)] |
| morphs(text) | [‘사용’, ‘자’, ‘는’, ‘기능’, ‘적’, ‘요구’, ‘사항’, ‘과’, ‘비’, ‘기능’, ‘적’, ‘요구’, ‘사항’, ‘을’, ‘정의’, ‘한다’, ‘.’] |
* 입력 문자열: 데이터 표준화는 데이터 아키텍처 구축의 중요한 영역이다.
| 함수 | 실행결과 |
| nouns(text) | [‘데이터’, ‘표준’, ‘데이터’, ‘아키텍처’, ‘구축’, ‘중요’, ‘영역’] |
| pos(text) | [(‘데이터’, ‘NNG’), (‘표준’, ‘NNG’), (‘화’, ‘XSN’), (‘는’, ‘JX’), (‘데이터’, ‘NNG’), (‘아키텍처’, ‘NNG’), (‘구축’, ‘NNG’), (‘의’, ‘JKG’), (‘중요’, ‘NNG’), (‘한’, ‘XSA+ETM’), (‘영역’, ‘NNG’), (‘이’, ‘VCP’), (‘다’, ‘EF’), (‘.’, ‘SF’)] |
| morphs(text) | [‘데이터’, ‘표준’, ‘화’, ‘는’, ‘데이터’, ‘아키텍처’, ‘구축’, ‘의’, ‘중요’, ‘한’, ‘영역’, ‘이’, ‘다’, ‘.’] |
단어 추출 도구는 nouns 함수를 바로 사용하지 않고 pos함수의 결과에 정규 표현식(Regula Expression)을 적용하여 단어를 추출한다. 아래는 정규표현식의 패턴에 대한 설명이다.
정규 표현식 사용 패턴: ‘(NNP/|NNG/)+(XSN/)*|(XPN/)+(NNP/|NNG/)+(XSN/)*|(SL/)+’
- 이 패턴은 다음 세 가지 중 하나를 찾아낸다.
- (NNP/|NNG/)+(XSN/)*: (고유 명사 또는 일반명사) 1개 이상 (필수) + 명사 파생 접미사 0개 이상 (선택적)
- (XPN/)+(NNP/|NNG/)+(XSN/)*: 체언 접두사 1개 이상 (필수)+ (고유 명사 또는 일반명사) 1개 이상 (필수) + 명사 파생 접미사 0개 이상 (선택적)
- (SL/)+: 외국어 1개 이상 (필수)
nouns(text)를 호출하여 명사만 추출하는 경우와 정규표현식을 적용하여 복합어를 추가로 추출하는 경우의 예시는 다음과 같다
* 입력 문자열: 사용자는 기능적 요구사항과 비기능적 요구사항을 정의한다.
| 함수 | 실행결과 |
| 명사만 추출 nouns(text) | 사용, 기능, 요구, 사항, 기능, 요구, 사항, 정의 |
| 정규표현식 적용 | 사용, 기능, 요구, 사항, 기능, 요구, 사항, 정의, 사용자[복합어], 기능적[복합어], 요구사항[복합어], 비기능적[복합어], 요구사항[복합어] |
* 입력 문자열: 데이터 표준화는 데이터 아키텍처 구축의 중요한 영역이다.
| 함수 | 실행결과 |
| 명사만 추출 nouns(text) | 데이터, 표준, 데이터, 아키텍처, 구축, 중요, 영역 |
| 정규표현식 적용 | 데이터, 표준, 데이터, 아키텍처, 구축, 중요, 영역, 데이터표준화[복합어], 데이터아키텍처구축[복합어] |
복합어를 추가로 추출하는 이유는, 표준단어사전 구축 초기에 복합어를 표준으로 등록할지 검토할 수 있도록 하여, 복합어가 나중에 추가되는 경우의 문제를 미리 방지하기 위함이다.
복합어가 나중에 추가되면 해당 복합어를 구성하는 개별 단어를 사용하는 표준용어의 물리명이 변경될 수 있고, 그 표준용어를 사용하여 이미 데이터베이스의 테이블명과 컬럼명까지 변경해야 할 수 있다.
물론 이미 생성한 표준용어의 물리명은 변경하지 않고, 앞으로 생성할 표준용어의 물리명만 변경하는 방법도 있으나, 표준용어 논리명과 물리명의 일관성 유지를 위하여 이미 생성한 표준용어의 물리명을 변경하는 것이 장기적인 관점에서 권장된다.
이미 생성한 표준용어의 물리명 변경은 쉽게 결정할 문제가 아니다. 개발이 이미 진행된 시점이라면 명칭이 변경된 컬럼을 참조하는 소스코드에 대한 변경까지 진행해야 한다. 추가적인 일정이 필요하고, 여러 이해관계자가 참여하는 프로젝트라면 책임소재를 따지게 될 수도 있다.
변경되는 소스코드의 양이 많다면 프로젝트에 큰 영향을 주게 되어 상당히 곤란해질 수 있다는 점을 감안한다면, 표준사전을 구축하는 초기단계에 복합어 검토는 꼭 필요한 과정이다.
그 영향도를 잘 알면서도 복합어 후보군을 식별할 수 있는 방법이 없었는데, 이 단어 추출 도구가 적합한 방법을 제공한다.
최적은 아닐 수 있어도 현재 시점에 대안으로서는 충분하다고 본다.
5.5. 형태소 분석기 품사 종류
이전 글 단어 추출 도구(5): 단어 추출 도구 소스코드 설명(2) 의 4.4._get_word_list_함수 에서 다음 내용이 있었다.
- 64행: pos 함수로 형태소 분석기의 품사 tagging을 실행한다. 품사 tagging과 관련한 내용은 별도로 정리하겠다.
- 품사 tagging 함수 pos는 입력 문자열을 품사 단위로 분해하고 각 단위가 어떤 품사인지 표시(tagging)한 문자열을 반환한다.
- 예를 들어, text가 ‘사용자는 기능적 요구사항과 비기능적 요구사항을 정의한다.’인 경우, pos 함수의 실행결과는 ‘[(‘사용’, ‘NNG’), (‘자’, ‘XSN’), (‘는’, ‘JX’), (‘기능’, ‘NNG’), (‘적’, ‘XSN’), (‘요구’, ‘NNG’), (‘사항’, ‘NNG’), (‘과’, ‘JC’), (‘비’, ‘XPN’), (‘기능’, ‘NNG’), (‘적’, ‘XSN’), (‘요구’, ‘NNG’), (‘사항’, ‘NNG’), (‘을’, ‘JKO’), (‘정의’, ‘NNG’), (‘한다’, ‘XSV+EF’), (‘.’, ‘SF’)]’이다.
- 위 예시에 tagging 된 품사 중 ‘NNG’는 일반 명사, ‘XSN’는 명사 파생 접미사, ‘JX’는 보조사, ‘JC’는 접속 조사, ‘XPN’은 체언 접두사, ‘JKO’는 목적격 조사, ‘XSV+EF’는 동사 파생 접미사+종결 어미, ‘SF’는 마침표/물음표/느낌표를 의미한다.
Mecab에서 제공하는 품사 태그는 다음 문서에 정리되어 있다.
위 문서 내용을 발췌하여 아래에 정리해 둔다.
| 실질의미유무 | 대분류(5언 + 기타) | 세종 품사 태그 | mecab-ko-dic 품사 태그 | ||
| 태그 | 설명 | 태그 | 설명 | ||
| 실질형태소 | 체언 | NNG | 일반 명사 | NNG | 일반 명사 |
| NNP | 고유 명사 | NNP | 고유 명사 | ||
| NNB | 의존 명사 | NNB | 의존 명사 | ||
| NNBC | 단위를 나타내는 명사 | ||||
| NR | 수사 | NR | 수사 | ||
| NP | 대명사 | NP | 대명사 | ||
| 용언 | VV | 동사 | VV | 동사 | |
| VA | 형용사 | VA | 형용사 | ||
| VX | 보조 용언 | VX | 보조 용언 | ||
| VCP | 긍정 지정사 | VCP | 긍정 지정사 | ||
| VCN | 부정 지정사 | VCN | 부정 지정사 | ||
| 수식언 | MM | 관형사 | MM | 관형사 | |
| MAG | 일반 부사 | MAG | 일반 부사 | ||
| MAJ | 접속 부사 | MAJ | 접속 부사 | ||
| 독립언 | IC | 감탄사 | IC | 감탄사 | |
| 형식형태소 | 관계언 | JKS | 주격 조사 | JKS | 주격 조사 |
| JKC | 보격 조사 | JKC | 보격 조사 | ||
| JKG | 관형격 조사 | JKG | 관형격 조사 | ||
| JKO | 목적격 조사 | JKO | 목적격 조사 | ||
| JKB | 부사격 조사 | JKB | 부사격 조사 | ||
| JKV | 호격 조사 | JKV | 호격 조사 | ||
| JKQ | 인용격 조사 | JKQ | 인용격 조사 | ||
| JX | 보조사 | JX | 보조사 | ||
| JC | 접속 조사 | JC | 접속 조사 | ||
| 선어말 어미 | EP | 선어말 어미 | EP | 선어말 어미 | |
| 어말 어미 | EF | 종결 어미 | EF | 종결 어미 | |
| EC | 연결 어미 | EC | 연결 어미 | ||
| ETN | 명사형 전성 어미 | ETN | 명사형 전성 어미 | ||
| ETM | 관형형 전성 어미 | ETM | 관형형 전성 어미 | ||
| 접두사 | XPN | 체언 접두사 | XPN | 체언 접두사 | |
| 접미사 | XSN | 명사 파생 접미사 | XSN | 명사 파생 접미사 | |
| XSV | 동사 파생 접미사 | XSV | 동사 파생 접미사 | ||
| XSA | 형용사 파생 접미사 | XSA | 형용사 파생 접미사 | ||
| 어근 | XR | 어근 | XR | 어근 | |
| 부호 | SF | 마침표, 물음표, 느낌표 | SF | 마침표, 물음표, 느낌표 | |
| SE | 줄임표 | SE | 줄임표 … | ||
| SS | 따옴표,괄호표,줄표 | SSO | 여는 괄호 (, [ | ||
| SSC | 닫는 괄호 ), ] | ||||
| SP | 쉼표,가운뎃점,콜론,빗금 | SC | 구분자 , · / : | ||
| SO | 붙임표(물결,숨김,빠짐) | SY | |||
| SW | 기타기호 (논리수학기호,화폐기호) | ||||
| 한글 이외 | SL | 외국어 | SL | 외국어 | |
| SH | 한자 | SH | 한자 | ||
| SN | 숫자 | SN | 숫자 | ||
이상으로 단어 추출 도구에 대한 글을 마친다. 기능을 추가하거나 개선하면 별도의 글을 작성할 예정이다.
<< 관련 글 목록 >>