Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
Examine the source code of a word extraction tool implemented in Python.
This is a continuation of the previous article.
Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
4. Word extraction tool source code
4.1. summary
4.1.1. Note the source code
The source code of this word extraction tool is almost the first code I wrote among useful tools I made with Python. It is far from conciseness, which is the strength of Python, as it focuses only on implementing necessary functions when they are not yet familiar with it. It's more C-style than Python-style.
I was thinking about writing the result of text extraction and word extraction as a separate class, but as a test, I used pandas' DataFrame, and it worked better than I thought, so I just used the DataFrame. As an added bonus, the implementation time was greatly reduced by using the groupby and to_excel functions provided by DataFrame.
“2.1.2. Stemmer Selection: MecabAs mentioned in “, natural language stemmer Mecab was used for word extraction. To use other morpheme analyzers, please modify the get_word_list function.
The line number of the code inserted into the body was set to be the same as the line number of the source code uploaded to github, and comments were included without excluding as much as possible.
4.1.2.Word extraction tool function call relationship
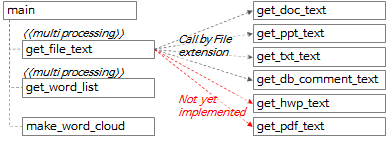
The overall call relationship of the function can be summarized as shown in the diagram above and the contents below.
- In the main function, call the get_file_text function to extract text in line and paragraph units from each file.
- In the get_file_text function, call the get_doc_text, get_ppt_text, get_txt_text, and get_db_comment_text functions according to the file extension.
- The get_hwp_text and get_pdf_text functions have not been implemented yet and will be implemented at a later time when needed. (If you have experience implementing it or know the implemented code, please leave a comment.)
- The get_file_text function execution result is passed to the get_word_list function to extract word candidates.
- The get_file_text and get_word_list functions are processed by multiprocessing.
- Create a word cloud image by calling the make_word_cloud function.
4.2. main function
4.2.1. argument parsing
def main():
"""
지정한 경로 하위 폴더의 File들에서 Text를 추출하고 각 Text의 명사를 추출하여 엑셀파일로 저장
:return: 없음
"""
# region Args Parse & Usage set-up -------------------------------------------------------------
# parser = argparse.ArgumentParser(usage='usage test', description='description test')
usage_description = """--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment"""
# ToDo: 옵션추가: 복합어 추출할지 여부, 영문자 추출할지 여부, 영문자 길이 1자리 제외여부, ...
parser = argparse.ArgumentParser(description=usage_description, formatter_class=argparse.RawTextHelpFormatter)
# name argument 추가
parser.add_argument('--multi_process_count', required=False, type=int,
help='text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)')
parser.add_argument('--db_comment_file', required=False,
help='DB Table, Column comment 정보 파일명(예: comment.xlsx)')
parser.add_argument('--in_path', required=False, help='입력파일(ppt, doc, txt) 경로명(예: .\in) ')
parser.add_argument('--out_path', required=True, help='출력파일(xlsx, png) 경로명(예: .\out)')
args = parser.parse_args()
if args.multi_process_count:
multi_process_count = int(args.multi_process_count)
else:
multi_process_count = multiprocessing.cpu_count()
db_comment_file = args.db_comment_file
if db_comment_file is not None and not os.path.isfile(db_comment_file):
print('db_comment_file not found: %s' % db_comment_file)
exit(-1)
in_path = args.in_path
out_path = args.out_path
print('------------------------------------------------------------')
print('Word Extractor v%s start --- %s' % (_version_, get_current_datetime()))
print('##### arguments #####')
print('multi_process_count: %d' % multi_process_count)
print('db_comment_file: %s' % db_comment_file)
print('in_path: %s' % in_path)
print('out_path: %s' % out_path)
print('------------------------------------------------------------')
- Line 395: Create an ArgumentParser object from the argparse package.
- Lines 397 to 404: Add necessary arguments and parse the arguments specified during execution.
- Lines 406 to 425: Set argument as an internal variable and print the set value.
4.2.2. Extract list of files to process
file_list = []
if in_path is not None and in_path.strip() != '':
print('[%s] Start Get File List...' % get_current_datetime())
in_abspath = os.path.abspath(in_path) # os.path.abspath('.') + '\\test_files'
file_types = ('.ppt', '.pptx', '.doc', '.docx', '.txt')
for root, dir, files in os.walk(in_abspath):
for file in sorted(files):
# 제외할 파일
if file.startswith('~'):
continue
# 포함할 파일
if file.endswith(file_types):
file_list.append(root + '\\' + file)
print('[%s] Finish Get File List.' % get_current_datetime())
print('--- File List ---')
print('\n'.join(file_list))
if db_comment_file is not None:
file_list.append(db_comment_file)
- Line 436: Defines a list of file extensions that correspond to the files to be processed.
- Lines 437~444: Among the arguments specified during execution, the entire folder under in_path is searched recursively to determine whether each file is a target file, and if it is a target file, it is added to file_list.
- Lines 451 to 452: If db_comment_file exists among the arguments specified during execution, it is added to the file_list.
4.2.3. Execute get_file_text with multi processing
print('[%s] Start Get File Text...' % get_current_datetime())
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_text_result = pool.map(get_file_text, file_list)
df_text = pd.concat(mp_text_result, ignore_index=True)
print('[%s] Finish Get File Text.' % get_current_datetime())
# 여기까지 text 추출완료. 아래에 단어 추출 시작
- Lines 455 to 456: During execution, the process is executed as many as multi_process_count specified, and the get_file_text function is executed by inputting file_lsit in each process, and the result is stored in mp_text_result.
- Line 457: Each list item of mp_text_result, which is a list of DataFrame, is concatenated into one DataFrame, df_text.
4.2.4. Execute get_word_list with multi processing
# ---------- 병렬 실행 ----------
print('[%s] Start Get Word from File Text...' % get_current_datetime())
df_text_split = np.array_split(df_text, multi_process_count)
# mp_result = []
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_result = pool.map(get_word_list, df_text_split)
df_result = pd.concat(mp_result, ignore_index=True)
if 'DB' not in df_result.columns:
df_result['DB'] = ''
df_result['Schema'] = ''
df_result['Table'] = ''
df_result['Column'] = ''
print('[%s] Finish Get Word from File Text.' % get_current_datetime())
# ------------------------------
- Line 463: Divide the lines of df_text by multi_process_count and put each divided DataFrame in df_text_split (list type).
- For example, if there are 1000 rows in df_text and multi_process_count is 4, 4 DataFrames with 250 rows each are created, and a df_text_split variable with these 4 DataFrames as items is created.
- Lines 465~466: Executes the process as many as multi_process_count specified during execution, executes the get_word_list function with df_text_split as input in each process, and stores the result in mp_result.
- Line 468: Concat each list item of mp_result, which is a list of DataFrames, to make one DataFrame, df_result.
- Lines 469-473: 'DB', 'Schema', 'Table', 'Column' to simplify subsequent processing logic and avoid errors when 'DB' does not exist in df_result.columns, that is, when db_comment_file is not specified. Add a column with the name of ' as an empty value.
4.2.5. Get word frequency and run make_word_cloud
print('[%s] Start Get Word Frequency...' % get_current_datetime())
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
df_group = df_group.sort_values(by='Freq', ascending=False)
print('[%s] Finish Get Word Frequency.' % get_current_datetime())
# df_group['Len'] = df_group['Word'].str.len()
# df_group['Len'] = df_group['Word'].apply(lambda x: len(x))
print('[%s] Start Make Word Cloud...' % get_current_datetime())
now_dt = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
make_word_cloud(df_group, now_dt, out_path)
print('[%s] Finish Make Word Cloud.' % get_current_datetime())
- Line 480: Create a df_result_subset DataFrame by selecting only the 'Word' and 'Source' columns from df_result.
- Line 482: Get count by grouping df_result_subset with the 'Word' column, extract the first 10 values of 'Source' and connect them with a row separator to create a df_group DataFrame.
- Lines 483~484: Designate the index name of df_group DataFrame as 'Word' and the column names as 'Freq' and 'Source', respectively.
- Line 485: Reverse sort df_group by 'Freq' (word frequency).
- Line 491: Pass df_group to the make_word_cloud function to create and save the word cloud image.
4.2.6. Save the extracted word list and word frequency as an Excel file, print the execution time, and exit
print('[%s] Start Save the Extract result to Excel File...' % get_current_datetime())
df_result.index += 1
excel_style = {
'font-size': '10pt'
}
df_result = df_result.style.set_properties(**excel_style)
df_group = df_group.style.set_properties(**excel_style)
out_file_name = '%s\\extract_result_%s.xlsx' % (out_path, now_dt) # 'out\\extract_result_%s.xlsx' % now_dt
print('start writing excel file...')
with pd.ExcelWriter(path=out_file_name, engine='xlsxwriter') as writer:
df_result.to_excel(writer,
header=True,
sheet_name='단어추출결과',
index=True,
index_label='No',
freeze_panes=(1, 0),
columns=['Word', 'FileName', 'FileType', 'Page', 'Text', 'DB', 'Schema', 'Table', 'Column'])
df_group.to_excel(writer,
header=True,
sheet_name='단어빈도',
index=True,
index_label='단어',
freeze_panes=(1, 0))
workbook = writer.book
worksheet = writer.sheets['단어빈도']
wrap_format = workbook.add_format({'text_wrap': True})
worksheet.set_column("C:C", None, wrap_format)
# print('finished writing excel file')
print('[%s] Finish Save the Extract result to Excel File...' % get_current_datetime())
end_time = time.time()
# elapsed_time = end_time - start_time
elapsed_time = str(datetime.timedelta(seconds=end_time - start_time))
print('------------------------------------------------------------')
print('[%s] Finished.' % get_current_datetime())
print('overall elapsed time: %s' % elapsed_time)
print('------------------------------------------------------------')
- Lines 495~501: Set the Excel font size to 10 points, and set the path and file name of the Excel file to be saved.
- Lines 504~521: Save df_result, df_group DataFrame as an Excel file using pandas ExcelWriter.
- Lines 526-532: Calculate and print the time taken for execution and exit.
The article is getting long, so I'm splitting it into two parts. Continued in next article.
<< List of related articles >>
- Word Extraction Tool(1): Overview of Word Extraction Tool
- Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
- Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
- Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
- Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
- Word Extraction Tool (6): Additional Description of Word Extraction Tool
- Full Contents of Word Extraction Tool Description , Download
Related articles:
 Full Contents of Word Extraction Tool Description , Download
Full Contents of Word Extraction Tool Description , Download
 Word Extraction Tool (6): Additional Description of Word Extraction Tool
Word Extraction Tool (6): Additional Description of Word Extraction Tool
 Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
 Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
 Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
 Word Extraction Tool(1): Overview of Word Extraction Tool
Word Extraction Tool(1): Overview of Word Extraction Tool
 Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
 Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)
Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)










hello
I made a get_pdf_text function using the word extraction tool word code and 'pdfplumber' you posted.
Can I show you in a comment or email?
hello!
I implemented the get_pdf_text function using the word extractor source code you posted.
It was confirmed that it works when pdf is added to the file extension-related part of the existing code and the get_pdf_tex function is added.
Let me know what needs to be corrected and I'll take care of it.
You need pip install pdfplumber.
import pdfplumber
def get_pdf_text(file_name) -> DataFrame:
start_time = time.time()
print('\r\nget_txt_text: ' + file_name)
df_text = pd.DataFrame()
pdf_file = pdfplumber.open(file_name)
page = 0
for pg in pdf_file.pages:
texts = pg. extract_text()
page += 1
for text in texts. split():
if text.strip() != ”:
sr_text = Series([file_name, 'pdf', page, text, f'{file_name}:{page}:{text}'],
index=['FileName', 'FileType', 'Page', 'Text', 'Source'])
df_text = df_text.append(sr_text, ignore_index=True)
print('text count: %s' % str(df_text. shape[0]))
print('page count: %d' % page)
pdf_file.close()
end_time = time.time()
elapsed_time = str(datetime.timedelta(seconds=end_time – start_time))
print('[pid:%d] get_pdf_text elapsed time: %s' % (os.getpid(), elapsed_time))
return df_text
Thanks for sharing the get_pdf_text function source code.
The source code you wrote is indented, but it's a bit inconvenient to see because the indentation isn't displayed in WordPress comments.
Let's set the indentation to be visible.
When setting the indentation to be visible, if you need the indented original source code, I will upload it again.