1. Overview of parallel processing of DML jobs (DBMS_PARALLEL_EXECUTE)
Introduces DBMS_PARALLEL_EXECUTE, which can be used from Oracle 11g R2, and examines use cases.
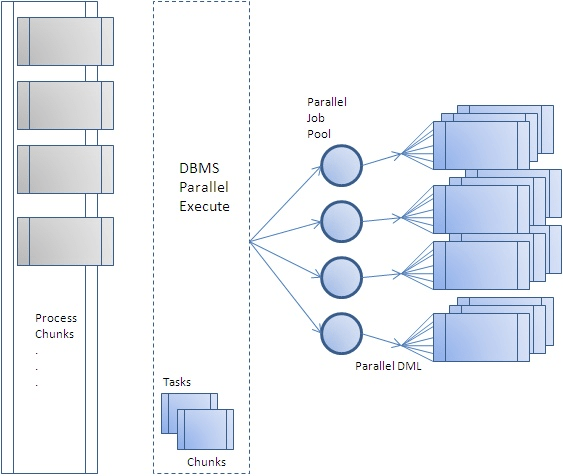
Image source: https://blogs.oracle.com/warehousebuilder/parallel-processing-with-dbmsparallelexecute
1. Overview of Parallel Processing of DML Jobs
1.1. DML Parallel Processing Method
Parallel processing is used when you want to quickly process one DML (INSERT, UPDATE, DELETE) operation in the database using as many resources as possible. There are two main methods of parallel processing.
The first method is to specify the parallel degree as a hint while executing one SQL (Parallel DML, single transaction), and the second method is to execute multiple SQLs by specifying the data range (Program Parallel DML, multi transaction). ) to be.
In most cases, the parallel DML method, which is the first method, is advantageous in terms of data consistency because it is processed as a single transaction. However, it is better to apply the second method in situations where the first method cannot be applied or when you want to define the size or range of the work unit yourself. (So the second method is also called DIY (Do It Yourself) Parallel DML)
The situation in which Parallel DML cannot be applied is, for example, as follows.
- DML to SELECT a table with LOB columns
- DML on DB Link
- Parallel processing DML in PL/SQL units rather than SQL units or procedures implemented as complex procedures
- DML that is not implemented in PL/SQL but runs in languages such as Java
The steps for executing Program Parallel DML may vary slightly depending on the situation, but in general, they are as follows.
- Selection of work targets
- Selection of parallelism and division of work units (Partition, date, number, ROWID, etc.) -> Creation of .sql files by work units
- Task Execution and Monitoring -> Execute each .sql file in individual session (SQL*Plus, etc.)
- Confirm task completion -> Verification of row count comparison, sum comparison, etc.
When the degree of parallelism (DOP) is changed or rework is required due to a change in requirements or circumstances, steps 2 and 3 are repeatedly performed and management and verification are not simple. It's inconvenient to have to manually repeat similar tasks over and over again whenever changes are needed.
1.2. DBMS_PARALLEL_EXECUTE concept
When using the Program Parallel method, using DBMS_PARALLEL_EXECUTE can execute and manage this task more conveniently.
* See Oracle Document: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS233
(For reference, DBMS_PARALLEL_EXECUTE uses JOB internally, so CREATE JOB authority must be granted to the executing user.)
DBMS_PARALLEL_EXECUTE is a Package introduced as a new feature in Oracle 11g R2. The list of major sub programs is shown in the following table, and the full list and explanation can be found in the Oracle document.
| Sub program | Explanation |
| CREATE_TASK Procedure | Create a task |
| CREATE_CHUNKS_BY_NUMBER_COL Procedure | Create chunk by NUMBER column |
| CREATE_CHUNKS_BY_ROWID Procedure | Creating chunks with ROWID |
| CREATE_CHUNKS_BY_SQL Procedure | Creating chunks with custom SQL |
| DROP_TASK Procedure | Remove Task |
| DROP_CHUNKS Procedure | Eliminate chunks |
| RESUME_TASK Procedures | Rerun a stopped task |
| RUN_TASK Procedure | Execute the task |
| STOP_TASK Procedure | Stop the task |
| TASK_STATUS Procedure | Return task current status |
The steps for applying DBMS_PARALLEL_EXECUTE are almost similar to the steps for executing Program Parallel DML as follows.
- Create Task (CREATE_TASK)
- Splitting the work unit (Chunk)
- CREATE_CHUNKS_BY_ROWID
- CREATE_CHUNKS_BY_NUMBER_COL
- CREATE_CHUNKS_BY_SQL
- Execute task (RUN_TASK)
- Delete after task complete (DROP_TASK)
1.3. Create tables and data for DBMS_PARALLEL_EXECUTE test
Create tables and data to be tested with the following script.
-- 테스트 테이블과 데이터 생성
DROP TABLE Z_DPE_TEST_TAB PURGE;
CREATE TABLE Z_DPE_TEST_TAB (
ID NUMBER(10)
,MSG VARCHAR2(100)
,VAL NUMBER
,AUDSID NUMBER
) NOLOGGING;
-- 100만건 테스트 데이터 생성
INSERT /*+ APPEND */ INTO Z_DPE_TEST_TAB (ID, MSG)
SELECT LEVEL AS ID
,'Test Data ID: ' || TO_CHAR(LEVEL)
FROM DUAL
CONNECT BY LEVEL <= 1000000;
COMMIT;
There are 4 columns to be used in the test, and each purpose is as follows.
| column name | purpose |
| ID | A value to identify each row in the table |
| MSG | A value that provides a description |
| VAL | Random value updated in test execution |
| AUDSID | A value to check how many sessions the test runs in. It is updated with SYS_CONTEXT('USERENV','SESSIONID'). |
For reference, the environment in which this test was conducted is as follows.
- DBMS: Oracle 11g R2 Enterprise 11.2.0.1.0 32 bit (On Windows 7 x64)
- H/W: CPU i5-5200U 2.20GHz, Memory 8GB, SSD 250GB
Next, let's look at a case by way of dividing each work unit (chunk).
Related articles:
 Oracle Character Set Conversion Description Full Table of Contents
Oracle Character Set Conversion Description Full Table of Contents
 Oracle Character Set Conversion (4): 4.Configuring the Test Environment
Oracle Character Set Conversion (4): 4.Configuring the Test Environment
 Oracle Character Set Conversion (3): 3. Client Environment Configuration (2)
Oracle Character Set Conversion (3): 3. Client Environment Configuration (2)
 DBMS_PARALLEL_EXECUTE Description Table of Contents
DBMS_PARALLEL_EXECUTE Description Table of Contents
 4. User-defined SQL partitioning method parallel processing case (DBMS_PARALLEL_EXECUTE)
4. User-defined SQL partitioning method parallel processing case (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
 2.5. Detailed check of unit of work partitioning (DBMS_PARALLEL_EXECUTE)
2.5. Detailed check of unit of work partitioning (DBMS_PARALLEL_EXECUTE)
 2. ROWID partitioning parallel processing case (DBMS_PARALLEL_EXECUTE)
2. ROWID partitioning parallel processing case (DBMS_PARALLEL_EXECUTE)









