4. User-defined SQL partitioning method parallel processing case (DBMS_PARALLEL_EXECUTE)
Let's take a look at the case of user-defined SQL partitioning parallelism using Oracle DBMS_PARALLEL_EXECUTE. It covers writing user-defined SQL, test environment, job creation, job division, job execution, job completion confirmation and deletion.
This is a continuation of the previous article.
3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
* Reference Oracle documentation: DBMS_PARALLEL_EXECUTE – CREATE_CHUNKS_BY_SQL Procedure (oracle.com)
4. User Defined SQL Partitioning Parallel Processing Case
4.1. Overview of custom SQL partitioning methods
Partitioning through user-defined SQL is useful in the following cases.
- Partitioning in cases where the ROWID partitioning method does not support (e.g. ROWID partitioning for remote tables via DB Link)
- Split based on columns other than NUMBER column (VARCHAR2, DATE, etc.)
Here, we will explain the case of ROWID division through DB Link in the first case.
If you try to split the ROWID of a table through DB Link using CREATE_CHUNKS_BY_ROWID , An error occurs.
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)');
END;
/
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE
.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)',
TABLE_OWNER => USER,
-- TABLE _NAME을 “T1@DL_MS949”로 DB Link 지정
TABLE_NAME => 'T1@DL_MS949',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
--> 실행 오류 메시지
ORA-29491: 조각에 부적합한 테이블
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 27행
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 121행
ORA-06512: 4행
In this case, SQL that divides the ROWID of the table on the DB Link can be created and applied through CREATE_CHUNKS_BY_SQL.
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL ( task_name IN VARCHAR2, sql_stmt IN CLOB, by_rowid IN BOOLEAN);
sql_stmt is a CLOB type and can be used with almost no restrictions on its length, but here we suggest a way to use a pipe-lined function rather than directly describe SQL.
4.2. Writing custom SQL
Create a user-defined type and create a pipe-lined function that returns a result set of this type as follows.
-- 1. TYPE 생성 (Pipe-Lined function에서 return하기 위함)
CREATE OR REPLACE TYPE TP_ROWID_RANGE AS OBJECT (
START_ROWID VARCHAR2(50)
,END_ROWID VARCHAR2(50)
);
CREATE OR REPLACE TYPE TL_ROWID_RANGE AS TABLE OF TP_ROWID_RANGE;
-- 2. Function 생성
CREATE OR REPLACE FUNCTION FN_SPLIT_BY_ROWID(
I_OWNER IN VARCHAR2, I_TABLE_NAME IN VARCHAR2, I_CHUNKS IN NUMBER)
RETURN TL_ROWID_RANGE
PIPELINED
AS
CURSOR C_ROWID_RANGE (CP_OWNER VARCHAR2, CP_TABLE_NAME VARCHAR2, CP_CHUNKS NUMBER)
IS
SELECT GRP,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, LO_FNO, LO_BLOCK, 0 ) MIN_RID,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, HI_FNO, HI_BLOCK, 10000 ) MAX_RID
FROM (
SELECT DISTINCT GRP,
FIRST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_FNO,
FIRST_VALUE(BLOCK_ID)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_BLOCK,
LAST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_FNO,
LAST_VALUE(BLOCK_ID+BLOCKS-1)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_BLOCK,
SUM(BLOCKS) OVER (PARTITION BY GRP) SUM_BLOCKS
FROM (
SELECT RELATIVE_FNO, BLOCK_ID, BLOCKS,
TRUNC( (SUM(BLOCKS) OVER (ORDER BY RELATIVE_FNO, BLOCK_ID)-0.01) /
(SUM(BLOCKS) OVER ()/ CP_CHUNKS) ) GRP
FROM DBA_EXTENTS@DL_MS949
WHERE SEGMENT_NAME = UPPER(CP_TABLE_NAME)
AND OWNER = UPPER(CP_OWNER)
ORDER BY BLOCK_ID
)
),
(SELECT DATA_OBJECT_ID
FROM DBA_OBJECTS@DL_MS949
WHERE OWNER = UPPER(CP_OWNER)
AND OBJECT_NAME = UPPER(CP_TABLE_NAME))
ORDER BY GRP
;
BEGIN
FOR ROWID_RANGE IN C_ROWID_RANGE(I_OWNER, I_TABLE_NAME, I_CHUNKS) LOOP
PIPE ROW(TP_ROWID_RANGE(ROWID_RANGE.MIN_RID, ROWID_RANGE.MAX_RID));
END LOOP;
RETURN;
END;
/
The SQL used in the above function is ROWID division in block units based on DBA_EXTENTS, and was slightly modified to use DB Link by referring to the technique suggested by Thomas Kyte.
* Reference URL: https://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:10498431232211
DB Link was used by specifying DL_MS949. If you want to dynamically designate DB Link as well, you can change the cursor SQL of the above function to dynamic SQL and use it.
If the LEG.SUB_MON_STAT table (total number of 7,426) is partitioned by ROWID using this function, it is as follows.
-- DL_MS949 DB Link상의 LEG owner, SUB_MON_STAT table에 대해 4개의 Chunk로 ROWID 분할
SELECT ROWNUM RNO, START_ROWID, END_ROWID
FROM TABLE(FN_SPLIT_BY_ROWID('LEG', 'SUB_MON_STAT', 4))
;
| Row# | START_ROWID | END_ROWID |
| 1 | AAAQXFAAEAAAACIAAA | AAAQXFAAEAAAAC3CcQ |
| 2 | AAAQXFAAEAAAAC4AAA | AAAQXFAAAEAAAADHCcQ |
| 3 | AAAQXFAAAEAAAADIAAA | AAAQXFAAAEAAAADXCcQ |
| 4 | AAAQXFAAEAAAADYAAA | AAAQXFAAAEAAAADnCcQ |
When splitting data with the ROWID generated here, check whether there are any omissions in the entire data with the SQL below.
SELECT R.RNO, COUNT(*) CNT
FROM SUB_MON_STAT S
,(
SELECT 1 RNO, 'AAAQXFAAEAAAACIAAA' START_ROWID, 'AAAQXFAAEAAAAC3CcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 2 RNO, 'AAAQXFAAEAAAAC4AAA' START_ROWID, 'AAAQXFAAEAAAADHCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 3 RNO, 'AAAQXFAAEAAAADIAAA' START_ROWID, 'AAAQXFAAEAAAADXCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 4 RNO, 'AAAQXFAAEAAAADYAAA' START_ROWID, 'AAAQXFAAEAAAADnCcQ' END_ROWID FROM DUAL
) R
WHERE S.ROWID BETWEEN R.START_ROWID AND END_ROWID
GROUP BY R.RNO
ORDER BY R.RNO
;
The execution result is as follows. (CNT may vary for each test environment.)
| RNO (chunk no) | CNT |
| 1 | 1,790 |
| 2 | 2,206 |
| 3 | 2,209 |
| 4 | 1,221 |
The sum of CNT is 7,426, which is equal to the total number of rows in the table, confirming that there is no omission. Here, the number of rows divided into each RNO is 1790, 2206, 2209, and 1221, respectively, which are not equal. This is the same as the reason for not being equally partitioned as described in the ROWID partitioning method.
4.3. Create test environment and test table
Target DB at
- Source DB using DB Link of table Assuming a test scenario imported into , proceed to the following environment configuration.
- When the target table is a partitioned table and the DML is an INSERT
- When partitioning by the number of partitions and processing data in units of partition keys, Direct Path I/O is expected to be possible. (I haven't tested it, but it seems possible)
- Need to use /*+ APPEND */ hint in INSERT syntax and set partition to NOLOGGING
- If the target table is a non-partitioned table
- Direct Path I/O is not possible and only conventional I/O is possible
- Since the amount of UNDO can be quite large, it is necessary to secure free storage space in advance.
- If you set the chunk size to a small size, you will be able to limit the size of UNDO to some extent.
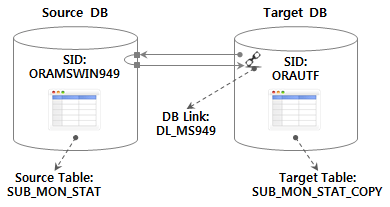
Target DB The table is created in advance with the following DDL.
CREATE TABLE SUB_MON_STAT_COPY AS SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM, RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT FROM SUB_MON_STAT@DL_MS949 WHERE 1=2;
4.4. create job
4.4.1. create job
-- 1단계: 작업생성 BEGIN DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; / -- 작업 생성 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
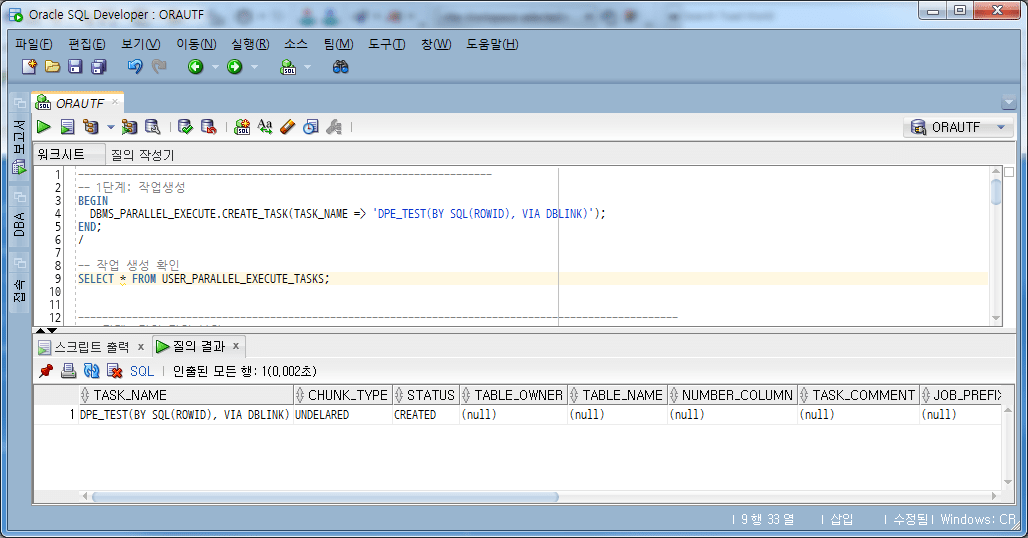
4.4.2. Split work unit
Using the FN_SPLIT_BY_ROWID function, designate/split the work unit into 4.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(
TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => 'SELECT START_ROWID, END_ROWID FROM TABLE(FN_SPLIT_BY_ROWID(''LEG'', ''SUB_MON_STAT'', 4))',
BY_ROWID => TRUE);
END;
/
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
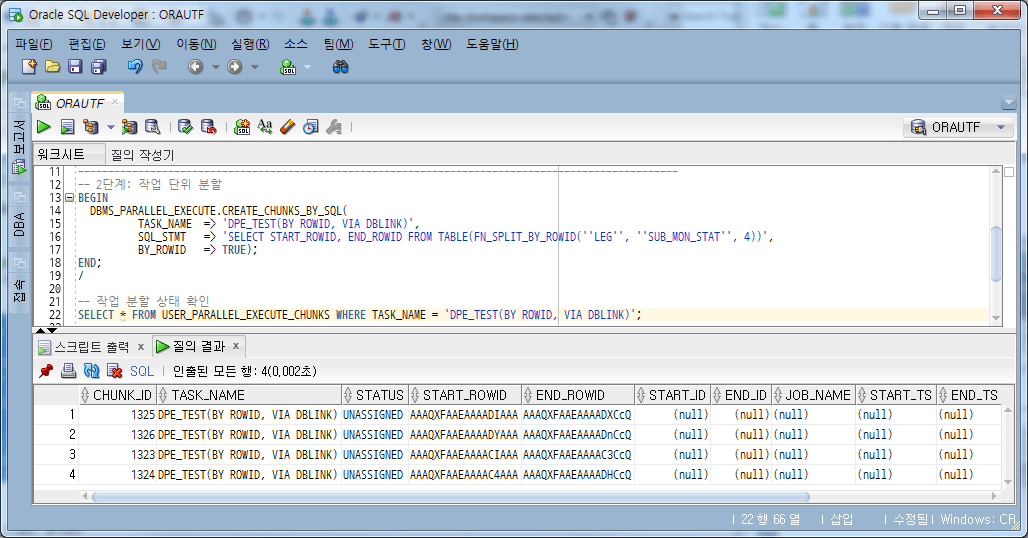
4.5. job run
Execute the task by specifying the ROWID condition in the WHERE clause. Here, the number of tasks is set to 4, the same as the number of work units.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'INSERT INTO SUB_MON_STAT_COPY
SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM,RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT
FROM SUB_MON_STAT@DL_MS949
WHERE ROWID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 4);
END;
/
-- 작업 실행상황, 오류코드/메시지 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
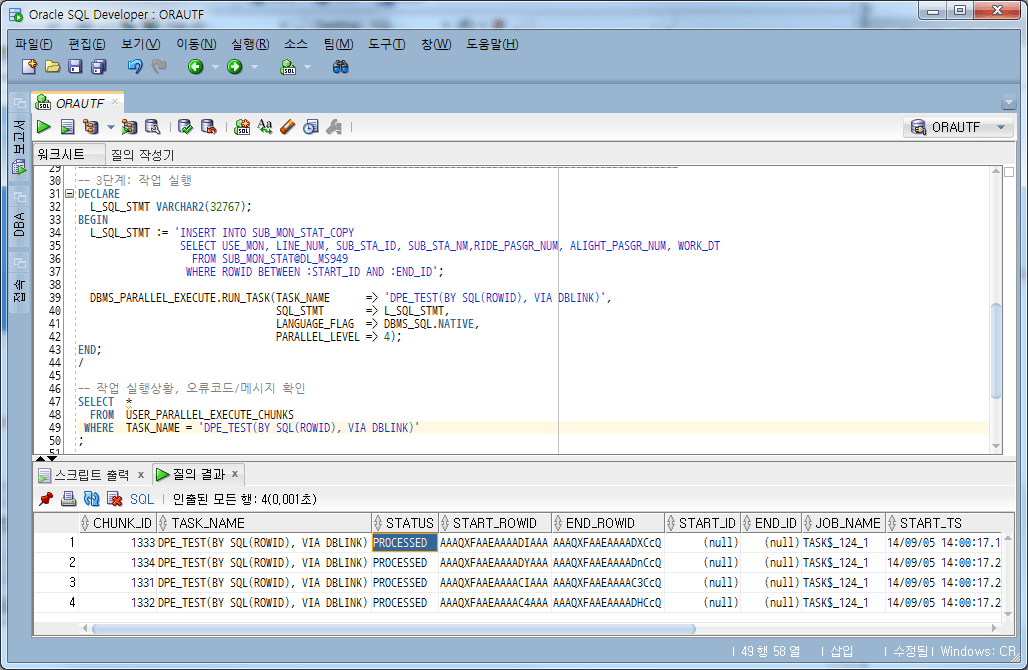
4.6. Confirm task completion and delete
You can check the job completion with the following SQL.
-- 작업 완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;

DROP_TASK( ) to delete the job.
-- 4단계: 작업삭제 BEGIN DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; /
5. Considerations
Above, we looked at how to use DBMS_PARALLEL_EXECUTE. This is a method I found while searching for parallel loading of tables containing CLOB columns in a project a few years ago through DB Link. I hope I explained it well enough for anyone who wants to use it.
If you have any questions, please leave them in the comments.
Related articles:
 Oracle Character Set Conversion (7): 5.4. KO16MSWIN949 Environment CSSCAN Execution Result
Oracle Character Set Conversion (7): 5.4. KO16MSWIN949 Environment CSSCAN Execution Result
 Oracle Character Set Conversion (6): 5.3. US7ASCII environment CSSCAN execution result
Oracle Character Set Conversion (6): 5.3. US7ASCII environment CSSCAN execution result
 Oracle Character Set Conversion (5): 5. Oracle Recommended Practice
Oracle Character Set Conversion (5): 5. Oracle Recommended Practice
 DBMS_PARALLEL_EXECUTE Description Table of Contents
DBMS_PARALLEL_EXECUTE Description Table of Contents
 3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
 2.5. Detailed check of unit of work partitioning (DBMS_PARALLEL_EXECUTE)
2.5. Detailed check of unit of work partitioning (DBMS_PARALLEL_EXECUTE)
 2. ROWID partitioning parallel processing case (DBMS_PARALLEL_EXECUTE)
2. ROWID partitioning parallel processing case (DBMS_PARALLEL_EXECUTE)
 1. Overview of parallel processing of DML jobs (DBMS_PARALLEL_EXECUTE)
1. Overview of parallel processing of DML jobs (DBMS_PARALLEL_EXECUTE)









