1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)
Oracle 11g R2부터 사용할 수 있는 DBMS_PARALLEL_EXECUTE 에 대해 소개하고 활용사례를 살펴본다.
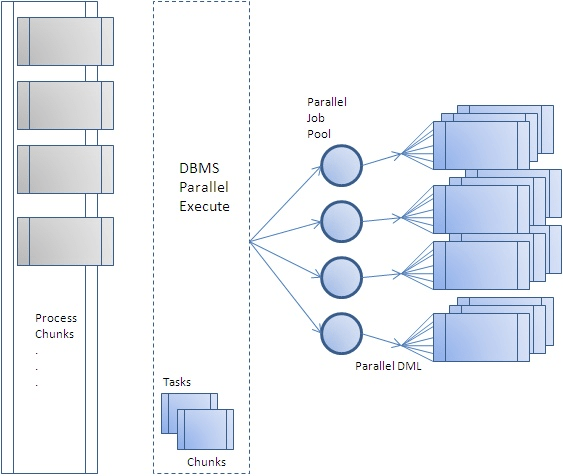
이미지 출처: https://blogs.oracle.com/warehousebuilder/parallel-processing-with-dbmsparallelexecute
1. DML 작업의 병렬 처리 개요
1.1. DML 병렬처리 방법
Database에서 하나의 DML(INSERT, UPDATE, DELETE) 작업을 최대한 많은 자원을 사용하여 빠르게 처리하고자 할 경우에 병렬처리(Parallel Processing)를 활용한다. 병렬처리에는 크게 두 가지 방법이 있다.
첫 번째는, 하나의 SQL을 실행하면서 parallel degree를 hint로 지정하는 방법(Parallel DML, single transaction)이고, 두 번째는 데이터의 범위를 지정하여 여러 개의 SQL을 실행하는 방법(Program Parallel DML, multi transaction) 이다.
대부분의 경우에는 첫 번째 방법인 Parallel DML 방법이 single transaction으로 처리되므로 데이터 정합성면에서 유리하다. 하지만, 첫 번째 방법을 적용할 수 없는 상황이거나 작업 단위의 크기나 범위를 스스로 정의하고자 할 경우는 두 번째의 방법을 적용하는 것이 좋다. (그래서 두 번째 방법을 DIY(Do It Yourself) Parallel DML이라고도 한다)
Parallel DML을 적용할 수 없는 상황은 예를 들어 다음과 같다.
- LOB 컬럼을 포함한 테이블을 SELECT하는 DML
- DB Link상의 DML
- SQL단위가 아닌 PL/SQL 단위나 복잡한 절차로 구현된 Procedure 단위의 병렬 처리 DML
- PL/SQL로 구현되지 않고 Java 등의 언어에서 실행하는 DML
Program Parallel DML을 실행하는 단계는 상황에 따라 조금씩 다르겠지만, 일반적으로 다음과 같다.
- 작업 대상 선정
- 병렬도 선정과 작업 단위 분할(Partition, 날짜, 숫자, ROWID 등) -> 작업 단위로 .sql 파일 생성
- 작업 실행 및 모니터링 -> 각 .sql 파일을 개별 session 에서 실행(SQL*Plus 등)
- 작업 완료 확인 -> Row count 비교, Sum 비교 등 검증
요구사항이나 상황이 바뀌어서 병렬도(DOP, Degree Of Parallelism)를 변경하거나 재 작업을 필요로 할 때 2, 3번 단계가 반복적으로 수행되고 관리와 확인이 간단치 않다. 변경이 필요할 때마다 비슷한 작업을 수작업으로 계속 반복해야 하니 불편하다.
1.2. DBMS_PARALLEL_EXECUTE 개념
Program Parallel 방식을 사용할 때 DBMS_PARALLEL_EXECUTE 를 활용하면 이 작업을 좀 더 편리하게 실행 및 관리할 수 있다.
* 참고 Oracle Document: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS233
(참고로, DBMS_PARALLEL_EXECUTE 는 내부적으로 JOB을 사용하므로 실행하는 user에게 CREATE JOB 권한을 부여해야 한다.)
DBMS_PARALLEL_EXECUTE 는 Oracle 11g R2에서 new feature로 소개된 Package이다. 주요한 sub program의 목록은 다음 표와 같고, 전체 목록과 설명은 Oracle document에서 확인할 수 있다.
| Sub program | 설명 |
| CREATE_TASK Procedure | 작업(task) 생성 |
| CREATE_CHUNKS_BY_NUMBER_COL Procedure | NUMBER column으로 분할 단위(chunk) 생성 |
| CREATE_CHUNKS_BY_ROWID Procedure | ROWID로 분할 단위(chunk) 생성 |
| CREATE_CHUNKS_BY_SQL Procedure | 사용자 정의 SQL로 분할 단위(chunk) 생성 |
| DROP_TASK Procedure | Task 제거 |
| DROP_CHUNKS Procedure | 분할 단위(chunk) 제거 |
| RESUME_TASK Procedures | 중지했던 작업(task) 재실행 |
| RUN_TASK Procedure | 작업(task) 실행 |
| STOP_TASK Procedure | 작업(task) 중지 |
| TASK_STATUS Procedure | 작업(task) 현재 상태 반환 |
DBMS_PARALLEL_EXECUTE를 적용할 때의 단계는 다음과 같이 Program Parallel DML을 실행하는 단계와 거의 유사하다.
- 작업(Task) 생성 (CREATE_TASK)
- 작업 단위(Chunk) 분할 (ROWID, NUMBER, SQL 세가지 방식 제공)
- CREATE_CHUNKS_BY_ROWID
- CREATE_CHUNKS_BY_NUMBER_COL
- CREATE_CHUNKS_BY_SQL
- 작업 실행 (RUN_TASK)
- 작업 완료 후 삭제 (DROP_TASK)
1.3. DBMS_PARALLEL_EXECUTE 테스트를 위한 테이블과 데이터 생성
다음 스크립트로 테스트할 테이블과 데이터를 생성한다.
-- 테스트 테이블과 데이터 생성
DROP TABLE Z_DPE_TEST_TAB PURGE;
CREATE TABLE Z_DPE_TEST_TAB (
ID NUMBER(10)
,MSG VARCHAR2(100)
,VAL NUMBER
,AUDSID NUMBER
) NOLOGGING;
-- 100만건 테스트 데이터 생성
INSERT /*+ APPEND */ INTO Z_DPE_TEST_TAB (ID, MSG)
SELECT LEVEL AS ID
,'Test Data ID: ' || TO_CHAR(LEVEL)
FROM DUAL
CONNECT BY LEVEL <= 1000000;
COMMIT;
테스트에 사용할 컬럼은 4개로 각 용도는 다음과 같다.
| 컬럼명 | 용도 |
| ID | 테이블의 각 행을 식별하기 위한 값 |
| MSG | 설명을 제공하는 값 |
| VAL | 테스트 실행에서 Update되는 임의의 값 (Random value) |
| AUDSID | 테스트가 몇 개의 Session에서 실행되는 지 확인하기 위한 값. SYS_CONTEXT(‘USERENV’,’SESSIONID’)로 Update 된다. |
참고로 이 테스트를 진행한 환경은 다음과 같다.
- DBMS: Oracle 11g R2 Enterprise 11.2.0.1.0 32 bit (On Windows 7 x64)
- H/W: CPU i5-5200U 2.20GHz, Memory 8GB, SSD 250GB
다음으로 각각의 작업 단위(chunk) 분할 방식별로 사례를 살펴보자.
관련 글:
 Oracle Character Set 변환 설명글 전체 목차
Oracle Character Set 변환 설명글 전체 목차
 Oracle Character Set 변환(4): 4.테스트 환경 구성
Oracle Character Set 변환(4): 4.테스트 환경 구성
 Oracle Character Set 변환(3): 3. Client 환경 구성(2)
Oracle Character Set 변환(3): 3. Client 환경 구성(2)
 DBMS_PARALLEL_EXECUTE 설명글 목차
DBMS_PARALLEL_EXECUTE 설명글 목차
 4. 사용자 정의 SQL 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
4. 사용자 정의 SQL 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 2.5. 작업 단위 분할 상세 확인 (DBMS_PARALLEL_EXECUTE)
2.5. 작업 단위 분할 상세 확인 (DBMS_PARALLEL_EXECUTE)
 2. ROWID 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
2. ROWID 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)










Deeply appreciate it!
Thank you so much!