3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
Published
· Updated
Let's take a look at the case of NUMBER Column partitioning parallel processing using Oracle DBMS_PARALLEL_EXECUTE. It covers job creation, job unit division, job execution, job completion confirmation, and deletion.
There is no difference in how the task is created.
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
-- 작업 생성 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_TASKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)';
3.2. Split work unit
CREATE_CHUNKS_BY_NUMBER_COL( ,
,
,
, ) to divide the unit of work.
Execute as follows to create chunks that are divided into 10,000 cases based on the “ID” column of the Z_DPE_TEST_TAB table.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_NUMBER_COL (
TASK_NAME => 'DPE_TEST(BY NUMBER)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
TABLE_COLUMN => 'ID',
CHUNK_SIZE => 10000);
END;
Let's check the division state of the unit of work.
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
ORDER BY START_ID;
work split status
As you can see roughly from the above result, each chunk is divided into 10,000 rows. (The example table generated sequential numbers from 1 to 1 million as ID values)
For reference, when ROWID split (CREATE_CHUNKS_BY_ROWID procedure), values are created in START_ROWID and END_ROWID, and when NUMBER column split (CREATE_CHUNKS_BY_NUMBER_COL), values are created in START_ID and END_ID.
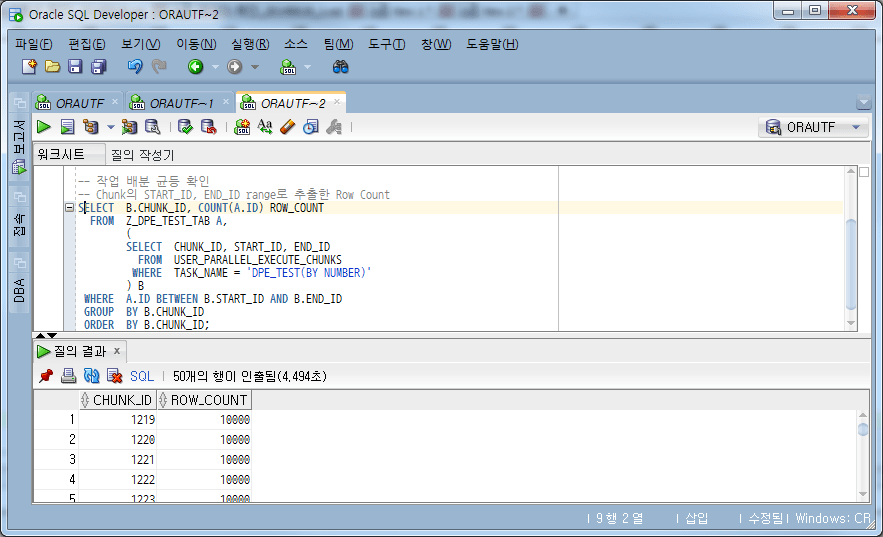
Let's check if the work units (chunks) are evenly distributed.
-- 작업 분할 균등 확인
-- Chunk의 START_ID, END_ID range로 추출한 Row Count
SELECT B.CHUNK_ID, COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
Work Split Equal Check
If you check the number of table cases with START_ID and END_ID of each chunk, it is well divided into 10,000 cases.
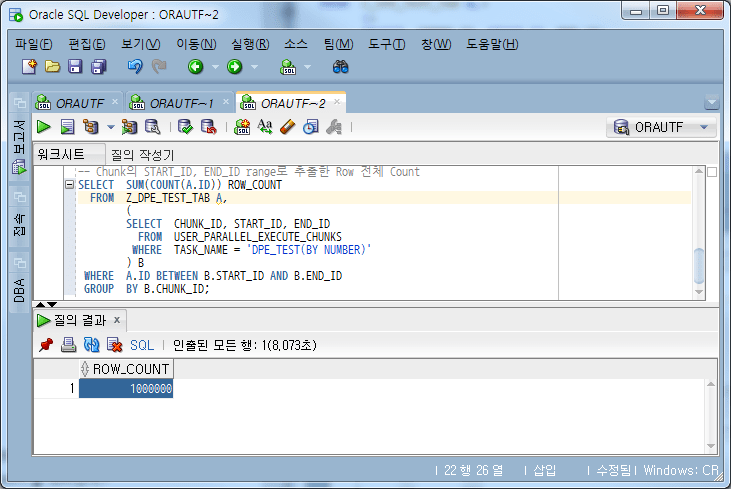
-- Chunk의 START_ID, END_ID range로 추출한 Row 전체 Count
SELECT SUM(COUNT(A.ID)) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID;
check chunk row count sum
The sum of row counts of all chunks is 1,000,000, which is consistent with the total number of data.
3.3. job run
RUN_TASK( , , , ) to execute the task. The task execution method is the same as the ROWID method.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'UPDATE Z_DPE_TEST_TAB
SET VAL = ROUND(DBMS_RANDOM.VALUE(1,10000))
,AUDSID = SYS_CONTEXT(''USERENV'',''SESSIONID'')
WHERE ID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 10);
END;
/
The SQL to be executed is almost the same as the case of ROWID partitioning, but the difference is that the condition column in the WHERE clause is not “ROWID” but the designated NUMBER column “ID”.
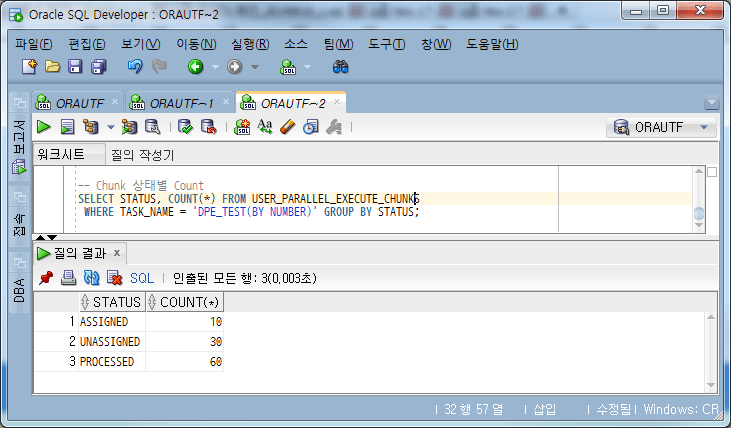
Let's look at the chunk state changes during execution.
-- Chunk 상태별 Count
SELECT STATUS, COUNT
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
GROUP BY STATUS;
When a task is in progress, the state of the chunk is changed from UNASSIGNED -> ASSIGNED -> PROCESSED as follows.
Check chunk status while running jobs
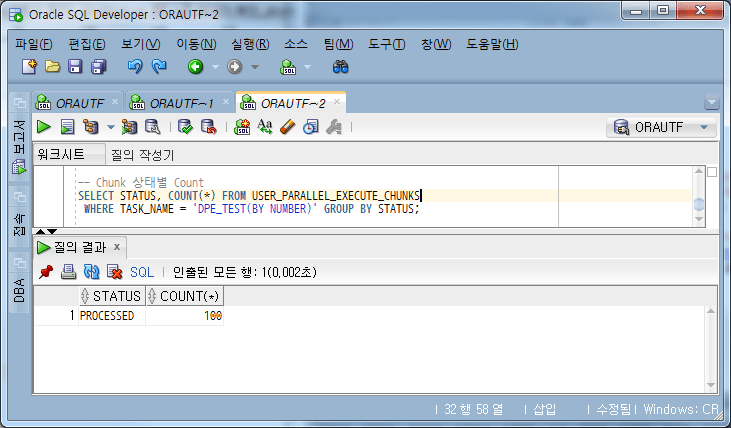
When the task is complete, the status of all chunks appears as PROCESSED.
Check task completion chunk status
You can check how many rows were updated in how many sessions by executing the following SQL after the task is completed.
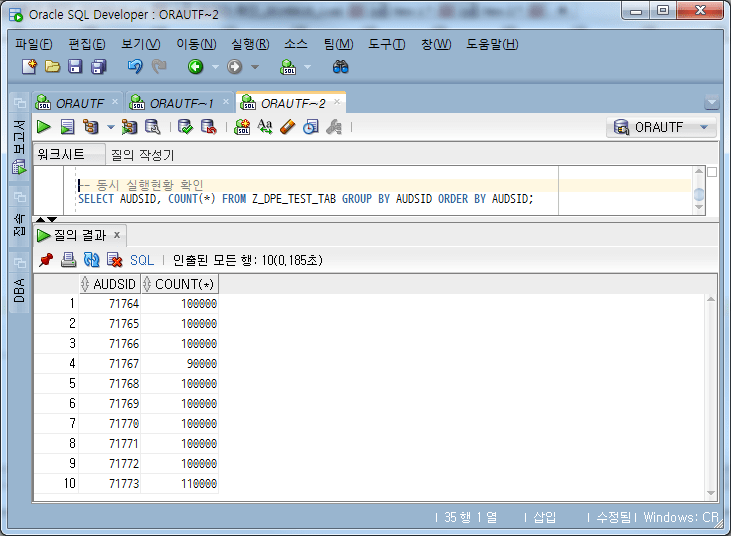
-- 동시 실행현황 확인
SELECT AUDSID, COUNT(*)
FROM Z_DPE_TEST_TAB
GROUP BY AUDSID
ORDER BY AUDSID;
Check the number of data processed per session
From the above, it can be seen that:
A total of 10 Job Sessions have been executed
Each Job Session received and executed most of 10 Chunks of 10,000 Chunks.
AUDSID: 71767 Job Session was executed after being allocated 9 Chunks (90,000 cases), AUDSID: 71773 Job Session was executed after being allocated 11 Chunks (110,000 cases)
That is, the number of RUN_TASK is higher than the total number of chunks (100 in this case). When the number of chunks is small, a job is assigned several chunks and executed, and the number of executions may vary even if the degree of division of chunks is uniform.
3.4. Confirm task completion and delete
DROP_TASK( ) to delete the job.
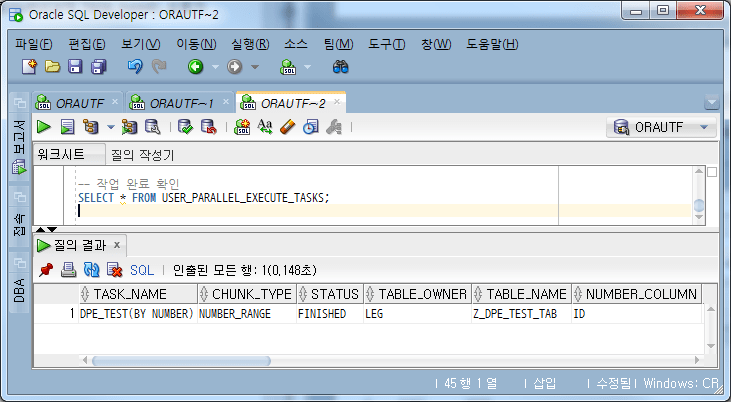
-- 4단계: 작업 완료 확인 및 작업 삭제
-- 작업 완료 확인
SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
-- 작업 삭제
BEGIN
DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
Confirm task completion
So far, we have looked at the case of parallel processing of the NUMBER Column division method. The following is an example of partitioning based on user-defined SQL.