2.5. 작업 단위 분할 상세 확인 (DBMS_PARALLEL_EXECUTE)
작업 단위 분할 상세 확인 관련 내용이다. ROWID로 작업 단위(chunk)를 분할한 결과가 어느 정도로 균일하게 분할되는지, 작업 단위의 합이 전체와 동일하게 누락이 없는지, 작업단위 수와 job 개수의 상관관계를 살펴본다.
이전 글에서 이어지는 내용이다.
2.5. 작업 단위 분할 상세 확인
작업 단위가 잘 분할되었는지 다음의 내용을 살펴보자.
- ROWID로 분할한 작업 단위들의 균일한 정도
- ROWID로 분할한 작업 단위들이 누락 없음 확인
- 작업 단위(Chunk)의 수와 작업의 PARALLEL_LEVEL (실행하는 Job의 개수)간의 상관관계
2.5.1. ROWID로 분할한 작업 단위들의 균일한 정도
다음과 같은 분할은 Z_DPE_TEST_TAB 테이블을 ROW Count 기준으로 작업 단위를 10,000건씩 분할하라는 의미이다.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
정말로 10,000 건 씩 분할되었는지 살펴보자.
-- 작업단위 개수 확인 --> 115 SELECT COUNT(*) FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
전체 Row는 1,000,000 건이므로 10,000 건씩 분할하면 100개의 Chunk로 분할되어야 할 것 같으나 실제로는 115개의 Chunk로 분할되었다.
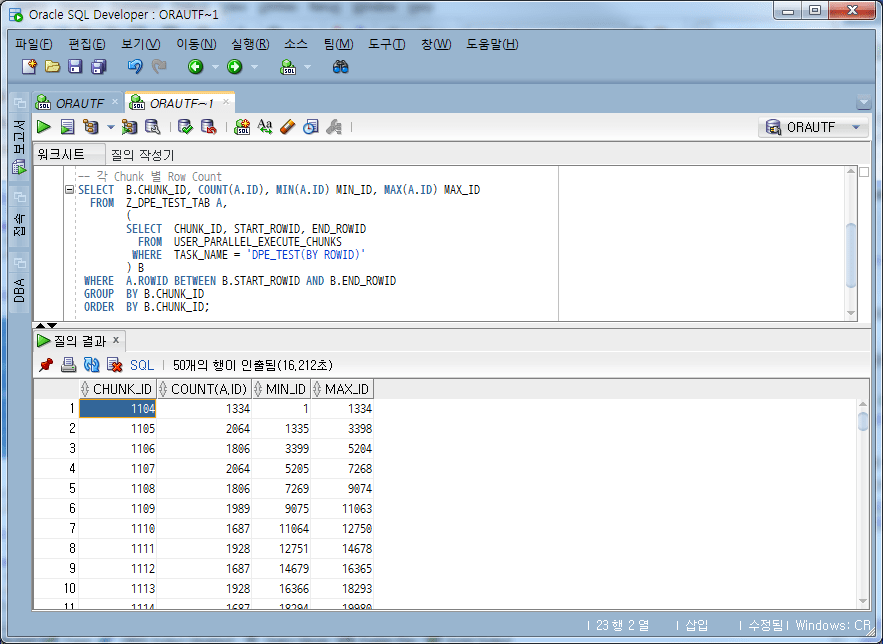
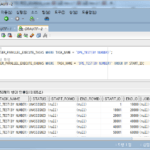
각 Chunk 별로 Row Count를 구해보면,
SELECT B.CHUNK_ID, COUNT(A.ID), MIN(A.ID) MIN_ID, MAX(A.ID) MAX_ID
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
10,000 건이 아닌 1334, 2064, 1886 건 등 다양한 Count로 분할된 것을 확인 할 수 있다.
Chunk에 담긴 Row수가 1,000~2,000구간은 14개, 2,000 Row 구간은 2개, 6,000 Row 구간은 33개, 11,000 Row 구간은 64개, 12,000 Row 구간은 2개이다. (매번 동일한 결과가 나오지 않을 수 있다.)
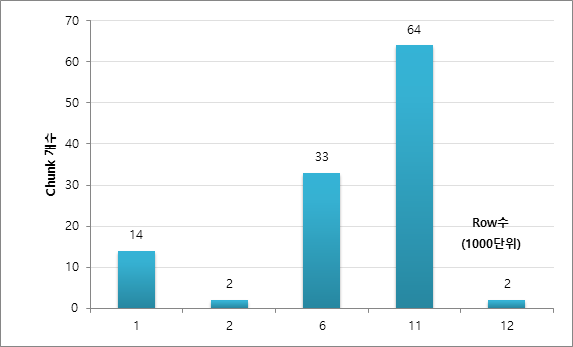
이처럼 완전히 균등한 Row수로 분할되지는 않는다. 이는 ROWID 분할 방법이 DBA_EXTENTS를 기반으로 하는데, 각 EXTENT에 포함된 BLOCK의 수와 각 BLOCK의 ROW Count가 다를 수 있기 때문으로 보인다. 참고로, 테이블에 DELETE 등으로 사용하지 않은 BLOCK이 있을 경우, 실제로 데이터가 존재하지 않는 ROWID 구간이 Chunk로 생성될 수도 있다. 이 또한 DBA_EXTENT에 할당되었다가 데이터가 삭제되었거나, 할당은 되었으나 실제 데이터가 포함되지 않은 EXTENT들이 존재할 때 발생하는 것으로 예상된다.
2.5.2. ROWID로 분할한 작업 단위들이 누락 없음 확인
각 Chunk의 START_ROWID와 END_ROWID 구간을 펼쳤을 때, 누락되는 데이터가 있지 않을까?
우선 Row Count를 확인해 보자.
-- Chunk의 RowID range로 추출한 Row Count
SELECT COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID;
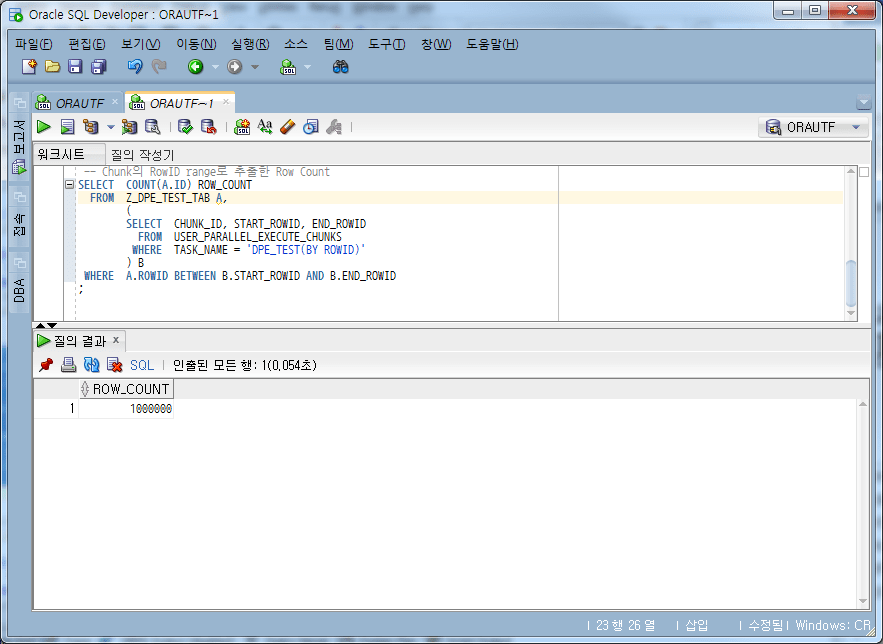
전체 Row Count인 1,000,000 건과 일치하여, 일단 Count는 누락 없음을 확인했고, 다음으로는 Chunk의 START_ROWID ~ END_ROWID 범위로 추출한 데이터를 기준으로 원래의 데이터를 LEFT OUTER JOIN 했을 때 Join 조건에서 빠지는(누락되는) 데이터가 있는지 확인해 보자.
-- Chunk의 RowID로 추출한 데이터의 누락없음 확인
SELECT *
FROM Z_DPE_TEST_TAB A LEFT OUTER JOIN
(
SELECT A.ID -- Chunk의 RowID range로 추출한 데이터
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
) B ON (A.ID = B.ID)
WHERE B.ID IS NULL;
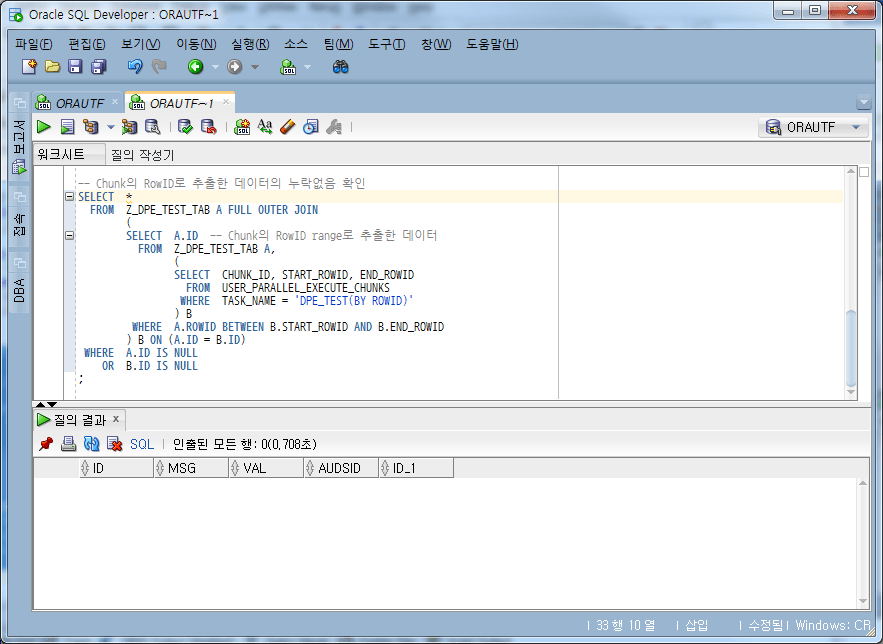
위 결과에서 누락된 데이터가 없음을 확인할 수 있다.
2.5.3. 작업 단위(Chunk)의 수와 작업의 PARALLEL_LEVEL (실행하는 Job의 개수)간의 상관관계
이전 글의 <2.3. 작업 실행> 에서 다음과 같은 내용이 있었다.
PARALLEL_LEVEL은 동시에 실행할 작업(job)의 개수, 즉 병렬도(DOP, Degree Of Parallelism)를 의미하며, 작업 단위인 chunk의 개수와 같을 수도 있고, 작을 수도 있다. 같은 경우는 하나의 job이 하나의 chunk를 처리하고, 작은 경우는 하나의 job이 여러 개의 chunk를 처리하게 된다.
* 참조: 2. ROWID 분할 방식 병렬 처리 사례_2.3. 작업 실행
Chunk수와 Job수에 대해 다음의 경우를 생각해 보자.
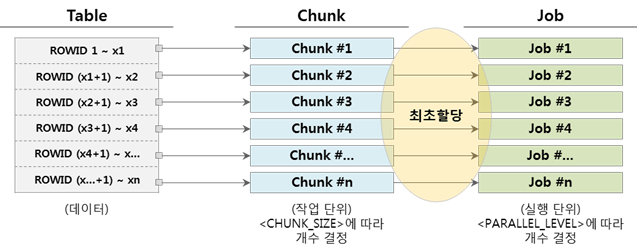
▼ Chunk수와 Job수가 동일한 경우 (Chunk = Job)
하나의 Job은 할당 받은 Chunk의 실행을 완료하면 더 이상 실행할 작업이 없어 종료한다.
▼ Chunk수보다 Job수가 적은 경우 (Chunk > Job)
Job이 할당된 Chunk의 작업을 완료하면 아직 실행되지 않은 Chunk를 할당 받아 계속 실행한다. 아래는 Job이 3개일 경우 예시이다.
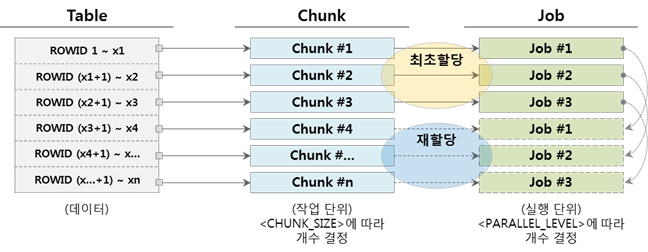
이외에 Chunk수보다 Job수가 많을 경우(Chunk < Job)도 가능은 하나, Chunk를 할당 받지 못하고, 실행 상태를 유지하여 불필요한 resource를 사용할 수 있으므로 적용하지 않는 것이 좋겠다.
* 참고: DBMS_PARALLEL_EXECUTE Chunk by ROWID Example
여기까지 ROWID 분할 방식에 대해 살펴보았다. 다음은 NUMBER column 분할 방식에 대해 살펴본다.
관련 글:
 Oracle Character Set 변환(10): 6.3. CLOB type 한글 변환 방법
Oracle Character Set 변환(10): 6.3. CLOB type 한글 변환 방법
 Oracle Character Set 변환(3): 3. Client 환경 구성(2)
Oracle Character Set 변환(3): 3. Client 환경 구성(2)
 Oracle Character Set 변환(2): 3. Client 환경 구성(1)
Oracle Character Set 변환(2): 3. Client 환경 구성(1)
 DBMS_PARALLEL_EXECUTE 설명글 목차
DBMS_PARALLEL_EXECUTE 설명글 목차
 4. 사용자 정의 SQL 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
4. 사용자 정의 SQL 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 2. ROWID 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
2. ROWID 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)
1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)









