Release Word Extraction Tool v0.41: Add DBSchema occurrence frequency of words item
* Please also refer to the newly released v0.42 by fixing bugs.
Release Word Extractor v0.42: Bug fix – Productivity Skill (prodskill.com)
Distribute after supplementing the function to add and extract DBSchema occurrence frequency items of words from the previously distributed word extraction tool (v0.40). The DBSchema_Freq item informs how many DB-Schemas the source of the word is distributed.
Reference: Word Extraction Tool(1): Overview of Word Extraction Tool

source: https://stocksnap.io/photo/dictionary-page-ELRF6CYOHI
1. Word extraction tool result changes
An example of the word extraction result of the previously distributed tool is as follows.
▼ Example of “Word Frequency” sheet before change (v0.40)
| word | Freq | Source |
| code | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (administrative zone code) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (change identification code) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE (attempt code) … |
| number | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(job serial number) DB1.OWNER1.COMTCZIP.ZIP (postal code) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (approval number) … |
| number of people | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (address book name) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (classification code name) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (code name) … |
DBSchema_Freq items are added to the results extracted from v0.41 as follows.
▼ Example of “Word Frequency” sheet after change (v0.41)
| word | Freq | Source | DBSchema_Freq |
| code | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (administrative zone code) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (change identification code) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE (attempt code) … | 10 |
| number | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(job serial number) DB1.OWNER1.COMTCZIP.ZIP (postal code) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (approval number) … | 9 |
| number of people | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (address book name) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (classification code name) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (code name) … | 5 |
The DBSchema_Freq item informs how many DB-Schemas the source of the word is distributed. Information necessary for selecting standard word candidates can be provided in a little more detail.
- When the frequency (Freq) is high but the DBSchema frequency (DBSchema_Freq) is low
- The word occurs intensively only in a specific DB-Schema
- When both frequency (Freq) and DBSchema frequency (DBSchema_Freq) are high
- The word is evenly distributed throughout the entire DB-Schema
- When the frequency (Freq) is low but the DBSchema frequency (DBSchema_Freq) is relatively high
- The word is reviewed for inclusion rather than exclusion in the canonical word candidates
2. Source code changes
There are changes to three functions.
2.1. Changed the get_db_comment_text function
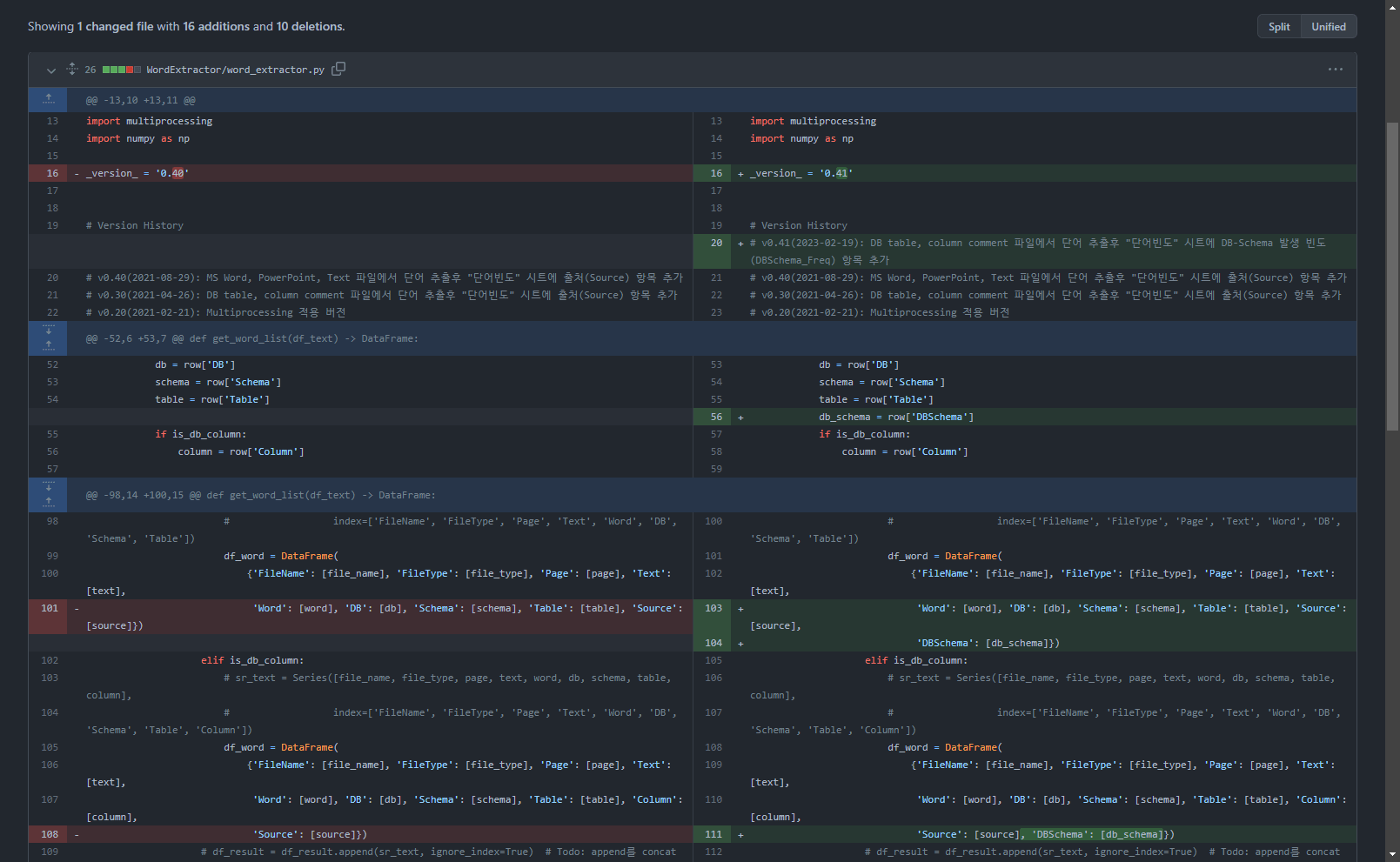
Add line 343: Create a DBSchema column in the dataframe variable df_text containing the text extraction result and create a value.
df_text['DBSchema'] = df_text['DB'] + '.' + df_text['Schema'] # DB.Schema 값 생성(2023-02-19)
2.2. Change the get_word_list function
Add line 104, 111: Add DBSchema value to word extraction result dataframe
if len(words) >= 1:
# print(nouns, text)
for word in words:
# print(noun, '\t', text)
if not is_db:
# sr_text = Series([file_name, file_type, page, text, word],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'Source': [source]})
elif is_db_table:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Source': [source],
'DBSchema': [db_schema]})
elif is_db_column:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table, column],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table', 'Column'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Column': [column],
'Source': [source], 'DBSchema': [db_schema]})
2.3. change the main function
2.3.1. Main function content before change
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
2.3.2. Main function content after change
df_group = df_result.groupby('Word').agg({
'Word': 'count',
'Source': lambda x: '\n'.join(list(x)[:10]),
'DBSchema': 'nunique'
}).rename(columns={
'Word': 'Freq',
'Source': 'Source',
'DBSchema': 'DBSchema_Freq'
})
This code groups word (word) in df_result, which is a dataframe variable as a result of word extraction, (groupby), obtains the number (nunique) of DBSchema values with duplicates removed, and names the item as DBSchema_Freq.
For reference, this code is the test code I wrote. ChatGPTThis is the code that was given to and requested for simplification. Before simplification, it was a complex code that divided into two dataframes, applied lambda and nunique to each, and then merged them into one. recently ChatGPT admiring the ability
2.4. Full details of the source code changed in v0.41
You can check the details of the changes in the github link below.
3. Download and run Word Extraction Tool (v0.41)
You can check the changed word_extractor.py file in the link below.
ToolsForDataStandard/word_extractor.py at main DAToolset/ToolsForDataStandard (github.com)
The execution method is the same as v0.40. Please refer to the information below.
Word extraction tool v0.41 is not well tested and may introduce errors or bugs. Please leave any errors, bugs, inquiries, etc. in the comments.
Related articles:
 Word Extraction Tool v0.42 release: Bug fix
Word Extraction Tool v0.42 release: Bug fix
 Full Contents of Word Extraction Tool Description , Download
Full Contents of Word Extraction Tool Description , Download
 Word Extraction Tool (6): Additional Description of Word Extraction Tool
Word Extraction Tool (6): Additional Description of Word Extraction Tool
 Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
Word Extraction Tool(5): Word Extraction Tool Source Code Description(2)
 Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
Word Extraction Tool(4): Word Extraction Tool Source Code Description(1)
 Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
Word Extraction Tool (3): How to Run the Word Extraction Tool and Check the Results
 Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
Word Extraction Tool (2): Configure the Word Extraction Tool Execution Environment
 Word Extraction Tool(1): Overview of Word Extraction Tool
Word Extraction Tool(1): Overview of Word Extraction Tool










hello!
When using the method of extracting words from a file without a DB comment, which is one of the three execution methods
(python word_extractor.py –in_path .\in –out_path .\out)
txt, word, ppt all
miniconda3\envs\wordextr\lib\site-packages\pandas\core\apply.py”, line 601, in normalize_dictlike_arg raise KeyError(f”Column(s) {cols_sorted} do not exist”)
KeyError: “Column(s) ['DBSchema'] do not exist”
It is exiting with an error.
Execution methods 2 and 3, where the DB comment file is entered, are working without errors.
I put 'DBSchema': [db_schema] on line 97, but this time
In get_grouper raise KeyError(gpr) KeyError: 'Word' error is displayed.
thank you
Thanks for reporting the bug.
You deployed without testing the case of extracting words only from File.
We will re-release a tested and bugfixed version soon.
Re-released v0.42 with bug fixes.
https://prodskill.com/ko/word-extractor-v0-42-bug-fix-for-dbschema/
thank you