Oracle Character Set 변환(1): 1. 필요성, 올바른 Oracle Character Set 설정 가이드
Oracle Character Set 변환 필요성 과 올바른 Character Set 설정 가이드에 대한 내용을 살펴본다.
다수의 차세대 프로젝트에서 Data Migration(데이터 전환, 데이터 이행, 데이터 마이그레이션)과 관련하여 골치아픈 문제 중 하나가 Oracle의 Character Set 변환이다.
대부분 올바르지 못한 Character Set(예: US7ASCII)에서 올바른 Character Set(예: KO16MSWIN949, AL32UTF8 등)으로 변환하고자 하는 요구이다. 특히, 현행 DB의 Character Set이 US7ASCII인 경우가 가장 문제가 크다.
정상적으로 저장되어 있지 않은 데이터를 정상적인 데이터처럼 보여주고 있는 상황이기 때문에 변환에 많은 시행착오를 겪게 된다.
앞으로 몇 개의 글을 통해 검토해 볼만한 방법과 참고할 사항을 공유하고자 한다.
1. Oracle Character Set 변환 필요성
Oracle Character Set을 변환하고자 하는 경우는 아래와 같은 요건이 있기 때문이다.
- 잘못 지정된 Character Set(US7ASCII)
- 초기 국내한정으로 구축된 시스템의 글로벌화 (한글 Character Set에서 Unicode Character Set으로 변환)
1.1. 잘못 지정된 Character Set(US7ASCII)
Oracle을 설치할 때 결정되는 몇 가지 중요한 요소 중 하나가 바로 Character Set이다. Oracle 설치 후 시스템이 구축되어 사용되면서 데이터가 쌓이고 나면 변경하기가 쉽지 않기 때문에, 처음에 잘 설정하는 것이 중요하다.
Oracle을 silent mode로 설치할 때 필요한 response file중 dbca.rsp 파일에 Character set 기본값이 “US7ASCII”으로 되어 있다. 주석으로 처리되어 있고, 설치할 때 이 설정을 정확하게 변경하여 입력해야 하는데, 실수 또는 부주의로 인해 그냥 주석만 해제한 채로 설치하는 경우에 Character Set이 “US7ASCII”로 지정된다.
아래는 dbca.rsp 파일의 Character Set 기본값 설정을 보여준다.
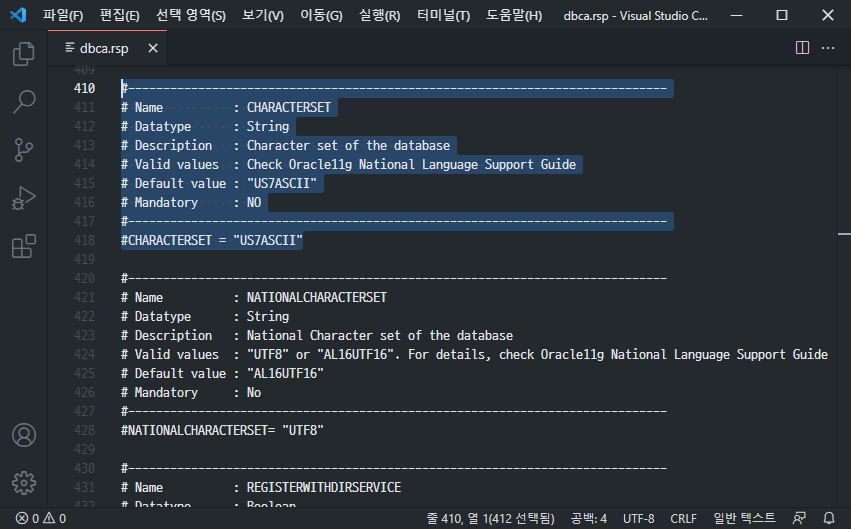
여기에서 혼란을 발생시키는 상황은, “US7ASCII”에서도 한글 입출력이 된다는 것이다. 정확하게 얘기하면 되는 것처럼 동작한다. 한글 데이터를 입력했으나, 정상적으로 저장되어 있지 않은 상태에서도 마치 정상적인 것처럼 한글을 출력할 수 있다.
하지만, 이는 불완전한 상태라서 Application 소스코드에서 한글변환 및 처리 로직이 들어가는 등 불필요한 노력이 필요하고, 따라서 의도하지 않은 오류를 발생시킬 가능성을 가지게 된다.
“US7ASCII”은 시스템의 목적에 따라 Non-Unicode 체계의 “KO16MSWIN949” 또는 Unicode 체계의 “UTF8”, “AL32UTF8″로 전환하는 것을 검토하는 것이 좋다.
1.2. 초기 국내한정으로 구축된 시스템의 글로벌화
“KO16KSC5601” 또는 “KO16MSWIN949″의 Character Set으로 사용중인 시스템에 대해 차세대 프로젝트 등을 통해 글로벌화를 추진하는 경우 한글 Character Set에서 Unicode Character Set으로 변환이 필요하다.
“KO16KSC5601” 또는 “KO16MSWIN949″에서는 다국어 문자를 모두 저장할 수 없기 때문에 Unicode 계열인 “UTF8”, “AL32UTF8″으로 변환해야 한다.
많은 국내업무환경이 글로벌화를 지향하고 있고, 향후 다국어 문자를 저장할 필요성을 완전히 배제할 수 없기 때문에 가급적 Unicode 기반의 Character Set을 사용하는 것이 바람직하다.
만약 설치 후 Application이 구축되기 전이거나 저장된 데이터를 버릴 수 있는 경우는 처음부터 다시 설치하는 것을 권장한다. Character Set 변경에 필요한 노력보다, 재설치의 노력이 훨씬 적게 들고 더 빠르며 안전하다.
2. 올바른 Oracle Character Set 설정 가이드
Oracle Character Set을 Non-Unicode 계열과 Unicode 계열로 나누어 포함관계에 따라 정리하면 다음과 같다.
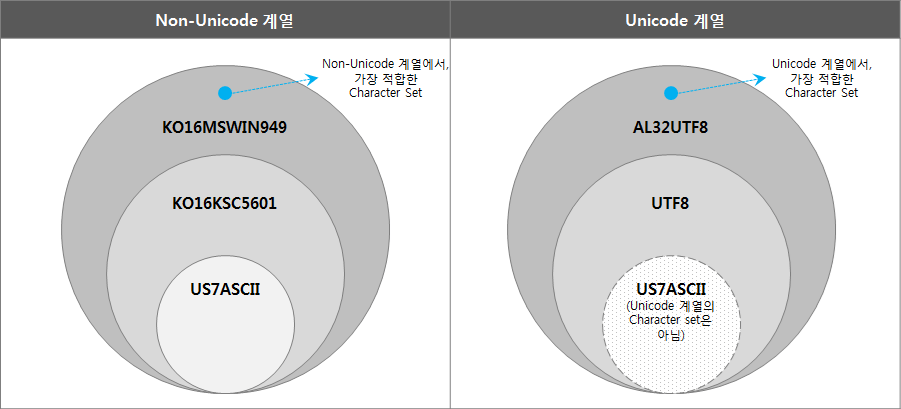
(“US7ASCII”는 Unicode 계열은 아니나 UTF8의 subset 개념으로 포함시켜 표현하였다.)
Oracle Character Set을 올바르게 설정하기 위해서는 간단하게 다음 둘 중에 하나를 선택하면 된다.
| 시스템 유형 | 권장 Character Set | 설명 |
| 대한민국에서만 사용되는 시스템 | KO16MSWIN949 | – 한글 Windows에서 한글IME를 통해 입력할 수 있는 문자는 모두 지원 가능(한글, 한자, 영문, 숫자 등) – 한글과 한자는 2 byte로 저장되고, 영문과 숫자는 1 byte로 저장됨. |
| 다국어 문자를 저장해야 하는 시스템 | AL32UTF8 | – AL32UTF8은 최신 Unicode에서 추가되고 있는 문자들도 모두 지원 가능함(중국 한자, 서유럽 문자, 동남아 문자 등) – 영문과 숫자는 1 byte로 저장되고, 나머지 문자들은 대부분 3 byte로 저장됨. (일부 4 byte로 저장되는 문자가 있으나 거의 사용되지 않는 문자임) |
“KO16MSWIN949″보다 “AL32UTF8″은 문자형의 저장공간이 최대 1.5배(한글만 포함된 경우)가 필요하나, 영문/숫자만 사용되는 데이터(코드, ID, 번호, 순번 등)도 있고, 한글과 영문/숫자가 혼재되는 경우도 많으므로, 정확하지는 않지만 일반적으로 1.3배 정도 저장공간이 증가한다고 볼 수 있다.
Character Set 별로 상세한 내용은 다음을 참조하기 바란다.
*출처: 오라클과 NLS의 찰떡궁합 들여다보기(류정우│한국오라클 WPTG팀) (OTN의 예전 원문 링크는 없어짐)
| KO16KSC5601 | KO16MSWIN949 | UTF8 | AL32UTF8 | |
| 한글 지원상태 | 한글 2350자 | KO16KSC5601 + 확장 8822자(총 11172자) | 한글 11172자 | 한글 11172자 |
| 캐릭터셋/인코딩 버전 | 한글완성형 | 완성형 코드포함 확장된 8822자는 MS Windows Codepage 949에 따라 배열 | 8.1.6 이전 : Unicode 2.1 8.1.7 이후: Unicode 3.0 | 9i Rel1: Unicode 3.0 9i Rel2: Unicode 3.1 10g Rel1: Unicode 3.2 10g Rel2: Unicode 4.0 |
| 한글 바이트 | 2바이트 | 2바이트 | 3바이트 | 3바이트 |
| 지원 버전 | 7.x | 8.0.6 이상 | 8.0 이후 | 9i Release 1 이상 |
| Database Character set으로 설정 가능 여부 | 가능 | 가능 | 가능 | 가능 |
| National Character set으로 설정 가능 여부 | 불가능 | 불가능 | 가능 | 불가능 |
| 한글 정렬 (NLS_SORT 설정) | 단순 바이너리 정렬로 구현 가능 | KOREAN_M 또는 UNICODE_BINARY 등 특수한 옵션 필요 (한글 정렬에 관한 설명 참조) | 한글 정렬은 단순 바이너리 정렬로 가능. 한자 정렬은 KOREAN_M 옵션 필요 | – 한글 지원은 UTF8과 동일 |
| 장점 | – 특별한 장점이 없음. 완성형 코드만을 입출력하는 것이 확실할 경우에는 높은 성능 | – 2바이트로 모든 한글 저장/입출력 가능. 공간의 소모가 적으면서도 모든 한글을 입출력할 수 있다 | – 현대 한글 11172자가 정확한 순서로 배열되어 정렬이 효과적 – 다른 언어들(중국어 태국어 등) 또한 같은 데이타베이스 인스턴스에 저장되어야 할 경우 UTF8 등의 유니코드 캐릭터셋 이외에 다른 대안이 있을 수 없음 | |
| 단점 | – 한글을 2350자밖에 지원하지 못한다는 치명적인 단점이 있어 미래에는 사용이 자제되어야 할 캐릭터셋 | – 완성형과 호환을 하려다보니, 글자배열순서와 정렬 순서가 다르게 됨. 단순한 “ORDER BY” 절로는 제대로 한글 정렬을 할 수 없음 | 한글 한 캐릭터가 3바이트를 소모하게 되어 공간의 소모가 상대적으로 크고(2 바이트에 비해 1.5배), 유니코드 인코딩/디코딩에 성능을 소모해야 한다 |
* “UTF8″은 Unicode 3.0까지만 지원하고, “AL32UTF8″은 Unicode의 최신 버전 및 향후 release될 버전도 지원함.
Oracle document에서도 “AL32UTF8″을 권장하고 있다.
출처: http://docs.oracle.com/cd/E11882_01/server.112/e10729/ch2charset.htm#NLSPG002
일부 내용을 발췌하여 아래에 붙여둔다.
Database Character Set Statement of Direction
A list of character sets has been compiled in Table A-4, “Recommended ASCII Database Character Sets” and Table A-5, “Recommended EBCDIC Database Character Sets” that Oracle strongly recommends for usage as the database character set. Other Oracle-supported character sets that do not appear on this list can continue to be used in Oracle Database 11g Release 2, but may be desupported in a future release. Starting with Oracle Database 11g Release 1, the choice for the database character set is limited to this list of recommended character sets in common installation paths of Oracle Universal Installer and Oracle Database Configuration Assistant. Customers are still able to create new databases using custom installation paths and migrate their existing databases even if the character set is not on the recommended list. However, Oracle suggests that customers migrate to a recommended character set as soon as possible. At the top of the list of character sets that Oracle recommends for all new system deployment, is the Unicode character set AL32UTF8.Choosing Unicode as a Database Character Set
Oracle recommends using Unicode for all new system deployments. Migrating legacy systems to Unicode is also recommended. Deploying your systems today in Unicode offers many advantages in usability, compatibility, and extensibility. Oracle Database enables you to deploy high-performing systems faster and more easily while utilizing the advantages of Unicode. Even if you do not need to support multilingual data today, nor have any requirement for Unicode, it is still likely to be the best choice for a new system in the long run and will ultimately save you time and money as well as give you competitive advantages in the long term. See Chapter 6, “Supporting Multilingual Databases with Unicode” for more information about Unicode.
위 밑줄 친 부분의 내용을 참고하기 바란다.
여기까지 Oracle Character Set 변환 필요성과 올바른 Oracle Character Set을 설정하기 위한 가이드를 살펴보았다. 다음에는 Oracle Character Set 관련 Client 환경 구성을 살펴보겠다.
관련 글:
 Oracle Character Set 변환 설명글 전체 목차
Oracle Character Set 변환 설명글 전체 목차
 Oracle Character Set 변환(10): 6.3. CLOB type 한글 변환 방법
Oracle Character Set 변환(10): 6.3. CLOB type 한글 변환 방법
 Oracle Character Set 변환(9): 6. 사용자 구현 Character Set 변환 방법 (2)
Oracle Character Set 변환(9): 6. 사용자 구현 Character Set 변환 방법 (2)
 Oracle Character Set 변환(8): 6. 사용자 구현 Character Set 변환 방법 (1)
Oracle Character Set 변환(8): 6. 사용자 구현 Character Set 변환 방법 (1)
 Oracle Character Set 변환(7): 5.4. KO16MSWIN949 환경 CSSCAN 실행 결과
Oracle Character Set 변환(7): 5.4. KO16MSWIN949 환경 CSSCAN 실행 결과
 Oracle Character Set 변환(4): 4.테스트 환경 구성
Oracle Character Set 변환(4): 4.테스트 환경 구성
 Oracle Character Set 변환(3): 3. Client 환경 구성(2)
Oracle Character Set 변환(3): 3. Client 환경 구성(2)
 Oracle Character Set 변환(2): 3. Client 환경 구성(1)
Oracle Character Set 변환(2): 3. Client 환경 구성(1)









