4. 사용자 정의 SQL 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
Oracle DBMS_PARALLEL_EXECUTE 를 활용하여 사용자 정의 SQL 분할 방식 병렬 처리 사례에 대해 살펴본다. 사용자 정의 SQL 작성, 테스트 환경, 작업 생성, 작업 단위 분할, 작업 실행, 작업 완료 확인 및 삭제에 대한 내용이다.
이전 글에서 이어지는 내용이다.
3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
* 참고 Oracle 문서: DBMS_PARALLEL_EXECUTE – CREATE_CHUNKS_BY_SQL Procedure (oracle.com)
4. 사용자 정의 SQL 분할 방식 병렬 처리 사례
4.1. 사용자 정의 SQL 분할 방식 개요
사용자 정의 SQL을 통한 분할 방식은 다음의 경우에 유용하다.
- ROWID 분할방식이 지원하지 않는 경우의 분할 (예: DB Link를 통한 원격 테이블에 대한 ROWID 분할)
- NUMBER column외의 다른 컬럼을 기준으로 분할 (VARCHAR2, DATE 등)
여기에서는 첫 번째 경우의 DB Link를 통한 ROWID 분할 사례를 설명하고자 한다.
CREATE_CHUNKS_BY_ROWID 를 사용하여 DB Link를 통한 테이블의 ROWID 분할을 시도하면, <ORA-29491: invalid table for chunking, 조각에 부적합한 테이블> 오류가 발생한다.
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)');
END;
/
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE
.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)',
TABLE_OWNER => USER,
-- TABLE _NAME을 “T1@DL_MS949”로 DB Link 지정
TABLE_NAME => 'T1@DL_MS949',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
--> 실행 오류 메시지
ORA-29491: 조각에 부적합한 테이블
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 27행
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 121행
ORA-06512: 4행
이 경우, DB Link상의 테이블에 대한 ROWID를 분할해 주는 SQL을 작성하여 CREATE_CHUNKS_BY_SQL 을 통해 적용할 수 있다.
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL ( task_name IN VARCHAR2, sql_stmt IN CLOB, by_rowid IN BOOLEAN);
sql_stmt는 CLOB type으로 길이에 거의 제약없이 사용할 수 있으나, 여기에서는 SQL을 직접 기술하기 보다 Pipe-lined function을 사용하는 방법을 제시한다.
4.2. 사용자 정의 SQL 작성
사용자 정의 type을 만들고, 이 type의 결과 집합을 반환하는 Pipe-lined function을 다음과 같이 생성한다.
-- 1. TYPE 생성 (Pipe-Lined function에서 return하기 위함)
CREATE OR REPLACE TYPE TP_ROWID_RANGE AS OBJECT (
START_ROWID VARCHAR2(50)
,END_ROWID VARCHAR2(50)
);
CREATE OR REPLACE TYPE TL_ROWID_RANGE AS TABLE OF TP_ROWID_RANGE;
-- 2. Function 생성
CREATE OR REPLACE FUNCTION FN_SPLIT_BY_ROWID(
I_OWNER IN VARCHAR2, I_TABLE_NAME IN VARCHAR2, I_CHUNKS IN NUMBER)
RETURN TL_ROWID_RANGE
PIPELINED
AS
CURSOR C_ROWID_RANGE (CP_OWNER VARCHAR2, CP_TABLE_NAME VARCHAR2, CP_CHUNKS NUMBER)
IS
SELECT GRP,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, LO_FNO, LO_BLOCK, 0 ) MIN_RID,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, HI_FNO, HI_BLOCK, 10000 ) MAX_RID
FROM (
SELECT DISTINCT GRP,
FIRST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_FNO,
FIRST_VALUE(BLOCK_ID)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_BLOCK,
LAST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_FNO,
LAST_VALUE(BLOCK_ID+BLOCKS-1)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_BLOCK,
SUM(BLOCKS) OVER (PARTITION BY GRP) SUM_BLOCKS
FROM (
SELECT RELATIVE_FNO, BLOCK_ID, BLOCKS,
TRUNC( (SUM(BLOCKS) OVER (ORDER BY RELATIVE_FNO, BLOCK_ID)-0.01) /
(SUM(BLOCKS) OVER ()/ CP_CHUNKS) ) GRP
FROM DBA_EXTENTS@DL_MS949
WHERE SEGMENT_NAME = UPPER(CP_TABLE_NAME)
AND OWNER = UPPER(CP_OWNER)
ORDER BY BLOCK_ID
)
),
(SELECT DATA_OBJECT_ID
FROM DBA_OBJECTS@DL_MS949
WHERE OWNER = UPPER(CP_OWNER)
AND OBJECT_NAME = UPPER(CP_TABLE_NAME))
ORDER BY GRP
;
BEGIN
FOR ROWID_RANGE IN C_ROWID_RANGE(I_OWNER, I_TABLE_NAME, I_CHUNKS) LOOP
PIPE ROW(TP_ROWID_RANGE(ROWID_RANGE.MIN_RID, ROWID_RANGE.MAX_RID));
END LOOP;
RETURN;
END;
/
위 Function에서 사용하는 SQL은 DBA_EXTENTS를 기준으로 하는 Block 단위의 ROWID 분할이고, Thomas Kyte가 제시한 기법을 참조하여 DB Link를 사용하도록 약간 변형하였다.
* 참조 URL: https://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:10498431232211
DB Link는 DL_MS949를 지정하여 사용하였는데, 만약 DB Link도 동적으로 지정하려면 위 function의 cursor SQL을 dynamic SQL로 변형하여 사용하면 가능하다.
이 함수를 이용하여 LEG.SUB_MON_STAT 테이블(총 건수 7,426)을 ROWID로 분할하면 다음과 같다.
-- DL_MS949 DB Link상의 LEG owner, SUB_MON_STAT table에 대해 4개의 Chunk로 ROWID 분할
SELECT ROWNUM RNO, START_ROWID, END_ROWID
FROM TABLE(FN_SPLIT_BY_ROWID('LEG', 'SUB_MON_STAT', 4))
;
| Row# | START_ROWID | END_ROWID |
| 1 | AAAQXFAAEAAAACIAAA | AAAQXFAAEAAAAC3CcQ |
| 2 | AAAQXFAAEAAAAC4AAA | AAAQXFAAEAAAADHCcQ |
| 3 | AAAQXFAAEAAAADIAAA | AAAQXFAAEAAAADXCcQ |
| 4 | AAAQXFAAEAAAADYAAA | AAAQXFAAEAAAADnCcQ |
여기에서 생성된 ROWID로 데이터를 분할할 때 전체 데이터에서 누락이 없는지 아래 SQL로 확인해 보자.
SELECT R.RNO, COUNT(*) CNT
FROM SUB_MON_STAT S
,(
SELECT 1 RNO, 'AAAQXFAAEAAAACIAAA' START_ROWID, 'AAAQXFAAEAAAAC3CcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 2 RNO, 'AAAQXFAAEAAAAC4AAA' START_ROWID, 'AAAQXFAAEAAAADHCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 3 RNO, 'AAAQXFAAEAAAADIAAA' START_ROWID, 'AAAQXFAAEAAAADXCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 4 RNO, 'AAAQXFAAEAAAADYAAA' START_ROWID, 'AAAQXFAAEAAAADnCcQ' END_ROWID FROM DUAL
) R
WHERE S.ROWID BETWEEN R.START_ROWID AND END_ROWID
GROUP BY R.RNO
ORDER BY R.RNO
;
실행결과는 다음과 같다. (테스트 환경마다 CNT는 달라질 수 있다.)
| RNO(chunk no) | CNT |
| 1 | 1,790 |
| 2 | 2,206 |
| 3 | 2,209 |
| 4 | 1,221 |
CNT의 합은 7,426으로 테이블 전체 Row 수와 동일하여 누락이 없음을 확인할 수 있다. 여기에서 각 RNO로 분할된 Row수는 각각 1790, 2206, 2209, 1221로 균등하지는 않다. 이는 ROWID 분할 방법에서 기술한 균등분할되지 않는 이유와 같다.
4.3. 테스트 환경 및 테스트 테이블 생성
Target DB <ORAUTF>에서 <DL_MS949> DB Link를 이용하여 Source DB <ORAMSWIN949>의 <SUB_MON_STAT> table을 <SUB_MON_STAT_COPY>로 가져오는 테스트 시나리오를 가정하고, 다음의 환경 구성으로 진행한다.
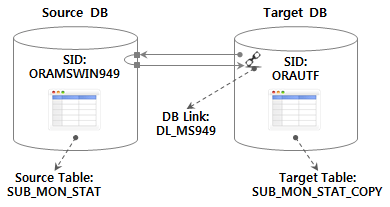
Target DB의 <SUB_MON_STAT_COPY> table은 다음 DDL로 미리 생성한다.
CREATE TABLE SUB_MON_STAT_COPY AS SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM, RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT FROM SUB_MON_STAT@DL_MS949 WHERE 1=2;
4.4. 작업 생성
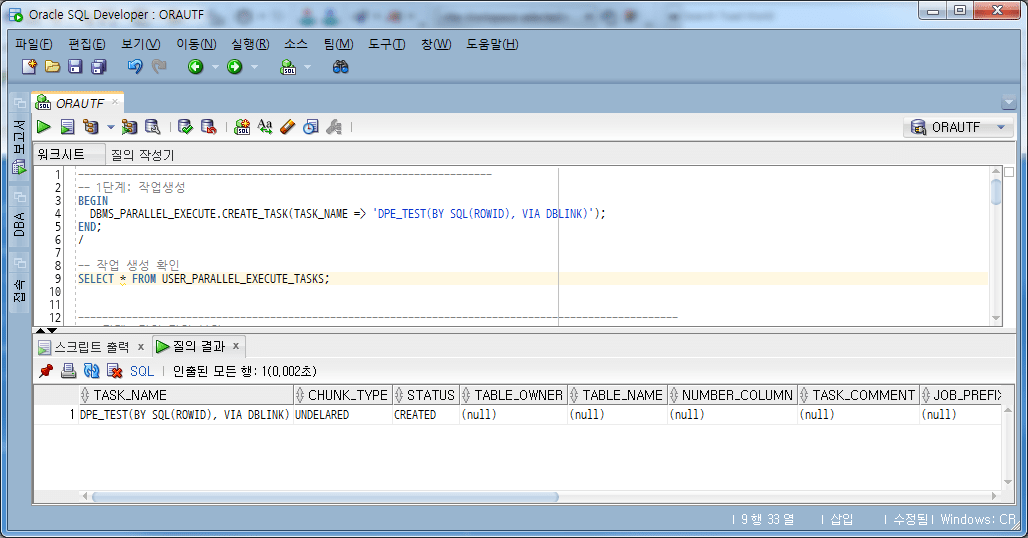
4.4.1. 작업생성
-- 1단계: 작업생성 BEGIN DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; / -- 작업 생성 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
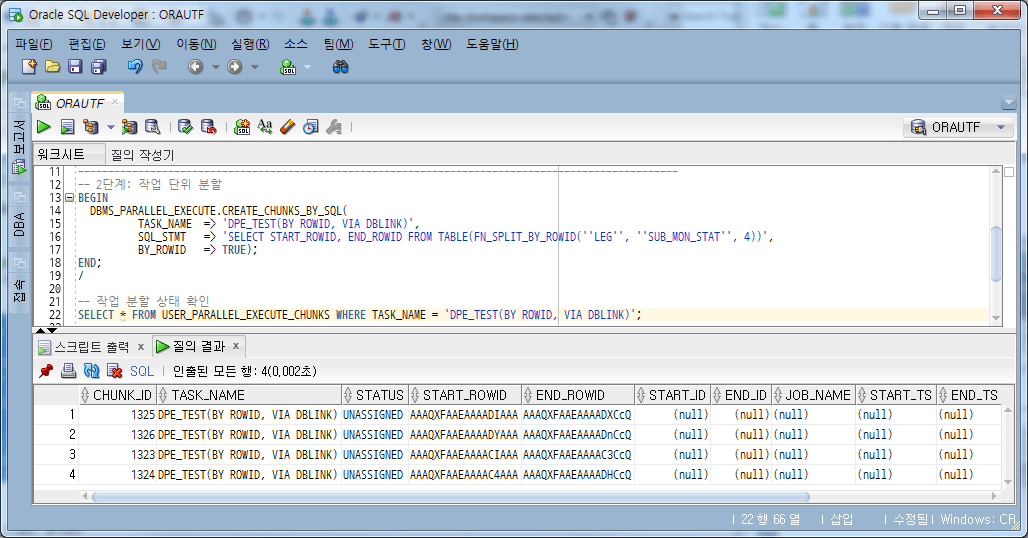
4.4.2. 작업 단위 분할
FN_SPLIT_BY_ROWID 함수를 이용하여, 작업단위를 4로 지정/분할한다.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(
TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => 'SELECT START_ROWID, END_ROWID FROM TABLE(FN_SPLIT_BY_ROWID(''LEG'', ''SUB_MON_STAT'', 4))',
BY_ROWID => TRUE);
END;
/
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
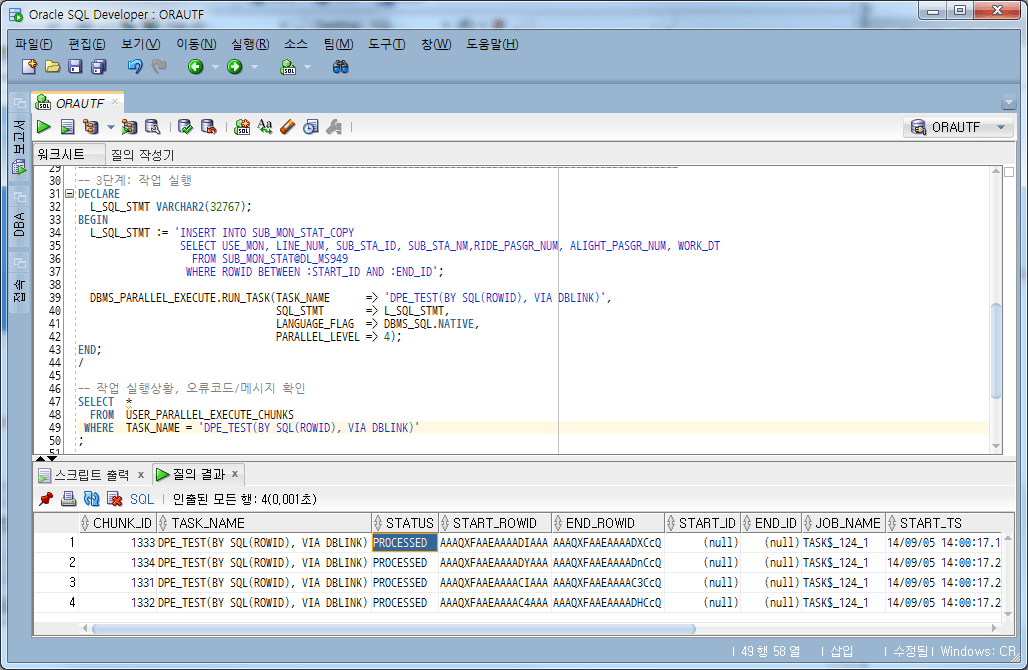
4.5. 작업 실행
ROWID 조건을 WHERE 절에 지정하여 작업을 실행한다. 여기에서는 작업의 수를 작업단위 개수와 동일하게 4로 지정하였다.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'INSERT INTO SUB_MON_STAT_COPY
SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM,RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT
FROM SUB_MON_STAT@DL_MS949
WHERE ROWID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 4);
END;
/
-- 작업 실행상황, 오류코드/메시지 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
4.6. 작업 완료 확인 및 삭제
다음 SQL로 작업완료를 확인할 수 있다.
-- 작업 완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;

DROP_TASK(<TASK_NAME>)로 작업을 삭제한다.
-- 4단계: 작업삭제 BEGIN DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; /
5. 고려사항
- Target table이 partitioned table이고 DML이 INSERT인 경우
- partition 개수만큼 분할하고 partition key 단위로 데이터 처리시 Direct Path I/O가 가능할 것으로 생각한다. (테스트는 안해봤으나, 가능할 듯)
- INSERT 구문에 /*+ APPEND */ hint 사용과 partition을 NOLOGGING으로 지정 필요
- Target table이 non-partitioned table인 경우
- Direct Path I/O가 불가능하고 conventional I/O만 가능함
- UNDO의 양이 상당히 커질 수 있으므로 미리 storage 여유공간 확보 필요함
- chunk의 크기를 작게 설정하면 UNDO의 크기를 어느 정도 제한할 수 있을 것임
이상으로 DBMS_PARALLEL_EXECUTE의 활용 방법에 대해 살펴보았다. 몇년 전 한 프로젝트에서 CLOB 컬럼이 포함된 테이블을 DB Link를 통하여 병렬로 loading하기 위해 찾다가 알게 된 방법이다. 활용하고자 하는 분께 충분히 잘 설명되었기를 바란다.
궁금한 점은 댓글로 남겨주기 바란다.
관련 글:
 Oracle Character Set 변환(7): 5.4. KO16MSWIN949 환경 CSSCAN 실행 결과
Oracle Character Set 변환(7): 5.4. KO16MSWIN949 환경 CSSCAN 실행 결과
 Oracle Character Set 변환(6): 5.3. US7ASCII 환경 CSSCAN 실행 결과
Oracle Character Set 변환(6): 5.3. US7ASCII 환경 CSSCAN 실행 결과
 Oracle Character Set 변환(5): 5. Oracle 권장 방법
Oracle Character Set 변환(5): 5. Oracle 권장 방법
 DBMS_PARALLEL_EXECUTE 설명글 목차
DBMS_PARALLEL_EXECUTE 설명글 목차
 3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 2.5. 작업 단위 분할 상세 확인 (DBMS_PARALLEL_EXECUTE)
2.5. 작업 단위 분할 상세 확인 (DBMS_PARALLEL_EXECUTE)
 2. ROWID 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
2. ROWID 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)
1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)









