2.5. Detailed check of unit of work partitioning (DBMS_PARALLEL_EXECUTE)
This is related to checking the details of work unit division. Examine the degree to which the result of dividing work units (chunks) by ROWID is evenly divided, whether the sum of work units is the same as the whole, and whether there are no omissions, and the correlation between the number of work units and the number of jobs.
This is a continuation of the previous article.
2. Parallel processing case of ROWID division method
2.5. Work unit division details check
Let's take a look at the following to see if the unit of work is well-divided.
- Uniformity of work units partitioned by ROWID
- Check that there are no missing units of work divided by ROWID
- Correlation between the number of work units (chunks) and the PARALLEL_LEVEL (the number of jobs to be executed)
2.5.1. Uniformity of work units partitioned by ROWID
The following division means to divide the Z_DPE_TEST_TAB table into 10,000 work units based on ROW Count.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
Let's see if it really splits by 10,000.
-- 작업단위 개수 확인 --> 115 SELECT COUNT(*) FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
Since the total number of rows is 1,000,000, it seems that it should be divided into 100 chunks if it is divided into 10,000 rows, but in reality it is divided into 115 chunks.
If you calculate the row count for each chunk,
SELECT B.CHUNK_ID, COUNT(A.ID), MIN(A.ID) MIN_ID, MAX(A.ID) MAX_ID
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
You can see that it is divided into various Counts, such as 1334, 2064, and 1886, not 10,000.
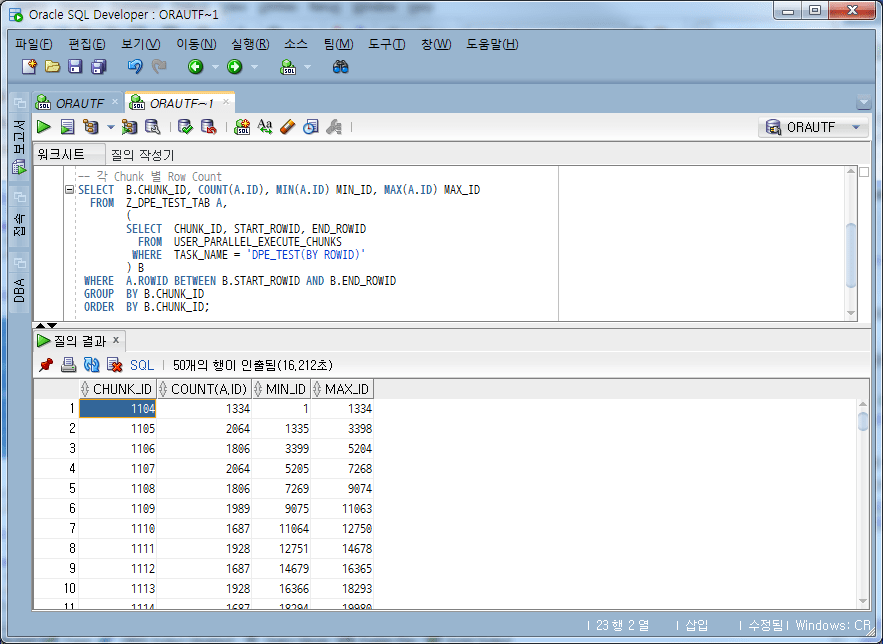
The number of rows contained in the chunk is 14 in the 1,000-2,000 section, 2 in the 2,000 row section, 33 in the 6,000 row section, 64 in the 11,000 row section, and 2 in the 12,000 row section. (It may not give the same result every time.)
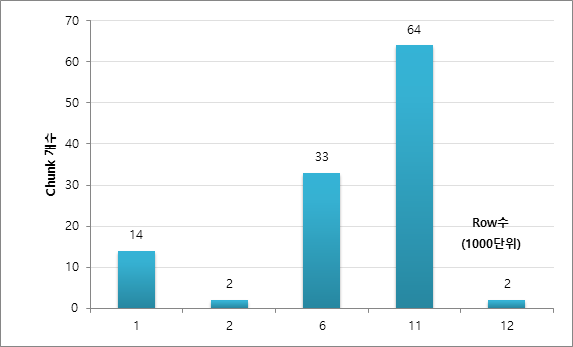
As such, it is not divided into a completely equal number of rows. This seems to be because the ROWID partitioning method is based on DBA_EXTENTS, and the number of blocks included in each EXTENT and the ROW Count of each block can be different. For reference, if there are unused BLOCKs in the table by DELETE, etc., a ROWID section where no data actually exists may be created as a chunk. This is also expected to occur when data is deleted after being allocated to DBA_EXTENT, or when there are EXTENTs that have been allocated but do not contain actual data.
2.5.2. Check that there are no missing units of work divided by ROWID
Could there be missing data when the START_ROWID and END_ROWID sections of each chunk are expanded?
First, let's check the row count.
-- Chunk의 RowID range로 추출한 Row Count
SELECT COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID;
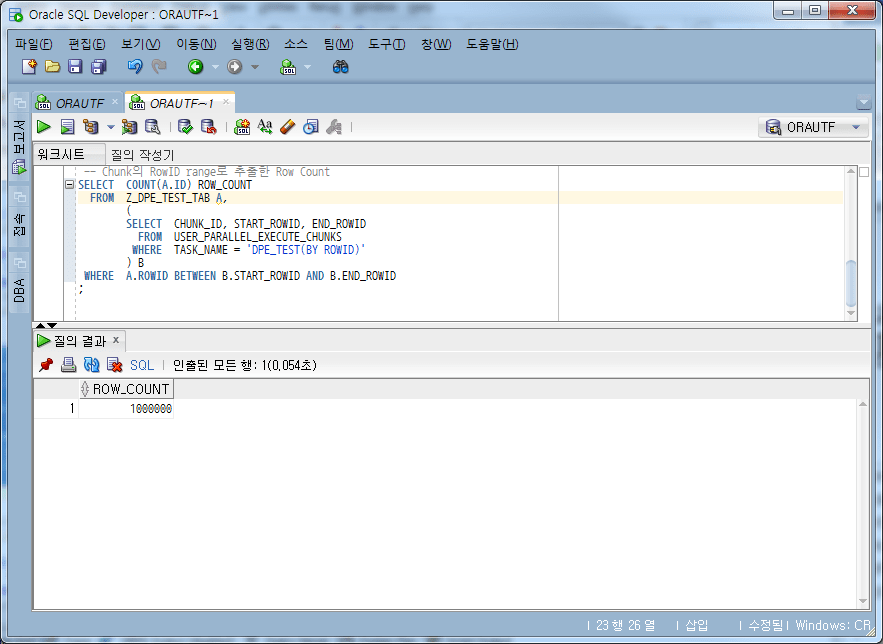
Matching the total row count of 1,000,000, once confirmed that the count was not missing, and then, based on the data extracted in the range of START_ROWID to END_ROWID of Chunk, when the original data was LEFT OUTER JOINed, missing (missing) ) to see if the data exists.
-- Chunk의 RowID로 추출한 데이터의 누락없음 확인
SELECT *
FROM Z_DPE_TEST_TAB A LEFT OUTER JOIN
(
SELECT A.ID -- Chunk의 RowID range로 추출한 데이터
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
) B ON (A.ID = B.ID)
WHERE B.ID IS NULL;
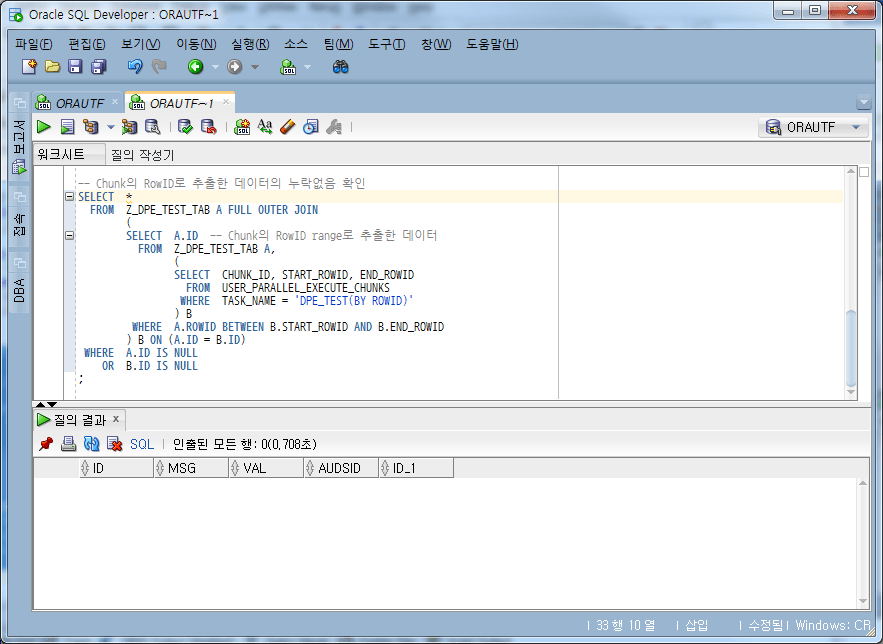
From the above results, it can be seen that there is no missing data.
2.5.3. Correlation between the number of work units (chunks) and the PARALLEL_LEVEL (the number of jobs to be executed)
<2.3. In Task Execution>, there was the following content.
PARALLEL_LEVEL means the number of jobs to be executed simultaneously, that is, the degree of parallelism (DOP), and may be equal to or smaller than the number of chunks, which are work units. In the same case, one job processes one chunk, and in a small case, one job processes several chunks.
* Reference: 2. Parallel processing case of ROWID division method_2.3. job run
Consider the following cases regarding the number of chunks and the number of jobs.
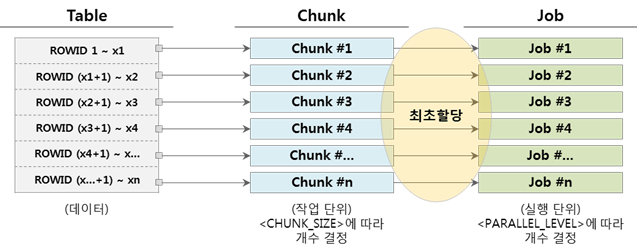
▼ When the number of chunks and the number of jobs are the same (Chunk = Job)
When one job completes the execution of the assigned chunk, it ends because there are no more jobs to run.
▼ When the number of jobs is less than the number of chunks (Chunk > Job)
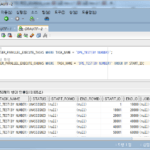
When the job of the chunk to which the job is assigned is completed, the chunk that has not yet been executed is allocated and executed continuously. Below is an example when there are 3 jobs.
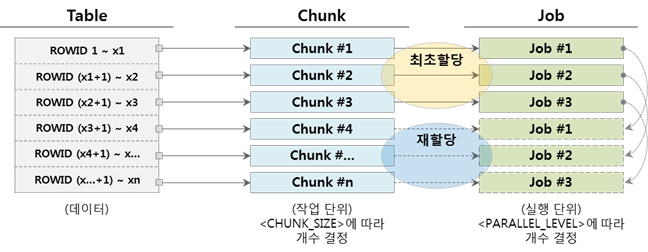
In addition, if the number of jobs is greater than the number of chunks (Chunk < Job), it is also possible, but it is better not to apply it because chunks are not allocated and unnecessary resources can be used by maintaining the running state.
* Reference: DBMS_PARALLEL_EXECUTE Chunk by ROWID Example
So far, we have looked at the ROWID partitioning method. Next, look at the NUMBER column partitioning method.
Related articles:
 Oracle Character Set Conversion (10): 6.3. How to convert CLOB type to Korean
Oracle Character Set Conversion (10): 6.3. How to convert CLOB type to Korean
 Oracle Character Set Conversion (3): 3. Client Environment Configuration (2)
Oracle Character Set Conversion (3): 3. Client Environment Configuration (2)
 Oracle Character Set Conversion (2): 3. Configuring the Client Environment (1)
Oracle Character Set Conversion (2): 3. Configuring the Client Environment (1)
 DBMS_PARALLEL_EXECUTE Description Table of Contents
DBMS_PARALLEL_EXECUTE Description Table of Contents
 4. User-defined SQL partitioning method parallel processing case (DBMS_PARALLEL_EXECUTE)
4. User-defined SQL partitioning method parallel processing case (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
3. NUMBER Column Split Method Parallel Processing Case (DBMS_PARALLEL_EXECUTE)
 2. ROWID partitioning parallel processing case (DBMS_PARALLEL_EXECUTE)
2. ROWID partitioning parallel processing case (DBMS_PARALLEL_EXECUTE)
 1. Overview of parallel processing of DML jobs (DBMS_PARALLEL_EXECUTE)
1. Overview of parallel processing of DML jobs (DBMS_PARALLEL_EXECUTE)









