단어 추출 도구(3): 단어 추출 도구 실행 방법과 결과 확인 방법
단어 추출 도구 실행 방법과 결과 확인 방법 에 대해 살펴본다.
이전 글에서 이어지는 내용이다.
3. 단어 추출 도구 실행
3.1. 단어 추출 도구 다운로드
단어 추출 도구는 github에 업로드해 두었다.
https://github.com/DAToolset/ToolsForDataStandard/tree/main/WordExtractor
실행에 필요한 소스코드, 글꼴, table/column 목록 예시 파일, 출력 예시 파일을 배포용 압축파일로 묶어 두었으니, 이 파일을 다운로드 받으면 된다.
https://github.com/DAToolset/ToolsForDataStandard/raw/main/WordExtractor/word_extractor.7z
이 배포 압축파일에는 다음과 같은 파일이 포함되어 있다.
[font] - NanumBarunGothic.ttf - NanumSquareR.ttf [out] - extract_result_20210829111836.xlsx - wordcloud_20210829111836.png - table,column comments.xlsx - word_extractor.py
각 폴더, 파일에 대한 설명은 다음과 같다.
- [font]
- WordCloud를 생성할 때 필요한 글꼴이 포함된 폴더
- 필요시 다른 글꼴을 추가하고 소스코드 변경하여 사용가능
- 소스코드에서 변경할 함수: make_word_cloud
- [out]
- 단어 추출결과 예시 파일들이 포함된 폴더
- 이 파일의 내용은 아래 글에서 확인할 수 있다.
1.3.3. 단어 추출 도구 출력 자료
- table, column comments.xlsx
- DB table, column comment 입력 예시 파일
- 이 파일의 내용은 아래 글에서 확인할 수 있다.
1.3.1._단어_추출_도구_입력_자료
- word_extractor.py: 단어 추출 도구 소스 코드 (Python)
- 주의: 이 소스 코드 파일은 변경될 수 있으므로 최신 버전은 배포 압축 파일이 아닌 github 파일을 확인할 것.
3.2. 단어 추출 도구 실행 방법
3.2.1. 다운로드 파일 압축 해제하고, Python 가상 환경 활성화
위에서 다운로드 받은 배포 압축 파일을 적당한 경로에 해제한다. (예: “d:\Project\WordExtractor”)
Miniconda Prompt를 실행하고 압축을 해제한 경로로 이동후 Python 가상환경을 활성화한다.
Python 가상 환경 활성화는 다음 글을 참조한다.
다음과 같은 Miniconda Prompt 상태에서 진행한다.
(wordextr) d:\Project\WordExtractor>
3.2.2. 도움말 확인
“–help” argument를 지정하고 실행하면 도움말을 확인할 수 있다.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
실행시 출력되는 내용은 다음과 같다.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
usage: word_extractor.py [-h] [--multi_process_count MULTI_PROCESS_COUNT] [--db_comment_file DB_COMMENT_FILE] [--in_path IN_PATH] --out_path OUT_PATH
--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment
optional arguments:
-h, --help show this help message and exit
--multi_process_count MULTI_PROCESS_COUNT
text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)
--db_comment_file DB_COMMENT_FILE
DB Table, Column comment 정보 파일명(예: comment.xlsx)
--in_path IN_PATH 입력파일(ppt, doc, txt) 경로명(예: .\in)
--out_path OUT_PATH 출력파일(xlsx, png) 경로명(예: .\out)
실행 방법은 세 가지이다. (위 도움말의 “* 실행 예시” 내용 참조)
- 문서 파일에서만 단어 추출
- MS Word, PowerPoint, Text파일이 저장된 폴더를 “–in_path”로 지정하고, 결과를 출력할 폴더를 “–out_path”로 지정
- DB Table, Column comment에서만 단어 추출
- comment 파일 형식으로 저장된 엑셀 파일을 “–db_comment_file”로 지정하고, 결과를 출력할 폴더를 “–out_path”로 지정
- 문서 파일과 DB Table, Column comment 모두 에서 단어 추출 (1과 2 모두 한번에 추출하는 방법)
- “–in_path”, “–db_comment_file”, “–out_path” 모두 지정
“–multi_process_count” argument는 파일로부터 텍스트를 추출하고, 그 텍스트에서 단어를 추출할 때 병렬로 동시에 실행할 process의 개수이다. 실행환경에 따라 적정한 수치를 지정하면 성능이 향상될 수 있다.
이 글에서는 “–multi_process_count” argument는 지정하지 않고 실행한다. 이 경우 코드 실행 과정에서 실행환경의 logical cpu 개수로 설정된다. (예: i5-8250U CPU인 경우 8)
3.2.3. 실행방법1: 문서 파일에서만 단어 추출
먼저 문서 파일을 저장할 폴더를 Python 소스코드가 있는 경로 하위에 생성한다.
예를 들어, “in” 폴더를 “d:\Project\WordExtractor” 하위에 생성하여 “d:\Project\WordExtractor\in” 경로를 만든다.
그리고, “in” 폴더에 MS Word, PowerPoint, Text 형식의 파일을 복사한다. “in” 폴더 하위에 여러 계층의 폴더가 있더라도 모두 탐색하여 처리할 수 있으니, 업무단위 등으로 하위 폴더를 구성해 두는 것이 좋다.
참고로, 이 글을 작성하는 현재 시점(2021-10-24)에는 HWP, PDF 파일은 아직 지원하지 않는다.
다음과 같은 명령어로 실행한다. (–in_path, –out_path 지정)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out
실행결과 예시는 다음과 같다.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:15:11.985581 ##### arguments ##### multi_process_count: 8 db_comment_file: None in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:15:11.985581] Start Get File List... [2021-10-24 12:15:11.985581] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:15:11.985581] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx text count: 25 line count: 34 [pid:17976] get_txt_text elapsed time: 0:00:00.135933 text count: 124 page count: 5 [pid:5412] get_ppt_text elapsed time: 0:00:03.370637 text count: 59 page count: 3 [pid:22052] get_doc_text elapsed time: 0:00:04.100849 [2021-10-24 12:15:18.094089] Finish Get File Text. [2021-10-24 12:15:18.094089] Start Get Word from File Text... [pid:25016] input text count:26, extracted word count: 31 [pid:25016] get_word_list finished. total: 26, elapsed time: 0:00:00.109351 [pid:17704] input text count:26, extracted word count: 54 [pid:17704] get_word_list finished. total: 26, elapsed time: 0:00:00.156214 [pid:18468] input text count:26, extracted word count: 52 [pid:18468] get_word_list finished. total: 26, elapsed time: 0:00:00.140596 [pid:3456] input text count:26, extracted word count: 38 [pid:3456] get_word_list finished. total: 26, elapsed time: 0:00:00.109350 [pid:15400] input text count:26, extracted word count: 50 [pid:15400] get_word_list finished. total: 26, elapsed time: 0:00:00.140594 [pid:25892] input text count:26, extracted word count: 65 [pid:25892] get_word_list finished. total: 26, elapsed time: 0:00:00.171835 [pid:3592] input text count:26, extracted word count: 147 [pid:3592] get_word_list finished. total: 26, elapsed time: 0:00:00.312458 [pid:9512] input text count:26, extracted word count: 180 [pid:9512] get_word_list finished. total: 26, elapsed time: 0:00:00.374976 [2021-10-24 12:15:20.320614] Finish Get Word from File Text. [2021-10-24 12:15:20.320614] Start Get Word Frequency... [2021-10-24 12:15:20.336234] Finish Get Word Frequency. [2021-10-24 12:15:20.336234] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:06.681665 [2021-10-24 12:15:27.017899] Finish Make Word Cloud. [2021-10-24 12:15:27.017899] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:15:27.643679] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:15:27.643679] Finished. overall elapsed time: 0:00:15.658098 ------------------------------------------------------------
3.2.4. 실행방법2: DB Table, Column comment에서만 단어 추출
먼저, 압축파일에 포함되어 있는 “table,column comments.xlsx” 파일을 엑셀에서 열고 형식에 맞게 내용을 채우고 저장한다.
형식과 내용 예시는 아래 글을 참고한다.
다음과 같은 명령어로 실행한다. (–db_comment_file, –out_path 지정)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
입력 파일명에 공백문자가 포함되어 있어서 파일명을 겹따옴표(“)로 감쌌다.
“table,column comments.xlsx” 파일이 Python 소스코드 파일의 경로와 다르다면 그 경로를 포함하여 지정하면 된다. 여기에서는 같은 경로에 있는 것으로 가정했다.
실행결과 예시는 다음과 같다.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:34:23.369210 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: None out_path: .\out ------------------------------------------------------------ [2021-10-24 12:34:23.370209] Start Get File Text... get_db_comment_text: table,column comments.xlsx table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:17088] get_db_comment_text elapsed time: 0:00:01.216618 text count: 1680 [2021-10-24 12:34:26.577237] Finish Get File Text. [2021-10-24 12:34:26.577237] Start Get Word from File Text... [pid:25240] current: 100, total: 210, progress: 47.62% [pid:21792] current: 100, total: 210, progress: 47.62% [pid:14788] current: 100, total: 210, progress: 47.62% [pid:10660] current: 100, total: 210, progress: 47.62% [pid:17208] current: 100, total: 210, progress: 47.62% [pid:13300] current: 100, total: 210, progress: 47.62% [pid:23764] current: 100, total: 210, progress: 47.62% [pid:25068] current: 100, total: 210, progress: 47.62% [pid:13300] current: 200, total: 210, progress: 95.24% [pid:14788] current: 200, total: 210, progress: 95.24% [pid:13300] input text count:210, extracted word count: 804 [pid:13300] get_word_list finished. total: 210, elapsed time: 0:00:02.900049 [pid:10660] current: 200, total: 210, progress: 95.24% [pid:14788] input text count:210, extracted word count: 850 [pid:14788] get_word_list finished. total: 210, elapsed time: 0:00:03.005057 [pid:10660] input text count:210, extracted word count: 819 [pid:10660] get_word_list finished. total: 210, elapsed time: 0:00:03.040949 [pid:17208] current: 200, total: 210, progress: 95.24% [pid:25240] current: 200, total: 210, progress: 95.24% [pid:17208] input text count:210, extracted word count: 929 [pid:17208] get_word_list finished. total: 210, elapsed time: 0:00:03.182333 [pid:25240] input text count:210, extracted word count: 871 [pid:25240] get_word_list finished. total: 210, elapsed time: 0:00:03.320128 [pid:23764] current: 200, total: 210, progress: 95.24% [pid:21792] current: 200, total: 210, progress: 95.24% [pid:23764] input text count:210, extracted word count: 1054 [pid:23764] get_word_list finished. total: 210, elapsed time: 0:00:03.362429 [pid:25068] current: 200, total: 210, progress: 95.24% [pid:21792] input text count:210, extracted word count: 1077 [pid:21792] get_word_list finished. total: 210, elapsed time: 0:00:03.651294 [pid:25068] input text count:210, extracted word count: 1163 [pid:25068] get_word_list finished. total: 210, elapsed time: 0:00:03.616955 [2021-10-24 12:34:32.287245] Finish Get Word from File Text. [2021-10-24 12:34:32.287245] Start Get Word Frequency... [2021-10-24 12:34:32.313363] Finish Get Word Frequency. [2021-10-24 12:34:32.313363] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.572230 [2021-10-24 12:34:42.886547] Finish Make Word Cloud. [2021-10-24 12:34:42.886547] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:34:48.636633] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:34:48.636633] Finished. overall elapsed time: 0:00:25.266424 ------------------------------------------------------------
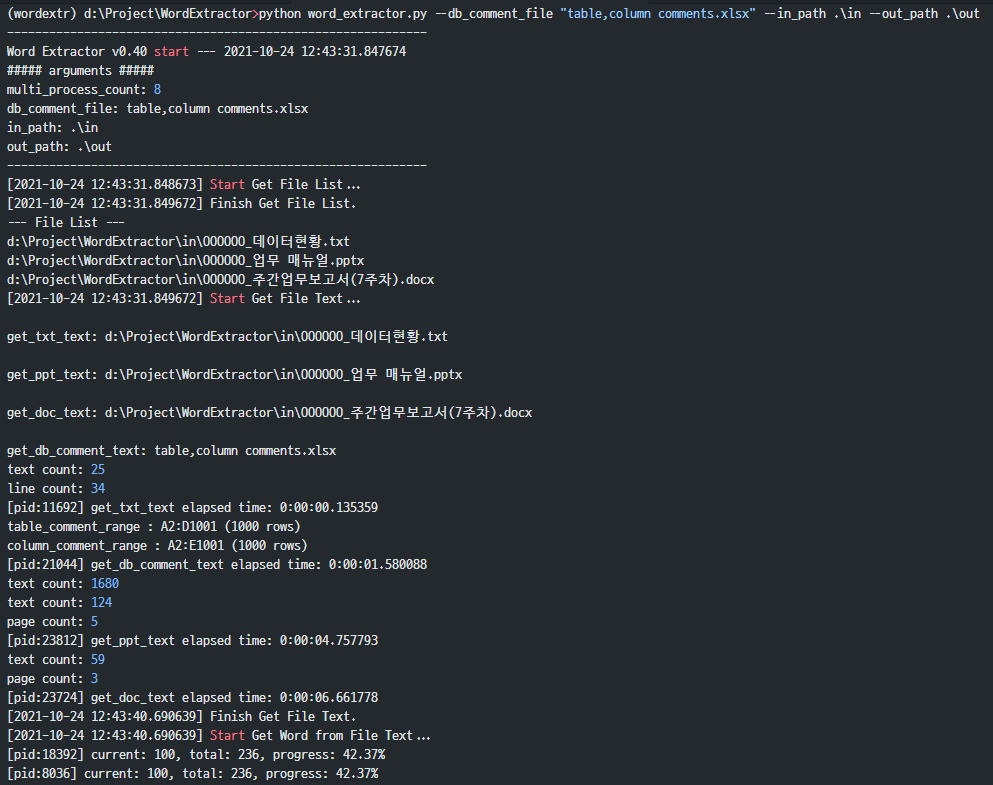
3.2.5. 실행방법3: 문서 파일과 DB Table, Column comment 모두 에서 단어 추출
실행방법1과 2를 한꺼번에 실행할 수 있는 방법이다.
다음과 같은 명령어로 실행한다. (–db_comment_file, –in_path, –out_path 지정)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out
실행결과 예시는 다음과 같다.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:43:31.847674 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:43:31.848673] Start Get File List... [2021-10-24 12:43:31.849672] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:43:31.849672] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx get_db_comment_text: table,column comments.xlsx text count: 25 line count: 34 [pid:11692] get_txt_text elapsed time: 0:00:00.135359 table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:21044] get_db_comment_text elapsed time: 0:00:01.580088 text count: 1680 text count: 124 page count: 5 [pid:23812] get_ppt_text elapsed time: 0:00:04.757793 text count: 59 page count: 3 [pid:23724] get_doc_text elapsed time: 0:00:06.661778 [2021-10-24 12:43:40.690639] Finish Get File Text. [2021-10-24 12:43:40.690639] Start Get Word from File Text... [pid:18392] current: 100, total: 236, progress: 42.37% [pid:8036] current: 100, total: 236, progress: 42.37% [pid:26864] current: 100, total: 236, progress: 42.37% [pid:23288] current: 100, total: 236, progress: 42.37% [pid:15596] current: 100, total: 236, progress: 42.37% [pid:8036] current: 200, total: 236, progress: 84.75% [pid:18208] current: 100, total: 236, progress: 42.37% [pid:17976] current: 100, total: 236, progress: 42.37% [pid:4324] current: 100, total: 236, progress: 42.37% [pid:18392] current: 200, total: 236, progress: 84.75% [pid:26864] current: 200, total: 236, progress: 84.75% [pid:8036] input text count:236, extracted word count: 739 [pid:8036] get_word_list finished. total: 236, elapsed time: 0:00:02.651907 [pid:18392] input text count:236, extracted word count: 780 [pid:18392] get_word_list finished. total: 236, elapsed time: 0:00:02.879298 [pid:15596] current: 200, total: 236, progress: 84.75% [pid:26864] input text count:236, extracted word count: 887 [pid:26864] get_word_list finished. total: 236, elapsed time: 0:00:03.161543 [pid:15596] input text count:236, extracted word count: 979 [pid:15596] get_word_list finished. total: 236, elapsed time: 0:00:03.443786 [pid:18208] current: 200, total: 236, progress: 84.75% [pid:23288] current: 200, total: 236, progress: 84.75% [pid:17976] current: 200, total: 236, progress: 84.75% [pid:18208] input text count:236, extracted word count: 1181 [pid:18208] get_word_list finished. total: 236, elapsed time: 0:00:03.831052 [pid:4324] current: 200, total: 236, progress: 84.75% [pid:23288] input text count:236, extracted word count: 1242 [pid:23288] get_word_list finished. total: 236, elapsed time: 0:00:04.139228 [pid:17976] input text count:236, extracted word count: 1294 [pid:17976] get_word_list finished. total: 236, elapsed time: 0:00:04.113296 [pid:4324] input text count:236, extracted word count: 1082 [pid:4324] get_word_list finished. total: 236, elapsed time: 0:00:04.334706 [2021-10-24 12:43:47.324098] Finish Get Word from File Text. [2021-10-24 12:43:47.325098] Start Get Word Frequency... [2021-10-24 12:43:47.353058] Finish Get Word Frequency. [2021-10-24 12:43:47.353058] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.604237 [2021-10-24 12:43:57.958289] Finish Make Word Cloud. [2021-10-24 12:43:57.958289] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:44:04.752046] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:44:04.752046] Finished. overall elapsed time: 0:00:32.903374 ------------------------------------------------------------
위 실행과정 일부를 이미지로 캡쳐하여 붙여 둔다.
3.2.6. 실행 결과 확인 방법
실행시 출력 경로로 지정한 폴더(\out)에 2개의 파일(xlsx, png)이 생성된다. 파일명에 연월일시분초(YYYYMMDDHHMISS)가 자동으로 지정되어 언제 생성되었는지 확인할 수 있다.
예를 들어, 배포 압축파일의 out 폴더에 포함되어 있는 실행 결과 파일은 다음과 같다.
- extract_result_20210829111836.xlsx: 단어 추출 결과 엑셀 파일
- wordcloud_20210829111836.png: 단어 추출 결과 엑셀 파일 “단어빈도” 시트로 생성한 word cloud 이미지 파일
실행 결과 파일의 형식과 내용은 아래 글을 참조한다.
3.2.7. 실행시 주의/참고사항
- 실행하기 전 MS-Word, PowerPoint 응용 프로그램을 먼저 실행해 두면 실행 성능이 약간 향상된다.
- 실행 중 MS-Word, PowerPoint 응용 프로그램에서 파일이 열렸다가 처리가 끝나면 닫힌다. 단어추출기가 실행되는 도중에는 각 응용 프로그램을 사용하지 말고 그대로 두어야 한다.
- 파일이 많을 수록, 파일내에 페이지가 많을 수록, comment 엑셀 파일의 데이터 행이 많을 수록 실행시간이 오래 걸린다.
- 전체를 실행하기전에 입력 파일의 일부와 comment 엑셀 파일의 데이터 일부만 별도로 저장하여 잘 동작하는지 테스트를 먼저 해보는 것을 권장한다.
- 전체를 실행할 때는 오래 걸릴 것을 감안하여, 식사시간이나 쉬는 시간에 실행하는 것이 좋다.
이번 글은 단어 추출 도구 사용 방법에 대해 살펴보았다. 사용상의 궁금한 점이나 추가되었으면 좋은 기능이 있다면 댓글로 남겨주기 바란다.
다음 글은 소스코드에 대해 살펴보겠다.
<< 관련 글 목록 >>


















안녕하십니까! 좋은 코드 감사합니다.
pptx 파일을 input으로 하여 코드 실행 시 질문이 있습니다.
.pptx 파일에서 단어 추출하는 것을 테스트 해보았는데
코드 실행 시 비어있는 ppt 창이 종료되지 않고 떠있는 현상이 있습니다.
word, txt, excel은 유사한 현상이 발생하지 않고 있습니다.
오피스 버전에 따른 일시적인 현상인지 문의 드리고 싶습니다.
사용 환경은
window는 11, office는 365 버전 사용하고 있습니다.
감사합니다.
안녕하세요, 방문과 댓글 감사합니다.
김기영님의 상황을 구체적으로 알고 싶습니다.
다음 둘 중에 어느 경우인가요?
1) 코드 실행 “중에” 파워포인트 응용 프로그램이 응답이 없고, 다음 파일로 진행되지 않는 현상
2) 코드 실행 “후에” 파워포인트 응용 프로그램이 종료되지 않고 열려 있는 현상
만약 1)의 경우라면,
– 작업관리자에서 파워포인트를 강제 종료하면 다음 파일로 진행은 되나
– 현재 파일이 제대로 처리되지 않았을 가능성이 있어
– 처음부터 다시 작업을 실행하는 것이 좋습니다.
만약 2)의 경우라면,
– 파워포인트를 미리 실행해 두고 나서 단어 추출 도구를 실행했다면 파워포인트 응용 프로그램은 계속 실행되어 있는 게 정상입니다.
– 파워포인트를 실행해 두지 않았다면 이상 동작이긴 한데, 전체 파일이 모두 처리되었다면 특별히 신경 쓸 필요는 없겠습니다.
참고로, 파워포인트, 엑셀 등의 응용 프로그램을 실행하지 않은 상태에서 단어 추출 도구를 실행하면, OLE 자동화 과정에서 파워포인트, 엑셀 등의 응용 프로그램이 실행되었다가 처리 완료후 종료되어야 정상입니다.
그외의 경우라면 추가 댓글 남겨주세요.
안녕하세요 빠른 답변 감사합니다!
제 경우에는 2) 코드 실행 “후에” 파워포인트 응용 프로그램이 종료되지 않고 열려 있는 현상입니다.
파워포인트를 미리 실행해둔 것이 아닌 상태라 말씀하신 대로라면 이상 동작인 것 같습니다.
전체 파일은 특별한 이상 없이 모두 처리되었습니다.
감사합니다!
상황과 결과를 알려주셔서 감사합니다.
잘 사용해 주세요~ ^^
안녕하세요. 현재 해당 도구를 사용하는데, 작동이 안되고 있어서요. miniforge의 문제인건지.. 일단 다른 환경에서 miniconda설치해서 다시 실행해보겠습니다
——————————————————————————————
(wordextr) C:\Users\User\Downloads\word_extractor>python word_extractor.py –in_path .\in –out_path .\out
C:\Users\User\Downloads\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence ‘\o’
usage_description = “””— Description —
C:\Users\User\Downloads\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence ‘\i’
parser.add_argument(‘–in_path’, required=False, help=’입력파일(ppt, doc, txt) 경로명(예: .\in) ‘)
C:\Users\User\Downloads\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence ‘\o’
parser.add_argument(‘–out_path’, required=True, help=’출력파일(xlsx, png) 경로명(예: .\out)’)
————————————————————
Word Extractor v0.41 start — 2024-01-18 17:36:57.283006
##### arguments #####
multi_process_count: 16
db_comment_file: None
in_path: .\in
out_path: .\out
————————————————————
[2024-01-18 17:36:57.288351] Start Get File List…
[2024-01-18 17:36:57.289390] Finish Get File List.
— File List —
[2024-01-18 17:36:57.290381] Start Get File Text…
Traceback (most recent call last):
File “C:\Users\User\Downloads\word_extractor\word_extractor.py”, line 559, in
main()
File “C:\Users\User\Downloads\word_extractor\word_extractor.py”, line 461, in main
df_text = pd.concat(mp_text_result, ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, line 380, in concat
op = _Concatenator(
^^^^^^^^^^^^^^
File “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, line 443, in __init__
objs, keys = self._clean_keys_and_objs(objs, keys)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, line 505, in _clean_keys_and_objs
raise ValueError(“No objects to concatenate”)
ValueError: No objects to concatenate
버전정보는 다음과 같아요
Python 3.12.1
Package Version
————— ————
contourpy 1.2.0
cycler 0.12.1
eunjeon 0.4.0
fonttools 4.47.2
Jinja2 3.1.3
kiwisolver 1.4.5
MarkupSafe 2.1.3
matplotlib 3.8.2
numpy 1.26.3
packaging 23.2
pandas 2.1.4
pillow 10.2.0
pip 23.3.2
pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
pywin32 306
setuptools 69.0.3
six 1.16.0
tzdata 2023.4
wheel 0.42.0
wordcloud 1.9.3
XlsxWriter 3.1.9
input directory에 아래 확장자의 파일이 하나도 없는 경우 발생하는 오류로 보여집니다.
– .ppt, .pptx
– .doc, .docx
– .txt
다음과 같이 테스트해봤습니다.
———————————————————————–
(.venv) D:\Temp\python_venv\wordextr_test>python –version
Python 3.11.1
(.venv) D:\Temp\python_venv\wordextr_test>python word_extractor.py –in_path .\in –out_path .\out
————————————————————
Word Extractor v0.41 start — 2024-01-19 08:55:44.842578
##### arguments #####
multi_process_count: 8
db_comment_file: None
in_path: .\in
out_path: .\out
————————————————————
[2024-01-19 08:55:44.845602] Start Get File List…
[2024-01-19 08:55:44.845602] Finish Get File List.
— File List —
[2024-01-19 08:55:44.845602] Start Get File Text…
Traceback (most recent call last):
File “D:\Temp\python_venv\wordextr_test\word_extractor.py”, line 164, in
main()
File “D:\Temp\python_venv\wordextr_test\word_extractor.py”, line 152, in main
df_text = pd.concat(mp_text_result, ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, line 380, in concat
op = _Concatenator(
^^^^^^^^^^^^^^
File “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, line 443, in __init__
objs, keys = self._clean_keys_and_objs(objs, keys)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, line 505, in _clean_keys_and_objs
raise ValueError(“No objects to concatenate”)
ValueError: No objects to concatenate
(.venv) D:\Temp\python_venv\wordextr_test>dir .\in
D 드라이브의 볼륨: Data
볼륨 일련 번호: D6EC-7CFE
D:\Temp\python_venv\wordextr_test\in 디렉터리
2024-01-18 오후 09:41
2024-01-18 오후 09:41
0개 파일 0 바이트
2개 디렉터리 34,305,060,864 바이트 남음
안녕하세요. 현재 해당 도구를 사용하는데, 계속 오류가 뜹니다. 찾아보니 판다스 버전 문제인 것 같은데. (판다스2 부터 .appen 기능을 제공하지 않는다고 하는 것 같아요.) 아니면 혹시 다른 오류일까요?
(wordextr) C:\Users\hyelm\Documents\word_extractor>python word_extractor.py. –db_comment_file “table_column_comments1.xlsx” –out_path ‘C:\Users\hyelm\Documents\word_extractor\out’
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence ‘\o’
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence ‘\i’
parser.add_argument(‘–in_path’, required=False, help=’입력파일(ppt, doc, txt) 경로명(예: .\in) ‘)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence ‘\o’
parser.add_argument(‘–out_path’, required=True, help=’출력파일(xlsx, png) 경로명(예: .\out)’)
————————————————————
Word Extractor v0.41 start — 2024-04-29 14:28:41.474667
##### arguments #####
multi_process_count: 4
db_comment_file: table_column_comments1.xlsx
in_path: None
out_path: ‘C:\Users\hyelm\Documents\word_extractor\out’
————————————————————
[2024-04-29 14:28:41.479798] Start Get File Text…
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence ‘\o’
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence ‘\i’
parser.add_argument(‘–in_path’, required=False, help=’입력파일(ppt, doc, txt) 경로명(예: .\in) ‘)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence ‘\o’
parser.add_argument(‘–out_path’, required=True, help=’출력파일(xlsx, png) 경로명(예: .\out)’)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence ‘\o’
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence ‘\i’
parser.add_argument(‘–in_path’, required=False, help=’입력파일(ppt, doc, txt) 경로명(예: .\in) ‘)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence ‘\o’
parser.add_argument(‘–out_path’, required=True, help=’출력파일(xlsx, png) 경로명(예: .\out)’)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence ‘\o’
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence ‘\i’
parser.add_argument(‘–in_path’, required=False, help=’입력파일(ppt, doc, txt) 경로명(예: .\in) ‘)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence ‘\o’
parser.add_argument(‘–out_path’, required=True, help=’출력파일(xlsx, png) 경로명(예: .\out)’)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence ‘\o’
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence ‘\i’
parser.add_argument(‘–in_path’, required=False, help=’입력파일(ppt, doc, txt) 경로명(예: .\in) ‘)
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence ‘\o’
parser.add_argument(‘–out_path’, required=True, help=’출력파일(xlsx, png) 경로명(예: .\out)’)
get_db_comment_text: table_column_comments1.xlsx
table_comment_range : A2:D7112 (7111 rows)
column_comment_range : A2:E181935 (181934 rows)
multiprocessing.pool.RemoteTraceback:
“””
Traceback (most recent call last):
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 125, in worker
result = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 48, in mapstar
return list(map(*args))
^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 369, in get_file_text
df_text = get_db_comment_text(file_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 343, in get_db_comment_text
df_text = df_column.append(df_table, ignore_index=True)
^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\site-packages\pandas\core\generic.py”, line 6296, in __getattr__
return object.__getattribute__(self, name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: ‘DataFrame’ object has no attribute ‘append’. Did you mean: ‘_append’?
“””
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 559, in
main()
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 460, in main
mp_text_result = pool.map(get_file_text, file_list)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 367, in map
return self._map_async(func, iterable, mapstar, chunksize).get()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 774, in get
raise self._value
AttributeError: ‘DataFrame’ object has no attribute ‘append’
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: ‘DataFrame’ object has no attribute ‘append’. Did you mean: ‘_append’?
“””
위 댓글에 코드가 너무 이상하게 복사되어 다시 남깁니다.
이러한 오류가 뜨는게 판다스 버전 문제가 맞을까요?
Pandas v2.0 부터 append 가 더이상 지원되지 않아서 concat으로 변경해야 하는게 맞네요.
아래 두 문서를 참조했습니다.
https://yunwoong.tistory.com/253
https://stackoverflow.com/questions/75956209/error-dataframe-object-has-no-attribute-append
제가 요즘에 시간 내기가 어려워서 언제 소스코드를 변경할 수 있을지 모르겠네요.
Pandas 설치할 때 이전 버전을 지정하여 설치해 보시겠어요?
잘 처리되기를 바랍니다~