Oracle Character Set Conversion (3): 3. Client Environment Configuration (2)
Continuing from the previous article, we look at the configuration of the Oracle Character Set conversion client environment. Oracle Server Character Set and Client NLS_LANG recommended four configurations can be checked.
3.2. Summary of test case execution results
previous post Oracle Character Set Conversion (2): 3. Configuring the Client Environment (1)The execution results of each test case are summarized as follows.
| Case # | Server Character Set | Client NLS_LANG | value | input | DUMP value | |
|---|---|---|---|---|---|---|
| 1 | US7ASCII | KO16KSC5601 | 'Hangul' | success | fracture | Typ=1 Len=2 CharacterSet=US7ASCII: 3f,3f |
| 'sharp' | failure | - | - | |||
| 2 | US7ASCII | KO16MSWIN949 | 'Hangul' | success | fracture | Typ=1 Len=2 CharacterSet=US7ASCII: 3f,3f |
| 'sharp' | success | fracture | Typ=1 Len=1 CharacterSet=US7ASCII: 3f | |||
| 3 | US7ASCII | US7ASCII | 'Hangul' | success | normal | Typ=1 Len=4 CharacterSet=US7ASCII: c7,d1,b1,db |
| 'sharp' | success | normal | Typ=1 Len=2 CharacterSet=US7ASCII: 98,de | |||
| 4 | KO16MSWIN949 | KO16KSC5601 | 'Hangul' | success | normal | Typ=1 Len=4 CharacterSet=KO16MSWIN949: c7,d1,b1,db |
| 'sharp' | failure | - | - | |||
| 5 | KO16MSWIN949 | KO16MSWIN949 | 'Hangul' | success | normal | Typ=1 Len=4 CharacterSet=KO16MSWIN949: c7,d1,b1,db |
| 'sharp' | success | normal | Typ=1 Len=2 CharacterSet=KO16MSWIN949: 98,de | |||
| 6 | KO16MSWIN949 | US7ASCII | 'Hangul' | success | fracture | Typ=1 Len=4 CharacterSet=KO16MSWIN949: 3f,3f,3f,3f |
| 'sharp' | success | fracture | Typ=1 Len=2 CharacterSet=KO16MSWIN949: 3f,3f | |||
| 7 | AL32UTF8 | KO16KSC5601 | 'Hangul' | success | normal | Typ=1 Len=6 CharacterSet=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'sharp' | failure | - | - | |||
| 8 | AL32UTF8 | KO16MSWIN949 | 'Hangul' | success | normal | Typ=1 Len=6 CharacterSet=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'sharp' | success | normal | Typ=1 Len=3 CharacterSet=AL32UTF8: ec,83,be | |||
| 9-1 | AL32UTF8 | AL32UTF8 (cmd) | 'Hangul' | failure | - | - |
| 'sharp' | failure | - | - | |||
| 9-2 | AL32UTF8 | AL32UTF8 (PowerShell) | 'Hangul' | success | normal | Typ=1 Len=6 CharacterSet=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'sharp' | success | normal | Typ=1 Len=3 CharacterSet=AL32UTF8: ec,83,be |
3.3 Oracle Server Character Set and Client NLS_LANG Recommended Configuration
The configuration of the Oracle Server and Client environment for Hangul input/output is possible in the following four combinations.
| Case # | Server Character Set | Client NLS_LANG | Comment |
| 3 | US7ASCII | US7ASCII | never use it Use only if you cannot change the existing environment!!! |
| 5 | KO16MSWIN949 | KO16MSWIN949 | Stores and inputs and outputs only Korean characters, English characters, numbers, special characters, Chinese characters, etc. supported on Korean Windows (multilingual characters cannot be stored in the server) |
| 8 | AL32UTF8 | KO16MSWIN949 | Used when the server is a multilingual environment and the client inputs and outputs only Korean. Can be used when the client application cannot handle Unicode |
| 9 | AL32UTF8 | AL32UTF8 | The value stored in the server is transmitted to the client as it is without conversion. That is, the client must directly handle UTF8-encoded data. |
Case #3 seems to have no problem with input/output, but looking at the dump value, you can see that the character set is US7ASCII. That is, it means that actual input/output is executed in units of 1 byte of US7ASCII, and it is stored incorrectly.
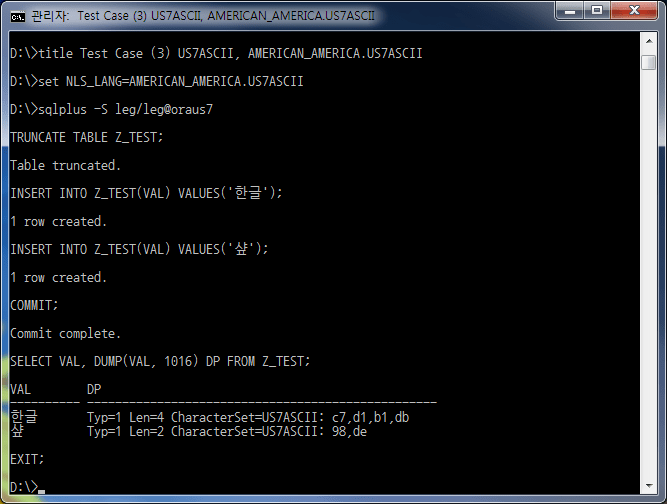
When this data is transmitted to an external system through EAI, ETL, ESB, etc., Hangul characters are broken, and it is difficult to accurately exchange data. Therefore, Case #3 is a setting that should be absolutely avoided.
Case 9-1 is a phenomenon that occurs because Unicode input/output is not supported in cmd.exe, a Windows command prompt, although the original input/output settings do not have any problems.
If you check Case 9-2 in Windows PowerShell, you can see that the input/output is normal.
In order to store multilingual characters such as Chinese characters, Japanese characters, Thai characters, and Western European characters in addition to Korean, the following two combinations are possible.
| Case # | Server Character Set | Client NLS_LANG | Comment |
| 8 | AL32UTF8 | Set according to each language character | Client NLS_LANG setting – In case of Korean: KO16MSWIN949 – Chinese characters: ZHS16GBK, or ZHT16MSWIN950, or ZHT16HKSCS – Japanese characters: JA16SJIS – Thai characters: TH8TISASCII, etc. See table below |
| 9 | AL32UTF8 | AL32UTF8 | The value stored in the server is transmitted to the client as it is without conversion. That is, the client must directly handle UTF8-encoded data. |
The list of Client NLS_LANG values mentioned above <set according to each language character> is as follows.
| Operating System Locale | NLS_LANG Value |
| Arabic (UAE) | ARABIC_UNITED ARAB EMIRATES.AR8MSWIN1256 |
| Bulgarian | BULGARIAN_BULKARIA.CL8MSWIN1251 |
| Catalan | CATALAN_CATALONIA.WE8MSWIN1252 |
| Chinese (PRC) | SIMPLIFIED CHINESE_CHINA.ZHS16GBK |
| Chinese (Taiwan) | TRADITIONAL CHINESE_TAIWAN.ZHT16MSWIN950 |
| Chinese (Hong Kong HKCS) | TRADITIONAL CHINESE_HONG KONG.ZHT16HKSCS |
| Chinese (Hong Kong HKCS2001) | TRADITIONAL CHINESE_HONG KONG.ZHT16HKSCS2001 (new in 10gR1) |
| Croatian | CROATIAN_CROATIA.EE8MSWIN1250 |
| Czech | CZECH_CZECH REPUBLIC.EE8MSWIN1250 |
| Danish | DANISH_DENMARK.WE8MSWIN1252 |
| Dutch (Netherlands) | DUTCH_THE NETHERLANDS.WE8MSWIN1252 |
| Dutch (Belgium) | DUTCH_BELGIUM.WE8MSWIN1252 |
| English (United Kingdom) | ENGLISH_UNITED KINGDOM.WE8MSWIN1252 |
| English (United States) | AMERICAN_AMERICA.WE8MSWIN1252 |
| Estonian | ESTONIAN_ESTONIA.BLT8MSWIN1257 |
| Finnish | FINNISH_FINLAND.WE8MSWIN1252 |
| French (Canada) | CANADIAN FRENCH_CANADA.WE8MSWIN1252 |
| French (France) | FRENCH_FRANCE.WE8MSWIN1252 |
| German (Germany) | GERMAN_GERMANY.WE8MSWIN1252 |
| Greek | GREEK_GREECE.EL8MSWIN1253 |
| Hebrew | HEBREW_ISRAEL.IW8MSWIN1255 |
| Hungarian | HUNGARIAN_HUNGARY.EE8MSWIN1250 |
| Icelandic | ICELANDIC_ICELAND.WE8MSWIN1252 |
| Indonesian | INDONESIAN_INDONESIA.WE8MSWIN1252 |
| Italian (Italy) | ITALIAN_ITALY.WE8MSWIN1252 |
| Japanese | JAPANESE_JAPAN.JA16SJIS |
| Korean | KOREAN_KOREA.KO16MSWIN949 |
| Latvian | LATVIAN_LATVIA.BLT8MSWIN1257 |
| Lithuanian | LITHUANIAN_LITHUANIA.BLT8MSWIN1257 |
| Norwegian | NORWEGIAN_NORWAY.WE8MSWIN1252 |
| Polish | POLISH_POLAND.EE8MSWIN1250 |
| Portuguese (Brazil) | BRAZILIAN PORTUGUESE_BRAZIL.WE8MSWIN1252 |
| Portuguese (Portugal) | PORTUGUESE_PORTUGAL.WE8MSWIN1252 |
| Romanian | ROMANIAN_ROMANIA.EE8MSWIN1250 |
| Russian | RUSSIAN_CIS.CL8MSWIN1251 |
| Slovak | SLOVAK_SLOVAKIA.EE8MSWIN1250 |
| Spanish (Spain) | SPANISH_SPAIN.WE8MSWIN1252 |
| Swedish | SWEDISH_SWEDEN.WE8MSWIN1252 |
| Thai | THAI_THAILAND.TH8TISASCII |
| Spanish (Mexico) | MEXICAN SPANISH_MEXICO.WE8MSWIN1252 |
| Spanish (Venezuela) | LATIN AMERICAN SPANISH_VENEZUELA.WE8MSWIN1252 |
| Turkish | TURKISH_TURKEY.TR8MSWIN1254 |
| Ukrainian | UKRAINIAN_UKRAINE.CL8MSWIN1251 |
| Vietnamese | VIETNAMESE_VIETNAM.VN8MSWIN1258 |
*source: NLS_LANG FAQ (oracle.com) of the document detail
A question may arise here.
The character set of the server is designated as AL32UTF8, a Unicode system, but why should the client NLS_LANG specify KO16MSWIN949, a 2 byte system?
This is because the Windows operating system is the basic method of encoding/decoding Hangul. (For reference, it is common to use KO16KSC5601 when inputting and outputting Korean characters on UNiX.) To mention it again, Server Character Set is a setting for “storing” character string data, and Client NLS_LANG “shows” character string data. , It is a setting for “Transmission”.
The server character set specifies AL32UTF8, a Unicode system, to “store” characters from various countries, and the basic encoding/decoding system supported by Windows for each language is used in the client (mainly Windows) environment of various countries that connects to this server. to specify Data entered in Non-Unicode is converted to Unicode and saved while being transmitted to the server through the Oracle client and SQL*Net.
When the server character set is AL32UTF8, if the client NLS_LANG is set to AL32UTF8, the Unicode value stored in the server is transmitted to the client without any conversion process. In other words, if the client NLS_LANG is to be set to AL32UTF8, the client must be able to encode/decode Unicode.
For reference, among the tools provided free of charge, ORACLE SQL Developer is a representative tool that supports Unicode well. DBeaver also supports Unicode well based on jdbc.
If you think that character set selection is difficult because the contents so far are complicated, you only need to remember the following contents.
- Server Character Set set to AL32UTF8
- Client NLS_LANG
- If the client cannot handle Unicode or is limited to a specific language, set the value corresponding to the language
- AL32UTF8 if the client can handle Unicode
So far, we have looked at the client environment configuration related to Oracle Character Set.
In the next article, we will look at how to convert the character set in an invalid environment where the server character set is US7ASCII and Hangul is stored.
Related articles:
 Oracle Character Set Conversion (9): 6. How to Convert User Implemented Character Sets (2)
Oracle Character Set Conversion (9): 6. How to Convert User Implemented Character Sets (2)
 Oracle Character Set Conversion(8): 6. How to Convert User Implemented Character Set (1)
Oracle Character Set Conversion(8): 6. How to Convert User Implemented Character Set (1)
 Oracle Character Set Conversion (7): 5.4. KO16MSWIN949 Environment CSSCAN Execution Result
Oracle Character Set Conversion (7): 5.4. KO16MSWIN949 Environment CSSCAN Execution Result
 Oracle Character Set Conversion (6): 5.3. US7ASCII environment CSSCAN execution result
Oracle Character Set Conversion (6): 5.3. US7ASCII environment CSSCAN execution result
 Oracle Character Set Conversion (5): 5. Oracle Recommended Practice
Oracle Character Set Conversion (5): 5. Oracle Recommended Practice
 Oracle Character Set Conversion (4): 4.Configuring the Test Environment
Oracle Character Set Conversion (4): 4.Configuring the Test Environment
 Oracle Character Set Conversion (2): 3. Configuring the Client Environment (1)
Oracle Character Set Conversion (2): 3. Configuring the Client Environment (1)
 Oracle Character Set Conversion(1): 1. Necessity, Correct Oracle Character Set Setup Guide
Oracle Character Set Conversion(1): 1. Necessity, Correct Oracle Character Set Setup Guide









