2. ROWID 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
Oracle DBMS_PARALLEL_EXECUTE 를 활용하여 ROWID 분할 방식 병렬 처리 사례에 대해 살펴본다.
이전 글에서 이어지는 내용이다.
1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)
2. ROWID 분할 방식 병렬 처리 사례
2.1. ROWID 분할 방식 병렬 처리 작업 생성
CREATE_TASK(<TASK_NAME>)으로 작업을 생성한다.
-- 1단계: 작업생성 BEGIN DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY ROWID)'); END; /
작업이 생성된 결과는 다음과 같이 확인할 수 있다.
-- 작업 생성 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;

위 결과에서 Task가 생성되었고, STATUS는 CREATED 임을 확인할 수 있다.
참고로, Task의 STATUS는 CHUNKED, CHUNKING, CHUNKING_FAILED, CRASHED, CREATED, FINISHED, FINISHED_WITH_ERROR, PROCESSING의 값을 가지며, 각 의미는 다음과 같다.
- CHUNKED: chunk가 생성되고, 아직 작업에 할당되지 않음
- CHUNKING: chunk 생성 중
- CHUNKING_FAILED: chunk 생성 중 실패
- CRASHED: Task 실행 중 데이터베이스 crash 또는 job process의 crash가 발생하여 error를 기록하지 못하고 종료됨
- REATED: Task가 생성됨(아직 chunk는 생성되지 않음)
- FINISHED: 모든 chunk가 오류 없이 완료함
- FINISHED_WITH_ERROR: 모든 chunk를 완료했으나, 일부 오류가 발생함
- PROCESSING: Tosk가 실행을 시작했고, chunk의 일부는 진행 중이거나 완료 상태임
* 참조: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS67333
2.2. 작업 단위 분할
CREATE_CHUNKS_BY_ROWID(<TASK_NAME>, <TABLE_OWNER>, <TABLE_NAME>, <BY_ROW>, <CHUNK_SIZE>)로 작업 단위를 분할한다.
<BY_ROW>는 BOOLEAN type으로 TRUE이면 <CHUNK_SIZE>가 Row Count를 의미하고, FALSE이면 Block Count를 의미한다.
Z_DPE_TEST_TAB 테이블의 Row count를 10,000건씩으로 분할하는 chunk를 생성하려면 다음과 같이 실행한다.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
작업 단위의 분할 상태를 확인해 보자.
-- 작업 분할 상태 확인 SELECT * FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
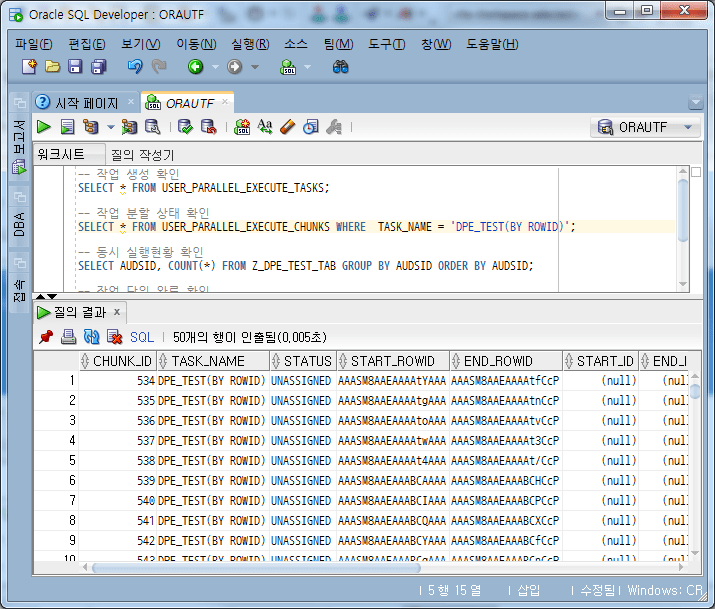
분할된 시점의 각 chunk의 STATUS가 UNASSIGNED로 되어 있음을 확인할 수 있다. 참고로, chunk의 STATUS는 UNASSIGNED, ASSIGNED, PROCESSED, PROCESSED_WITH_ERROR 의 값을 가지며, 각 의미는 다음과 같다.
- UNASSIGNED: chunk가 생성되고, 아직 작업에 할당되지 않음
- ASSIGNED: chunk가 작업에 할당되어 실행 중임
- PROCESSED: 작업이 오류 없이 완료되었음
- PROCESSED_WITH_ERROR: 작업이 완료되었으나 실행 중 오류가 발생함
* 참조: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS67333
2.3. 작업 실행
RUN_TASK(<TASK_NAME>, <SQL_STMT>, <LANGUAGE_FLAG>, <PARALLEL_LEVEL>)로 작업을 실행한다.
여기에서 LANGUAGE_FLAG는 Oracle이 SQL_STMT를 처리할 기준 version의 의미이며, default로 DBMS_SQL.NATIVE 를 사용하면 된다.
참고로, Oracle Document의 내용은 다음과 같다.
- V6 (or 0) specifies version 6 behavior
- NATIVE (or 1) specifies normal behavior for the database to which the program is connected
- V7 (or 2) specifies Oracle database version 7 behavior
PARALLEL_LEVEL은 동시에 실행할 작업(job)의 개수, 즉 병렬도(DOP, Degree Of Parallelism)를 의미하며, 작업 단위인 chunk의 개수와 같을 수도 있고, 작을 수도 있다. 같은 경우는 하나의 job이 하나의 chunk를 처리하고, 작은 경우는 하나의 job이 여러 개의 chunk를 처리하게 된다.
-- 동시 실행현황 확인: 작업 실행전 SELECT AUDSID, COUNT(*) FROM Z_DPE_TEST_TAB GROUP BY AUDSID ORDER BY AUDSID;
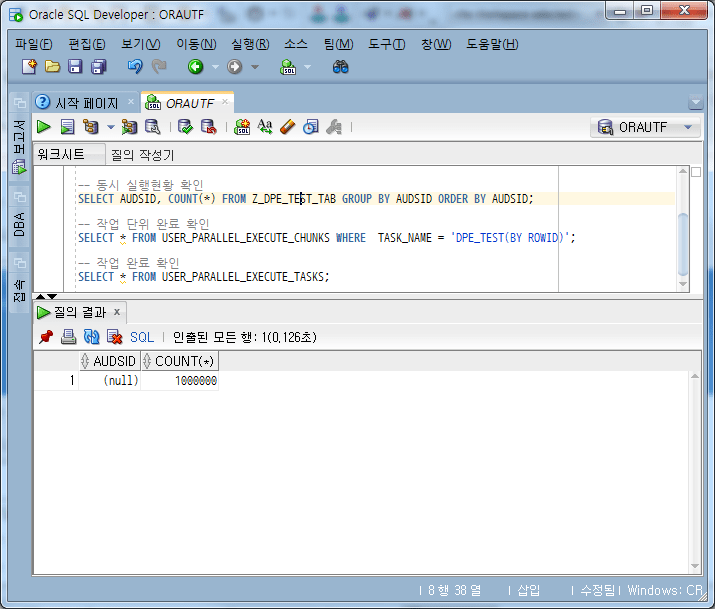
작업 실행 전에 AUDSID별로 COUNT를 확인해 보면, 모든 데이터가 null로 설정되어, 아직 실행되지 않았음을 확인할 수 있다.
이제 작업을 실행해 보자.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'UPDATE Z_DPE_TEST_TAB
SET VAL = ROUND(DBMS_RANDOM.VALUE(1,10000))
,AUDSID = SYS_CONTEXT(''USERENV'',''SESSIONID'')
WHERE ROWID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY ROWID)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 10);
END;
/
실행하는 SQL은 두개의 bind 변수 :START_ID와 :END_ID로 실행 범위를 지정한다. 이 변수명은 다르게 사용하면 오류가 발생하니 꼭 이 이름을 사용하도록 한다.
여기에서 실행하는 SQL은 테스트를 위하여 VAL 컬럼에는 random value를 update하고 AUDSID 컬럼에는 현재 SESSIONID 값을 update하여 어떤 session에서 현재 행을 update했는지 확인하도록 작성하였다.
참고로 AUDSID 컬럼은 V$SESSION.AUDSID와 같은 의미이다. 각 chunk 단위 작업이 오래 걸리는 경우 V$SESSION을 AUDSID로 조회하여 Session monitoring을 할 수 있다.
실행중에 다음 SQL을 실행해 보면 몇 개의 Session에서 몇 개의 행을 update하고 있는지 확인할 수 있다.
-- 동시 실행현황 확인: 작업 실행중 SELECT AUDSID, COUNT(*) FROM Z_DPE_TEST_TAB GROUP BY AUDSID ORDER BY AUDSID;
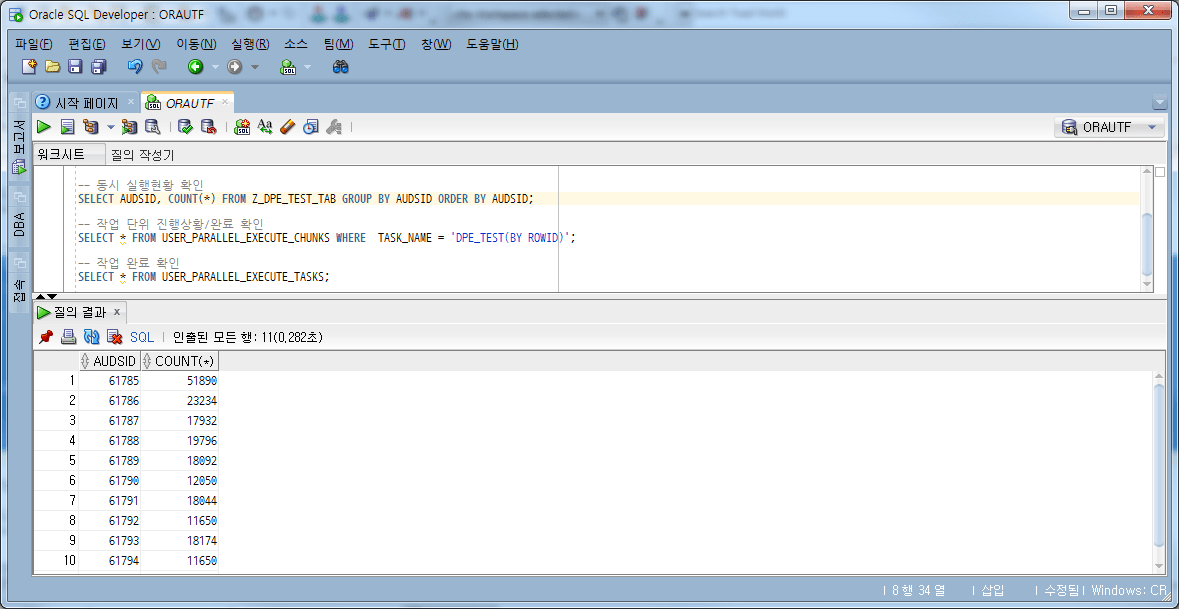
Session 단위가 아닌 작업이 분할된 chunk별 진행상황을 확인해 보자.
-- 작업의 Chunk별 진행상황/완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
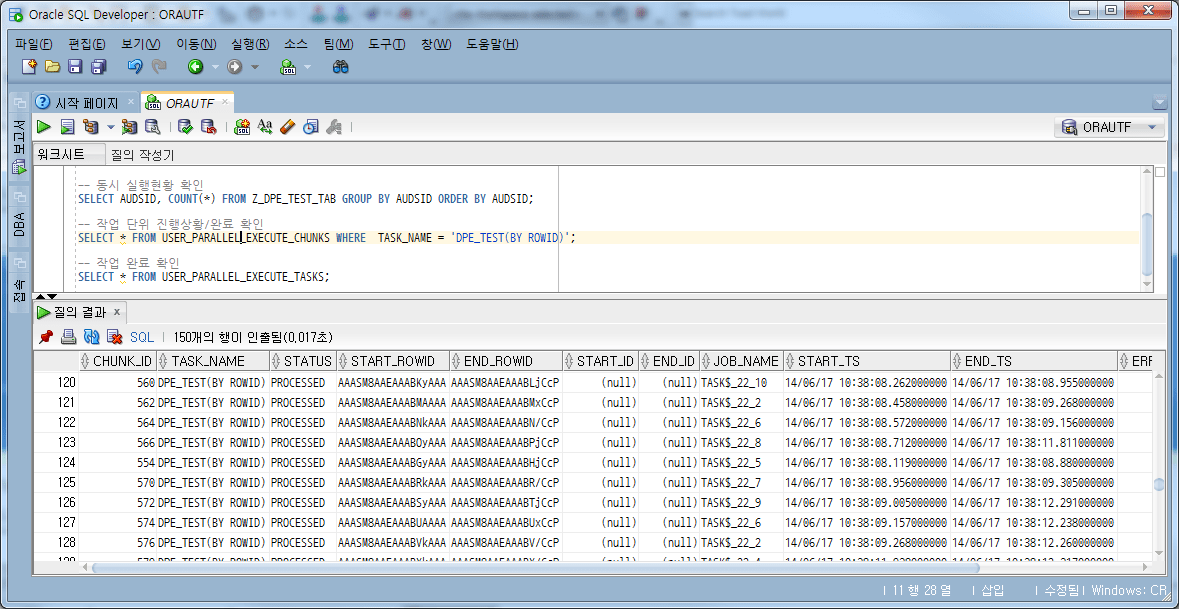
위 결과에서 STATUS가 PROCESSED로 변경되고, START_TS(시작 시각), END_TS(종료 시각)가 관리됨을 확인할 수 있다.
Chunk 상태별로 진행상태를 확인하려면 다음 SQL을 실행한다.
-- Chunk의 상태별 진행상황 SELECT STATUS, COUNT(*) FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)' GROUP BY STATUS;
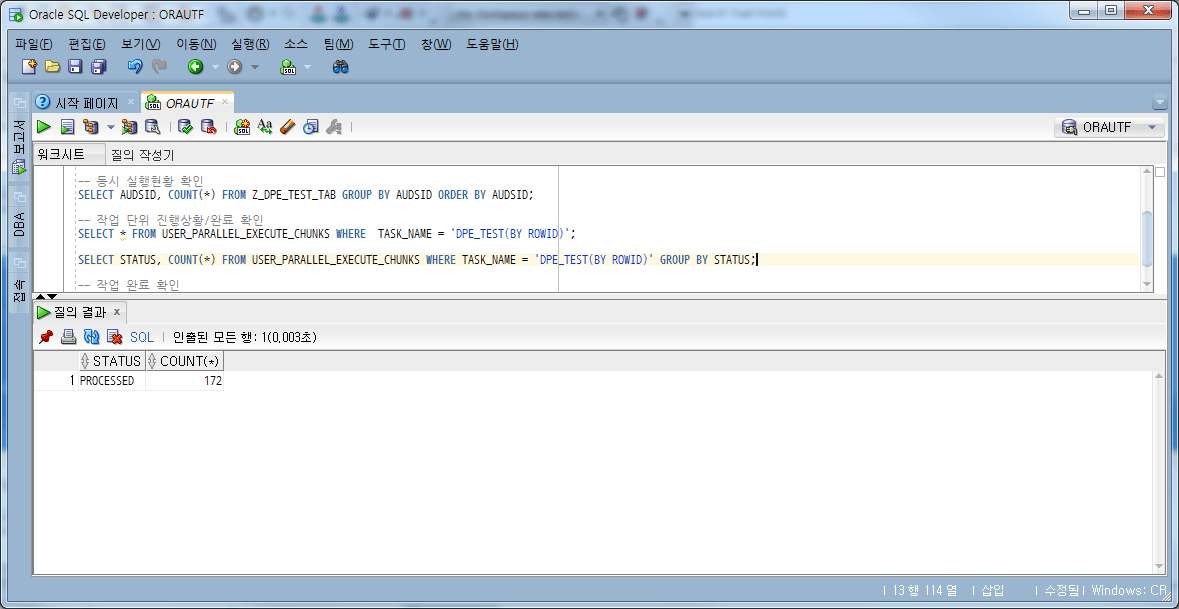
위 결과에서 172개 chunk에 대해 PROCESSED 상태로 완료되었음을 확인할 수 있다. 작업이 완료된 후에 캡처한 이미지라서 하나의 상태만 기록되었다. 작업이 오래 걸리는 경우 상태별로 chunk 개수를 확인할 수 있다.
2.4. 작업 완료 확인 및 삭제
DROP_TASK(<TASK_NAME>)로 작업을 삭제한다.
참고로, 삭제하지 않았을 경우, 나중에 동일한 TASK_NAME으로 작업을 생성할 때 ORA-29497: 중복된 작업 이름(DUPLICATE_TASK_NAME) 오류가 발생한다.
-- 작업 완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
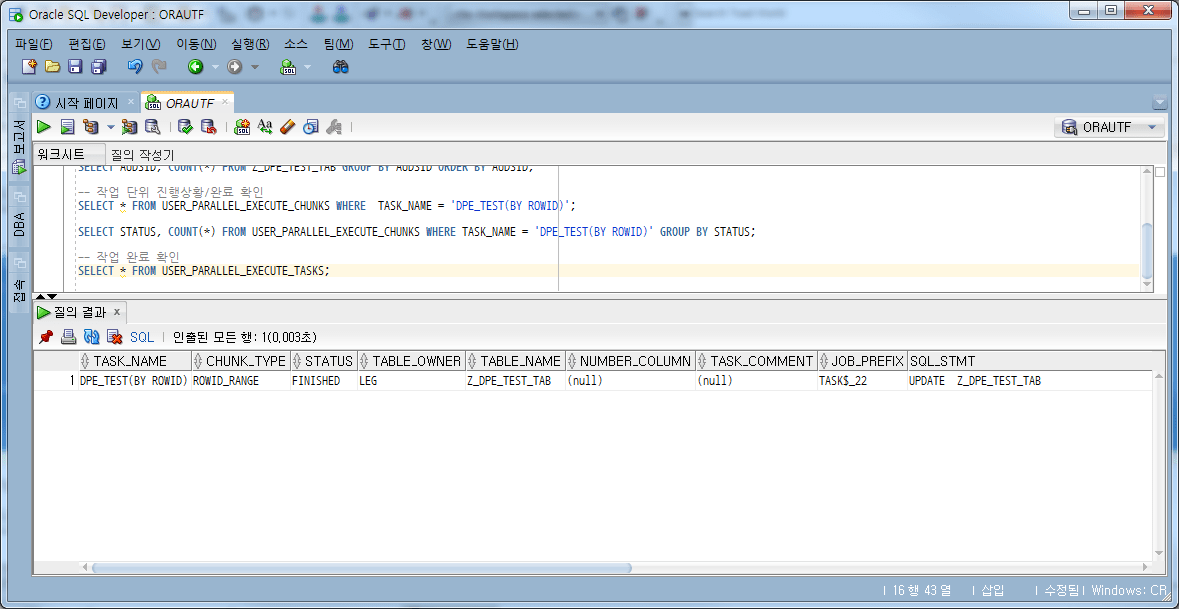
위 결과에서 Task의 STATUS가 FINISHED로 완료되었음을 확인할 수 있다.
-- 4단계: 작업 완료 확인 및 작업 삭제 BEGIN DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY ROWID)'); END; /
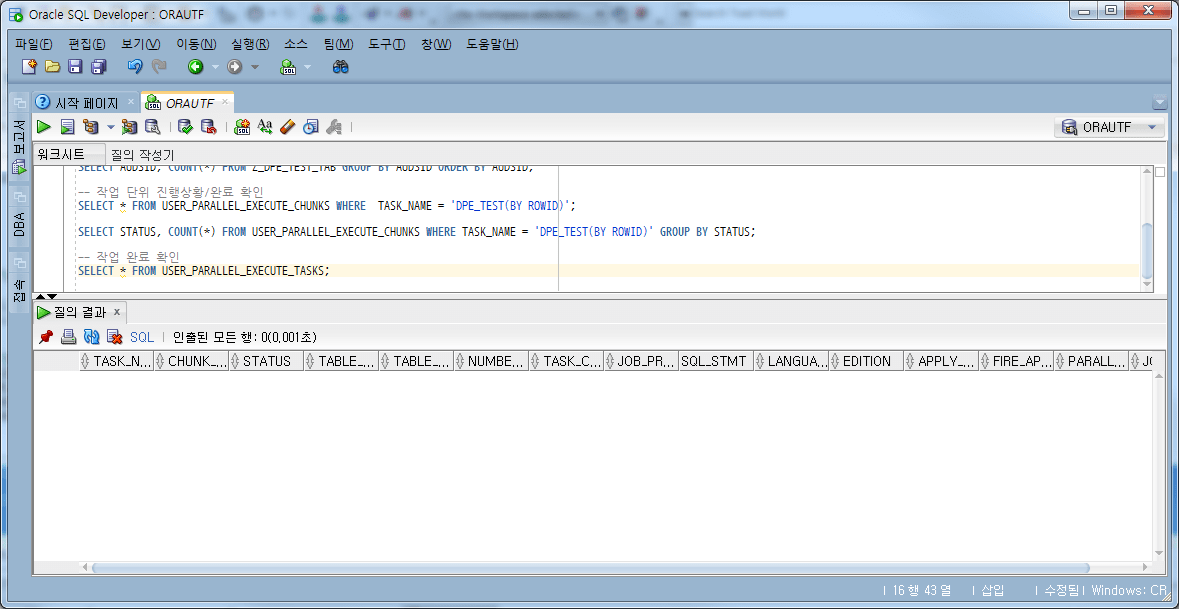
DROP_TASK 실행 후 USER_PARALLEL_EXECUTE_TASKS view를 다시 확인해 보면 작업이 삭제되었음을 확인할 수 있다.
여기까지 ROWID 분할 방식 병렬 처리 작업에 대해 간단한 사례를 살펴보았다.
다음에는 ROWID로 분할한 작업 단위들이 얼마나 균일한지, 누락은 없는지, chunk 수와 job 개수(병렬도)간의 상관관계는 어떠한 지에 대해 살펴본다.
관련 글:
 Oracle Character Set 변환(9): 6. 사용자 구현 Character Set 변환 방법 (2)
Oracle Character Set 변환(9): 6. 사용자 구현 Character Set 변환 방법 (2)
 Oracle Character Set 변환(8): 6. 사용자 구현 Character Set 변환 방법 (1)
Oracle Character Set 변환(8): 6. 사용자 구현 Character Set 변환 방법 (1)
 Oracle Character Set 변환(1): 1. 필요성, 올바른 Oracle Character Set 설정 가이드
Oracle Character Set 변환(1): 1. 필요성, 올바른 Oracle Character Set 설정 가이드
 DBMS_PARALLEL_EXECUTE 설명글 목차
DBMS_PARALLEL_EXECUTE 설명글 목차
 4. 사용자 정의 SQL 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
4. 사용자 정의 SQL 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column 분할 방식 병렬 처리 사례 (DBMS_PARALLEL_EXECUTE)
 2.5. 작업 단위 분할 상세 확인 (DBMS_PARALLEL_EXECUTE)
2.5. 작업 단위 분할 상세 확인 (DBMS_PARALLEL_EXECUTE)
 1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)
1. DML 작업의 병렬 처리 개요 (DBMS_PARALLEL_EXECUTE)










DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID를 이용하여 실행을 했는데, task의 status를 보면 NO_CHUNKS 상태가 보이는데, 혹시 이유를 알수 있을까요?
제가 테스트한 환경은 Oracle 11g R2(11.2)였고, 그 당시에는 NO_CHUNKS 상태는 없었습니다.
구글 검색을 해보니 다음 내용이 있네요.
———————————–
NO_CHUNKS: Table associated with the task has no chunks created
———————————–
* 출처: Oracle 19c 문서
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/DBMS_PARALLEL_EXECUTE.html#GUID-5581516D-AB22-4748-8476-C5BB38BE7E2F
ROWID로 block을 나누었는데 해당 chunk 내의 모든 block이 데이터가 없을 때 NO_CHUNKS 상태일 것 같은데요.
제가 최근에는 Oracle을 사용하지 않아서 테스트가 어렵네요.
참고만 하시기 바랍니다.