Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
Let's take a look at how to run the word extraction tool and check the results.
This is a continuation of the previous article.
Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
3. Run the word extraction tool
3.1. Download word extraction tool
The word extraction tool has been uploaded to github.
https://github.com/DAToolset/ToolsForDataStandard/tree/main/WordExtractor
Source codes, fonts, table/column list example files, and output example files necessary for execution are bundled into a compressed file for distribution, so you can download this file.
https://github.com/DAToolset/ToolsForDataStandard/raw/main/WordExtractor/word_extractor.7z
This distribution archive contains the following files:
[font] - NanumBarunGothic.ttf - NanumSquareR.ttf [out] - extract_result_20210829111836.xlsx - wordcloud_20210829111836.png - table,column comments.xlsx - word_extractor.py
The description of each folder and file is as follows.
- [font]
- Folder containing the fonts needed when creating WordCloud
- If necessary, other fonts can be added and used by changing the source code.
- Function to change in the source code: make_word_cloud
- [out]
- Folder containing example files of word extraction results
- The contents of this file can be found in the article below.
1.3.3. Word extraction tool output data
- table, column comments.xlsx
- DB table, column comment input example file
- The contents of this file can be found in the article below.
1.3.1._word_extraction_tool_input_data
- word_extractor.py: Word Extractor Source Code (Python)
- Note: This source code file is subject to change, so check the github file for the latest version, not the distribution archive.
3.2. How to Run the Word Extraction Tool
3.2.1. Unzip the downloaded file and activate the Python virtual environment
Extract the distribution compressed file downloaded above to an appropriate path. (e.g. “d:\Project\WordExtractor”)
Execute Miniconda Prompt, move to the unzipped path, and activate the Python virtual environment.
To activate the Python virtual environment, refer to the following article.
2.3. Creating and activating a virtual environment
Proceed in the following Miniconda Prompt state.
(wordextr) d:\Project\WordExtractor>
3.2.2. Check Help
You can check the help by specifying the “–help” argument and executing it.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
The output when executed is as follows.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
usage: word_extractor.py [-h] [--multi_process_count MULTI_PROCESS_COUNT] [--db_comment_file DB_COMMENT_FILE] [--in_path IN_PATH] --out_path OUT_PATH
--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment
optional arguments:
-h, --help show this help message and exit
--multi_process_count MULTI_PROCESS_COUNT
text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)
--db_comment_file DB_COMMENT_FILE
DB Table, Column comment 정보 파일명(예: comment.xlsx)
--in_path IN_PATH 입력파일(ppt, doc, txt) 경로명(예: .\in)
--out_path OUT_PATH 출력파일(xlsx, png) 경로명(예: .\out)
There are three ways to do it. (Refer to “* Execution example” in the above help)
- Extract words only from document files
- Designate the folder where MS Word, PowerPoint, and Text files are saved as “–in_path”, and designate the folder to output the results as “–out_path”
- Extract words only from DB Table, Column comments
- Designate the Excel file saved in the comment file format as “–db_comment_file” and designate the folder to output the results as “–out_path”
- Extract words from both document files, DB Tables, and column comments (how to extract both 1 and 2 at once)
- Specify all “–in_path”, “–db_comment_file”, “–out_path”
The “–multi_process_count” argument is the number of processes to run in parallel when extracting text from a file and extracting words from the text. Performance can be improved by specifying an appropriate number according to the execution environment.
In this article, the “-multi_process_count” argument is not specified and executed. In this case, it is set to the number of logical cpus in the execution environment during the code execution process. (e.g. 8 for i5-8250U CPU)
3.2.3. Method 1: Extract words only from document files
First, create a folder to save the document file under the path where the Python source code is located.
For example, create the “in” folder under “d:\Project\WordExtractor” and create the “d:\Project\WordExtractor\in” path.
Then, copy MS Word, PowerPoint, and Text format files to the “in” folder. Even if there are multiple levels of folders under the “in” folder, all of them can be explored and processed, so it is recommended to organize subfolders by business unit, etc.
For reference, at the time of writing this article (2021-10-24), HWP and PDF files are not yet supported.
Run it with the following command: (Specify –in_path, –out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out
An example of the execution result is as follows.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:15:11.985581 ##### arguments ##### multi_process_count: 8 db_comment_file: None in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:15:11.985581] Start Get File List... [2021-10-24 12:15:11.985581] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:15:11.985581] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx text count: 25 line count: 34 [pid:17976] get_txt_text elapsed time: 0:00:00.135933 text count: 124 page count: 5 [pid:5412] get_ppt_text elapsed time: 0:00:03.370637 text count: 59 page count: 3 [pid:22052] get_doc_text elapsed time: 0:00:04.100849 [2021-10-24 12:15:18.094089] Finish Get File Text. [2021-10-24 12:15:18.094089] Start Get Word from File Text... [pid:25016] input text count:26, extracted word count: 31 [pid:25016] get_word_list finished. total: 26, elapsed time: 0:00:00.109351 [pid:17704] input text count:26, extracted word count: 54 [pid:17704] get_word_list finished. total: 26, elapsed time: 0:00:00.156214 [pid:18468] input text count:26, extracted word count: 52 [pid:18468] get_word_list finished. total: 26, elapsed time: 0:00:00.140596 [pid:3456] input text count:26, extracted word count: 38 [pid:3456] get_word_list finished. total: 26, elapsed time: 0:00:00.109350 [pid:15400] input text count:26, extracted word count: 50 [pid:15400] get_word_list finished. total: 26, elapsed time: 0:00:00.140594 [pid:25892] input text count:26, extracted word count: 65 [pid:25892] get_word_list finished. total: 26, elapsed time: 0:00:00.171835 [pid:3592] input text count:26, extracted word count: 147 [pid:3592] get_word_list finished. total: 26, elapsed time: 0:00:00.312458 [pid:9512] input text count:26, extracted word count: 180 [pid:9512] get_word_list finished. total: 26, elapsed time: 0:00:00.374976 [2021-10-24 12:15:20.320614] Finish Get Word from File Text. [2021-10-24 12:15:20.320614] Start Get Word Frequency... [2021-10-24 12:15:20.336234] Finish Get Word Frequency. [2021-10-24 12:15:20.336234] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:06.681665 [2021-10-24 12:15:27.017899] Finish Make Word Cloud. [2021-10-24 12:15:27.017899] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:15:27.643679] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:15:27.643679] Finished. overall elapsed time: 0:00:15.658098 ------------------------------------------------------------
3.2.4. Method 2: Extract words only from DB Table, Column comments
First, open the “table,column comments.xlsx” file included in the compressed file in Excel, fill in the contents according to the format, and save.
See below for examples of format and content.
1.3.1. word extraction tool input material
Run it with the following command: (Specify –db_comment_file, –out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
The file name was enclosed in double quotation marks (“) because the input file name contained blank characters.
If the “table,column comments.xlsx” file is different from the path of the Python source code file, specify it including the path. It is assumed here that they are on the same path.
An example of the execution result is as follows.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:34:23.369210 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: None out_path: .\out ------------------------------------------------------------ [2021-10-24 12:34:23.370209] Start Get File Text... get_db_comment_text: table,column comments.xlsx table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:17088] get_db_comment_text elapsed time: 0:00:01.216618 text count: 1680 [2021-10-24 12:34:26.577237] Finish Get File Text. [2021-10-24 12:34:26.577237] Start Get Word from File Text... [pid:25240] current: 100, total: 210, progress: 47.62% [pid:21792] current: 100, total: 210, progress: 47.62% [pid:14788] current: 100, total: 210, progress: 47.62% [pid:10660] current: 100, total: 210, progress: 47.62% [pid:17208] current: 100, total: 210, progress: 47.62% [pid:13300] current: 100, total: 210, progress: 47.62% [pid:23764] current: 100, total: 210, progress: 47.62% [pid:25068] current: 100, total: 210, progress: 47.62% [pid:13300] current: 200, total: 210, progress: 95.24% [pid:14788] current: 200, total: 210, progress: 95.24% [pid:13300] input text count:210, extracted word count: 804 [pid:13300] get_word_list finished. total: 210, elapsed time: 0:00:02.900049 [pid:10660] current: 200, total: 210, progress: 95.24% [pid:14788] input text count:210, extracted word count: 850 [pid:14788] get_word_list finished. total: 210, elapsed time: 0:00:03.005057 [pid:10660] input text count:210, extracted word count: 819 [pid:10660] get_word_list finished. total: 210, elapsed time: 0:00:03.040949 [pid:17208] current: 200, total: 210, progress: 95.24% [pid:25240] current: 200, total: 210, progress: 95.24% [pid:17208] input text count:210, extracted word count: 929 [pid:17208] get_word_list finished. total: 210, elapsed time: 0:00:03.182333 [pid:25240] input text count:210, extracted word count: 871 [pid:25240] get_word_list finished. total: 210, elapsed time: 0:00:03.320128 [pid:23764] current: 200, total: 210, progress: 95.24% [pid:21792] current: 200, total: 210, progress: 95.24% [pid:23764] input text count:210, extracted word count: 1054 [pid:23764] get_word_list finished. total: 210, elapsed time: 0:00:03.362429 [pid:25068] current: 200, total: 210, progress: 95.24% [pid:21792] input text count:210, extracted word count: 1077 [pid:21792] get_word_list finished. total: 210, elapsed time: 0:00:03.651294 [pid:25068] input text count:210, extracted word count: 1163 [pid:25068] get_word_list finished. total: 210, elapsed time: 0:00:03.616955 [2021-10-24 12:34:32.287245] Finish Get Word from File Text. [2021-10-24 12:34:32.287245] Start Get Word Frequency... [2021-10-24 12:34:32.313363] Finish Get Word Frequency. [2021-10-24 12:34:32.313363] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.572230 [2021-10-24 12:34:42.886547] Finish Make Word Cloud. [2021-10-24 12:34:42.886547] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:34:48.636633] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:34:48.636633] Finished. overall elapsed time: 0:00:25.266424 ------------------------------------------------------------
3.2.5. Method 3: Extracting words from both document files, DB Tables, and Column comments
This is a method that can execute method 1 and method 2 at the same time.
Run it with the following command: (Specify –db_comment_file, –in_path, –out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out
An example of the execution result is as follows.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:43:31.847674 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:43:31.848673] Start Get File List... [2021-10-24 12:43:31.849672] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:43:31.849672] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx get_db_comment_text: table,column comments.xlsx text count: 25 line count: 34 [pid:11692] get_txt_text elapsed time: 0:00:00.135359 table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:21044] get_db_comment_text elapsed time: 0:00:01.580088 text count: 1680 text count: 124 page count: 5 [pid:23812] get_ppt_text elapsed time: 0:00:04.757793 text count: 59 page count: 3 [pid:23724] get_doc_text elapsed time: 0:00:06.661778 [2021-10-24 12:43:40.690639] Finish Get File Text. [2021-10-24 12:43:40.690639] Start Get Word from File Text... [pid:18392] current: 100, total: 236, progress: 42.37% [pid:8036] current: 100, total: 236, progress: 42.37% [pid:26864] current: 100, total: 236, progress: 42.37% [pid:23288] current: 100, total: 236, progress: 42.37% [pid:15596] current: 100, total: 236, progress: 42.37% [pid:8036] current: 200, total: 236, progress: 84.75% [pid:18208] current: 100, total: 236, progress: 42.37% [pid:17976] current: 100, total: 236, progress: 42.37% [pid:4324] current: 100, total: 236, progress: 42.37% [pid:18392] current: 200, total: 236, progress: 84.75% [pid:26864] current: 200, total: 236, progress: 84.75% [pid:8036] input text count:236, extracted word count: 739 [pid:8036] get_word_list finished. total: 236, elapsed time: 0:00:02.651907 [pid:18392] input text count:236, extracted word count: 780 [pid:18392] get_word_list finished. total: 236, elapsed time: 0:00:02.879298 [pid:15596] current: 200, total: 236, progress: 84.75% [pid:26864] input text count:236, extracted word count: 887 [pid:26864] get_word_list finished. total: 236, elapsed time: 0:00:03.161543 [pid:15596] input text count:236, extracted word count: 979 [pid:15596] get_word_list finished. total: 236, elapsed time: 0:00:03.443786 [pid:18208] current: 200, total: 236, progress: 84.75% [pid:23288] current: 200, total: 236, progress: 84.75% [pid:17976] current: 200, total: 236, progress: 84.75% [pid:18208] input text count:236, extracted word count: 1181 [pid:18208] get_word_list finished. total: 236, elapsed time: 0:00:03.831052 [pid:4324] current: 200, total: 236, progress: 84.75% [pid:23288] input text count:236, extracted word count: 1242 [pid:23288] get_word_list finished. total: 236, elapsed time: 0:00:04.139228 [pid:17976] input text count:236, extracted word count: 1294 [pid:17976] get_word_list finished. total: 236, elapsed time: 0:00:04.113296 [pid:4324] input text count:236, extracted word count: 1082 [pid:4324] get_word_list finished. total: 236, elapsed time: 0:00:04.334706 [2021-10-24 12:43:47.324098] Finish Get Word from File Text. [2021-10-24 12:43:47.325098] Start Get Word Frequency... [2021-10-24 12:43:47.353058] Finish Get Word Frequency. [2021-10-24 12:43:47.353058] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.604237 [2021-10-24 12:43:57.958289] Finish Make Word Cloud. [2021-10-24 12:43:57.958289] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:44:04.752046] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:44:04.752046] Finished. overall elapsed time: 0:00:32.903374 ------------------------------------------------------------
A part of the above execution process is captured and pasted as an image.
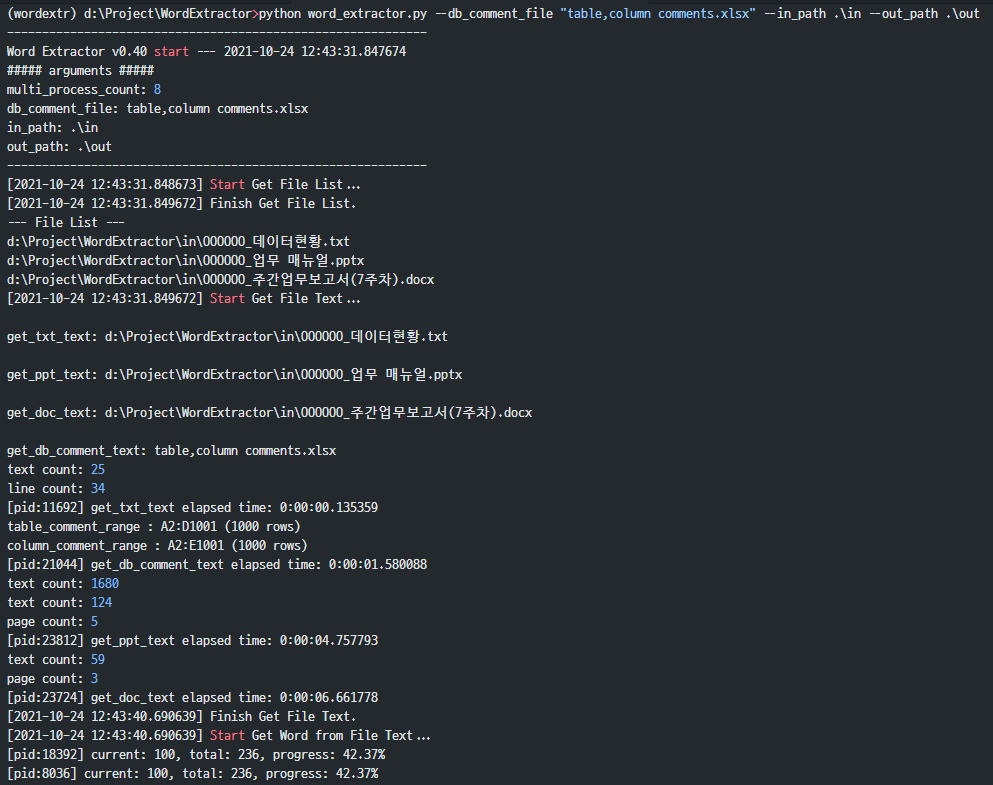
3.2.6. How to check execution results
When executed, two files (xlsx, png) are created in the folder (\out) designated as the output path. Year, month, hour, minute, and second (YYYYMMDDHHMISS) are automatically assigned to the file name, so you can check when it was created.
For example, the execution result file included in the out folder of the distribution compressed file is as follows.
- extract_result_20210829111836.xlsx: Word extraction result excel file
- wordcloud_20210829111836.png: Word cloud image file created with the “word frequency” sheet of the word extraction result excel file
For the format and contents of the execution result file, refer to the article below.
1.3.3. Word extraction tool output data
3.2.7. Precautions/Notes on Execution
- If you run MS-Word or PowerPoint applications first before execution, execution performance is slightly improved.
- During execution, the file is opened in MS-Word or PowerPoint application and closed after processing. While the word extractor is running, do not use each application and leave it as it is.
- The more files, the more pages in the file, and the more rows of data in the comment Excel file, the longer the execution time.
- It is recommended to test whether it works well by separately saving a part of the input file and a part of the data of the comment Excel file before executing the whole thing.
- Considering that it will take a long time to run the whole thing, it is better to do it during a meal or break.
This article looked at how to use the word extraction tool. Please leave a comment if you have any questions about usage or if you have any good features to add.
The next article will take a look at the source code.
<< List of related articles >>
- Word Extraction Tool(1): Overview of Word Extraction Tool
- Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
- Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
- Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
- Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
- Word Extraction Tool (6): Additional Description of Word Extraction Tool
- Full Contents of Word Extraction Tool Description , Download
Related articles:
 Full Contents of Word Extraction Tool Description , Download
Full Contents of Word Extraction Tool Description , Download
 Word Extraction Tool (6): Additional Description of Word Extraction Tool
Word Extraction Tool (6): Additional Description of Word Extraction Tool
 Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
 Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
 Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
 Word Extraction Tool(1): Overview of Word Extraction Tool
Word Extraction Tool(1): Overview of Word Extraction Tool
 Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
 Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)
Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)










hello! thanks for the nice code
I have a question when running the code with a pptx file as input.
I tested extracting words from a .pptx file.
There is a phenomenon that an empty ppt window does not close and floats when the code is executed.
Word, txt, and excel do not have a similar phenomenon.
I would like to inquire if this is a temporary phenomenon depending on the Office version.
environment is
I am using windows 11, office 365 version.
thank you
Hello, thanks for visiting and commenting.
I would like to know more about Kiyoung Kim's situation.
Which of the following is the case?
1) A phenomenon in which the PowerPoint application does not respond “during code execution” and does not proceed to the next file
2) A phenomenon in which the PowerPoint application remains open without closing “after” code execution
If 1) is the case,
– If you forcibly close PowerPoint in the task manager, will you be able to proceed to the next file?
– There is a possibility that the current file was not processed properly.
– It is recommended to run the task again from the beginning.
If 2) is the case,
– It is normal for the PowerPoint application to remain open if you run the word extraction tool after running PowerPoint in advance.
– If you haven't run PowerPoint, it's an odd behavior, but if all files are processed, you don't need to worry about it.
For reference, if you run the word extraction tool without running applications such as PowerPoint and Excel, it is normal if the applications such as PowerPoint and Excel are executed during the OLE automation process and then closed after processing is completed.
Otherwise, please leave additional comments.
Hello, thanks for the quick reply!
In my case, 2) "after" the code execution, the powerpoint application stays open without closing.
As you said, it seems to be an abnormal behavior since PowerPoint has not been run in advance.
All files were processed without any abnormalities.
thank you!
Thanks for letting us know the situation and results.
Please use it well~ ^^
hello. I'm currently using that tool, but it's not working. Is it a problem with miniforge? First, I will install miniconda in a different environment and run it again.
——————————————————————————————
(wordextr) C:\Users\User\Downloads\word_extractor>python word_extractor.py –in_path .\in –out_path .\out
C:\Users\User\Downloads\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence '\o'
usage_description = “””— Description —
C:\Users\User\Downloads\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence '\i'
parser.add_argument('–in_path', required=False, help='Input file (ppt, doc, txt) path name (e.g. .\in) ')
C:\Users\User\Downloads\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence '\o'
parser.add_argument('–out_path', required=True, help='Output file (xlsx, png) path name (e.g. .\out)')
————————————————————
Word Extractor v0.41 start — 2024-01-18 17:36:57.283006
##### arguments #####
multi_process_count: 16
db_comment_file: None
in_path: .\in
out_path: .\out
————————————————————
[2024-01-18 17:36:57.288351] Start Get File List…
[2024-01-18 17:36:57.289390] Finish Get File List.
— File List —
[2024-01-18 17:36:57.290381] Start Get File Text…
Traceback (most recent call last):
File “C:\Users\User\Downloads\word_extractor\word_extractor.py”, line 559, in
main()
File “C:\Users\User\Downloads\word_extractor\word_extractor.py”, line 461, in main
df_text = pd.concat(mp_text_result, ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, line 380, in concat
op = _Concatenator(
^^^^^^^^^^^^^^
File “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, line 443, in __init__
objs, keys = self._clean_keys_and_objs(objs, keys)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, line 505, in _clean_keys_and_objs
raise ValueError(“No objects to concatenate”)
ValueError: No objects to concatenate
The version information is as follows
Python 3.12.1
Package Version
————— ————
contourpy 1.2.0
cycler 0.12.1
eunjeon 0.4.0
fonttools 4.47.2
Jinja2 3.1.3
kiwisolver 1.4.5
MarkupSafe 2.1.3
matplotlib 3.8.2
numpy 1.26.3
packaging 23.2
pandas 2.1.4
pillow 10.2.0
pip 23.3.2
pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
pywin32 306
setuptools69.0.3
six 1.16.0
tzdata 2023.4
wheel 0.42.0
wordcloud 1.9.3
XlsxWriter 3.1.9
This appears to be an error that occurs if there is no file with the extension below in the input directory.
– .ppt, .pptx
– .doc, .docx
– .txt
I tested it as follows:
———————————————————————–
(.venv) D:\Temp\python_venv\wordextr_test>python –version
Python 3.11.1
(.venv) D:\Temp\python_venv\wordextr_test>python word_extractor.py –in_path .\in –out_path .\out
————————————————————
Word Extractor v0.41 start — 2024-01-19 08:55:44.842578
##### arguments #####
multi_process_count: 8
db_comment_file: None
in_path: .\in
out_path: .\out
————————————————————
[2024-01-19 08:55:44.845602] Start Get File List…
[2024-01-19 08:55:44.845602] Finish Get File List.
— File List —
[2024-01-19 08:55:44.845602] Start Get File Text…
Traceback (most recent call last):
File “D:\Temp\python_venv\wordextr_test\word_extractor.py”, line 164, in
main()
File “D:\Temp\python_venv\wordextr_test\word_extractor.py”, line 152, in main
df_text = pd.concat(mp_text_result, ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, line 380, in concat
op = _Concatenator(
^^^^^^^^^^^^^^
File “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, line 443, in __init__
objs, keys = self._clean_keys_and_objs(objs, keys)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, line 505, in _clean_keys_and_objs
raise ValueError(“No objects to concatenate”)
ValueError: No objects to concatenate
(.venv) D:\Temp\python_venv\wordextr_test>dir .\in
Volume on drive D: Data
Volume Serial Number: D6EC-7CFE
D:\Temp\python_venv\wordextr_test\in directory
2024-01-18 09:41 PM
2024-01-18 09:41 PM
0 files 0 bytes
2 directories 34,305,060,864 bytes remaining
hello. I'm currently using that tool, but I keep getting an error. I looked it up and it seems to be a problem with the Pandas version. (It seems that the .appen function is not provided starting from Pandas 2.) Or is it another error?
(wordextr) C:\Users\hyelm\Documents\word_extractor>python word_extractor.py. –db_comment_file “table_column_comments1.xlsx” –out_path 'C:\Users\hyelm\Documents\word_extractor\out'
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence '\o'
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence '\i'
parser.add_argument('–in_path', required=False, help='Input file (ppt, doc, txt) path name (e.g. .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence '\o'
parser.add_argument('–out_path', required=True, help='Output file (xlsx, png) path name (e.g. .\out)')
————————————————————
Word Extractor v0.41 start — 2024-04-29 14:28:41.474667
##### arguments #####
multi_process_count: 4
db_comment_file: table_column_comments1.xlsx
in_path: None
out_path: 'C:\Users\hyelm\Documents\word_extractor\out'
————————————————————
[2024-04-29 14:28:41.479798] Start Get File Text…
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence '\o'
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence '\i'
parser.add_argument('–in_path', required=False, help='Input file (ppt, doc, txt) path name (e.g. .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence '\o'
parser.add_argument('–out_path', required=True, help='Output file (xlsx, png) path name (e.g. .\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence '\o'
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence '\i'
parser.add_argument('–in_path', required=False, help='Input file (ppt, doc, txt) path name (e.g. .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence '\o'
parser.add_argument('–out_path', required=True, help='Output file (xlsx, png) path name (e.g. .\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence '\o'
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence '\i'
parser.add_argument('–in_path', required=False, help='Input file (ppt, doc, txt) path name (e.g. .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence '\o'
parser.add_argument('–out_path', required=True, help='Output file (xlsx, png) path name (e.g. .\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: invalid escape sequence '\o'
usage_description = “””— Description —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: invalid escape sequence '\i'
parser.add_argument('–in_path', required=False, help='Input file (ppt, doc, txt) path name (e.g. .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: invalid escape sequence '\o'
parser.add_argument('–out_path', required=True, help='Output file (xlsx, png) path name (e.g. .\out)')
get_db_comment_text: table_column_comments1.xlsx
table_comment_range : A2:D7112 (7111 rows)
column_comment_range : A2:E181935 (181934 rows)
multiprocessing.pool.RemoteTraceback:
“””
Traceback (most recent call last):
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 125, in worker
result = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 48, in mapstar
return list(map(*args))
^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 369, in get_file_text
df_text = get_db_comment_text(file_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 343, in get_db_comment_text
df_text = df_column.append(df_table, ignore_index=True)
^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\site-packages\pandas\core\generic.py”, line 6296, in __getattr__
return object.__getattribute__(self, name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'DataFrame' object has no attribute 'append'. Did you mean: '_append'?
“””
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 559, in
main()
File “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, line 460, in main
mp_text_result = pool.map(get_file_text, file_list)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 367, in map
return self._map_async(func, iterable, mapstar, chunksize).get()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, line 774, in get
raise self._value
AttributeError: 'DataFrame' object has no attribute 'append'
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'DataFrame' object has no attribute 'append'. Did you mean: '_append'?
“””
The code in the comment above was copied so strangely that I am leaving it again.
Is this error occurring due to a problem with the Pandas version?
As of Pandas v2.0, append is no longer supported, so it is correct to change to concat.
I have referenced the two documents below.
https://yunwoong.tistory.com/253
https://stackoverflow.com/questions/75956209/error-dataframe-object-has-no-attribute-append
I'm having a hard time finding time these days, so I don't know when I'll be able to change the source code.
When installing Pandas, would you like to specify and install a previous version?
I hope it goes well~