Word Extraction Tool(1): Overview of Word Extraction Tool
An overview of word extraction tools that can be useful for data standardization work, especially for creating standard word candidates.
1. Word Extraction Tool Overview
1.1. Why We Developed Word Extraction Tool
Among the initial tasks of data standardization, the most difficult task is to collect as many candidates as possible and quickly to be registered as standard words. Data Standards Checking Tool (see: Data standard inspection tool_1.Overview) can be used to extract standard word candidates, but it has the following difficulties.
- If database table, column comment data contains many special characters (symbols such as #, $, %, ., \, etc., and line separators, etc.), considerable effort is required to remove or refine them.
- It is difficult to know the frequency of words, so it is difficult to determine whether to register only single words, only compound words, or both single words and compound words.
- If a compound word is later identified after a standard word is confirmed and affects the physical name of a standard term that has already been registered, exceptions to the standard naming rule can make management difficult.
The word extraction tool was developed to alleviate some of these difficulties. In particular, we hope that it will be helpful in the following cases.
- If there is no current data standard dictionary or even if the number of standard words is small
- Your job is so unique that there is no data standard dictionary that is suitable for reference.
- When the database table and column comments are too large and it takes a lot of time to manually extract words
- Or, conversely, when there is little content in database tables and column comments, so it is inappropriate to extract standard words and it is appropriate to extract them from documents such as work manuals.
- In addition, if words and frequencies are required to be extracted from documents
1.2. word extraction tool concept
The word extraction tool is a tool that receives various types of files as input, extracts words and compound words using a natural language processing morpheme analyzer, and outputs the frequency and source (file name, table name, column name, etc.) as an Excel file.
Mecab, a Korean natural language processing (NLP) morpheme analyzer, was used and developed in Python v3.8. Kkma, Komoran, Hannanum, Okt (formerly known as Twitter), and Mecab are representative libraries among Korean natural language processing morpheme analyzers. Among them, Mecab was selected because it has the best performance.
Performance comparison of natural language processing morpheme analyzers can be found in the link below.
Reference: https://konlpy.org/ko/latest/morph/#comparison-between-pos-tagging-classes
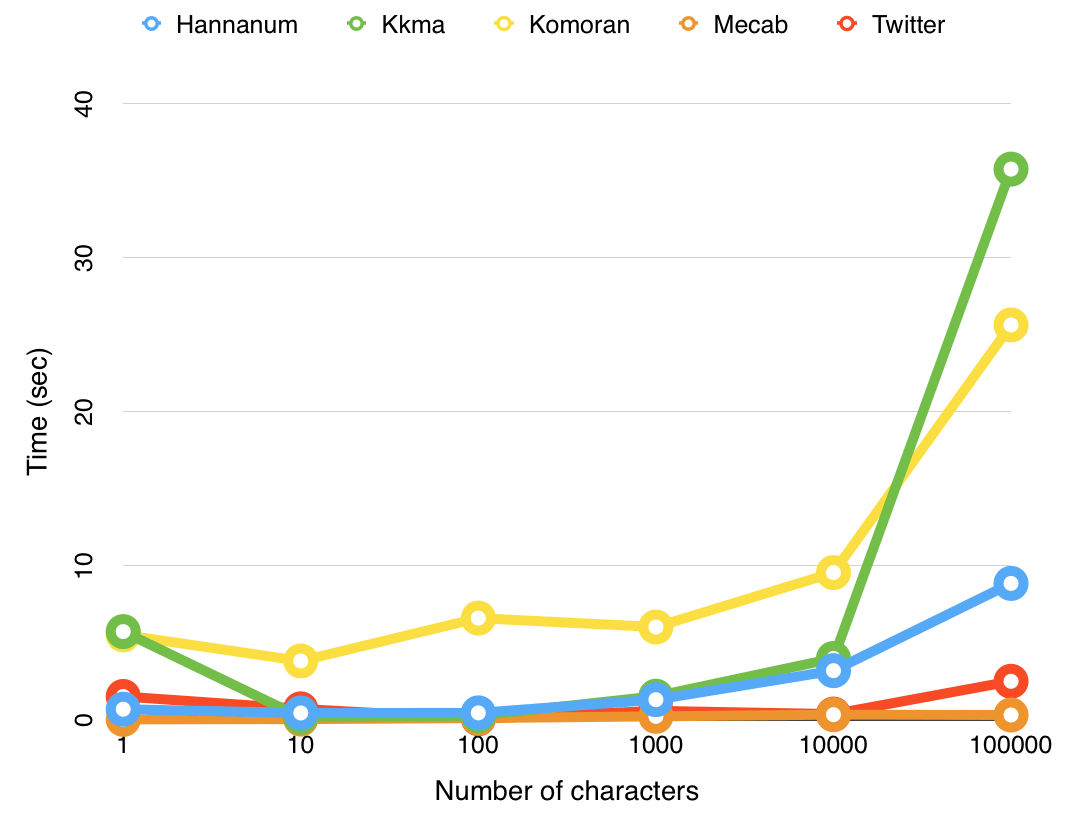
The execution time according to the increase in the number of input characters can be summarized as follows. (Execution time decreases and performance improves as you go from left to right)
Kkma > Komoran > Hannanum > Okt (Twitter) > Mecab
For reference, the above link is KoNLPy packageThis is the site of the person who developed it. KoNLPyis a Python-based package that bundles several morpheme analyzers into one.
KoNLPy: https://konlpy.org/ko/latest/
1.3. How the word extractor works
Briefly look at input data, processing logic, and output data.
1.3.1. word extraction tool input material
Input data can be specified in one or both of the following two ways.
- Documents: MS Word, PowerPoint, Text files
- At the time of writing this article (2021-08-29), HWP and PDF formats are not yet supported.
- DB Table, Column comment Source: Excel file
- Table comment data items: Database, Schema, Table Name, Table Comment
- Column comment data items: Database, Schema, Table Name, Table Comment, Column Name, Column Comment
▼ An example of table comment data is as follows.
| Database | Schema | Table Name | Table Comment |
| DB1 | OWNER1 | COMTCADMINISTCODE | administrative code |
| DB1 | OWNER1 | COMTCADMINISTCODERECPTNLOG | Administration code reception log |
| DB1 | OWNER1 | COMTCCMNCLCODE | Common classification code |
| DB1 | OWNER1 | COMTCCMNCODE | common code |
| DB1 | OWNER1 | COMTCCMNDETAILCODE | Common detail code |
▼ Examples of column comment data are as follows. This is the column list of COMTCADMINISTCODE (administrative code) among the table list above.
| Database | Schema | Table Name | Column Name | Column Comment |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE | Administrative district division |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE | Administrative district code |
| DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT | Whether or not to use |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM | Administrative district name |
| DB1 | OWNER1 | COMTCADMINISTCODE | UPPER_ADMINIST_ZONE_CODE | Upper Administrative District Code |
| DB1 | OWNER1 | COMTCADMINISTCODE | CREAT_DE | creation date |
| DB1 | OWNER1 | COMTCADMINISTCODE | ABL_DE | abolition date |
| DB1 | OWNER1 | COMTCADMINISTCODE | FRST_REGIST_PNTTM | First registration |
| DB1 | OWNER1 | COMTCADMINISTCODE | FRST_REGISTER_ID | Initial registrant ID |
| DB1 | OWNER1 | COMTCADMINISTCODE | LAST_UPDT_PNTTM | Last modified time |
| DB1 | OWNER1 | COMTCADMINISTCODE | LAST_UPDUSR_ID | Last Modified ID |
* The example data above was created using the table and column comment scripts in the “Common Component Table Configuration Information” page of the e-Government Standard Framework v3.8.
(source: https://www.egovframe.go.kr/wiki/doku.php?id=egovframework:com:v3.8:init_table)
1.3.2. Word extraction tool processing logic
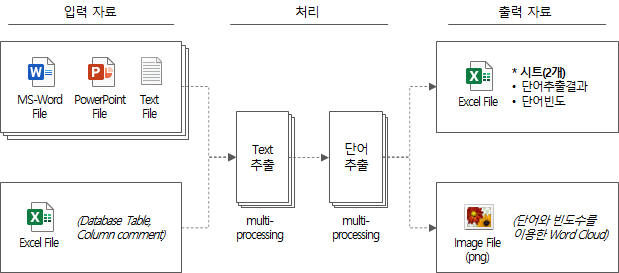
A brief summary of the entire processing logic is as follows.
- Extract text (line by row, table/column) by opening input data sequentially
- Extraction of word candidates in the form of 1 noun, n nouns, prefix + n nouns, n nouns + suffixes, prefix + n nouns + suffixes using Mecab, a natural language morpheme analyzer package
- Find the frequency of words extracted from the entire input data, and save the word extraction result as an output file
- Create and save word cloud as png file with word list and frequency
- Outputs the total required time and exits
A simplified diagram of the above process is as follows.
1.3.3. Word extraction tool output data
The output data, which is the result of processing the input data, is an Excel file and an image (png) file in the form of a word cloud.
The Excel file consists of two sheets. The following is an example of DB Table and Column comment data as input.
▼ “Example of word extraction result” sheet
| No | word | FileName | FileType | Page | Text | DB | Schema | table | Column |
| 1 | administration | table,column comments.xlsx | column | 0 | Administrative district division | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 2 | area | table,column comments.xlsx | column | 0 | Administrative district division | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 3 | division | table,column comments.xlsx | column | 0 | Administrative district division | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 4 | Administrative division [compound] | table,column comments.xlsx | column | 0 | Administrative district division | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 5 | administration | table,column comments.xlsx | column | 0 | Administrative district code | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 6 | area | table,column comments.xlsx | column | 0 | Administrative district code | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 7 | code | table,column comments.xlsx | column | 0 | Administrative district code | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 8 | Administrative district code [compound] | table,column comments.xlsx | column | 0 | Administrative district code | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 9 | use | table,column comments.xlsx | column | 0 | Whether or not to use | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 10 | Whether | table,column comments.xlsx | column | 0 | Whether or not to use | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 11 | Whether to use [compound word] | table,column comments.xlsx | column | 0 | Whether or not to use | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 12 | region | table,column comments.xlsx | column | 0 | Administrative district name | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 13 | station name | table,column comments.xlsx | column | 0 | Administrative district name | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 14 | Administrative district name [compound] | table,column comments.xlsx | column | 0 | Administrative district name | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
- “Text” column: This is the original value extracted from the input data, and in this example, it corresponds to table, column comment.
- Column “Word”: Word candidates extracted from Text using Mecab. For compound words, specify “[compound word]” as a suffix.
- Line 12 “administration district”, line 13 “station name” are words extracted from “administration name” in Mecab.
- It can be seen that the accuracy is not 100% because it is extracted differently from the word actually used.
▼ “Word frequency” sheet example
| word | Freq | Source |
| code | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (administrative zone code) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (change identification code) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE (attempt code) … |
| number | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(job serial number) DB1.OWNER1.COMTCZIP.ZIP (postal code) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (approval number) … |
| number of people | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (address book name) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (classification code name) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (code name) … |
| Day | 85 | DB1.OWNER1.COMTCADMINISTCODE.CREAT_DE(creation date) DB1.OWNER1.COMTCADMINISTCODE.ABL_DE (retirement date) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OCCRRNC_DE(occurrence date) … |
| information | 77 | DB1.OWNER1.COMTHDBMNTRNGLOGINFO.LOG_INFO (log information) DB1.OWNER1.COMTNBACKUPRESULT.ERROR_INFO (error information) DB1.OWNER1.COMTNINDVDLINFOPOLICY.INDVDL_INFO_POLICY_ID (Privacy Policy ID) … |
| Whether | 75 | DB1.OWNER1.COMTCADMINISTCODE.USE_AT (whether to use) DB1.OWNER1.COMTNANNVRSRYMANAGE.REPTIT_AT (whether to repeat) DB1.OWNER1.COMTNBANNER.REFLCT_AT (whether to reflect) … |
- “Word” column: This is a string value obtained by removing duplicates from the “Word” column of the “Word Extraction Result” sheet. This value is a candidate to be registered as a standard word.
- Column “Freq”: This is the frequency count indicating how many times the word was used. The resulting list is sorted in reverse order from these high-frequency words to the low-frequency ones.
- “Source” column: Indicates the source of the word. Displays up to 10 sources.
- If the source is Table, the format is: DB.Schema.TableName(Table comment)
- If the source is Column, the format is: DB.Schema.TableName.ColumnName(Column comment)
- If the source is File Format: Filename:PageNumber:Text
An example of a word cloud image generated by the frequency of extracted words is as follows. Words with high frequency are displayed in large size.

The word extraction tool is a tool developed in Python, and requires an environment configuration process such as installing Python and necessary packages prior to execution. Next, we will look at the environment configuration process.
<< List of related articles >>
- Word Extraction Tool(1): Overview of Word Extraction Tool
- Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
- Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
- Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
- Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
- Word Extraction Tool (6): Additional Description of Word Extraction Tool
- Full Contents of Word Extraction Tool Description , Download
Related articles:
 Full Contents of Word Extraction Tool Description , Download
Full Contents of Word Extraction Tool Description , Download
 Word Extraction Tool (6): Additional Description of Word Extraction Tool
Word Extraction Tool (6): Additional Description of Word Extraction Tool
 Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
 Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
 Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
 Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
 Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
 Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)
Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)









