4. Fall der benutzerdefinierten SQL-partitionierten parallelen Verarbeitung (DBMS_PARALLEL_EXECUTE)
Werfen wir einen Blick auf den Fall der benutzerdefinierten SQL-Partitionierungsparallelität mit Oracle DBMS_PARALLEL_EXECUTE. Es umfasst das Schreiben von benutzerdefiniertem SQL, die Testumgebung, die Joberstellung, die Jobteilung, die Jobausführung, die Jobabschlussbestätigung und das Löschen.
Dies ist eine Fortsetzung des vorherigen Artikels.
3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
* Verweis auf die Oracle-Dokumentation: DBMS_PARALLEL_EXECUTE – CREATE_CHUNKS_BY_SQL-Prozedur (oracle.com)
4. Fall der benutzerdefinierten SQL-Partitionierung bei paralleler Verarbeitung
4.1. Überblick über benutzerdefinierte SQL-Partitionierungsmethoden
Die Partitionierung durch benutzerdefiniertes SQL ist in den folgenden Fällen nützlich.
- Partitionierung in Fällen, in denen die ROWID-Partitionierungsmethode nicht unterstützt wird (z. B. ROWID-Partitionierung für entfernte Tabellen über DB Link)
- Aufteilung basierend auf anderen Spalten als NUMBER-Spalte (VARCHAR2, DATE usw.)
Hier erläutern wir im ersten Fall den Fall der ROWID-Teilung durch DB Link.
Wenn Sie versuchen, die ROWID einer Tabelle über DB Link mit CREATE_CHUNKS_BY_ROWID aufzuteilen, Ein Fehler tritt auf.
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)');
END;
/
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE
.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)',
TABLE_OWNER => USER,
-- TABLE _NAME을 “T1@DL_MS949”로 DB Link 지정
TABLE_NAME => 'T1@DL_MS949',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
--> 실행 오류 메시지
ORA-29491: 조각에 부적합한 테이블
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 27행
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 121행
ORA-06512: 4행
In diesem Fall kann SQL, das die ROWID der Tabelle auf dem DB-Link teilt, erstellt und über CREATE_CHUNKS_BY_SQL angewendet werden.
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL ( task_name IN VARCHAR2, sql_stmt IN CLOB, by_rowid IN BOOLEAN);
sql_stmt ist ein CLOB-Typ und kann fast ohne Einschränkungen hinsichtlich seiner Länge verwendet werden, aber hier schlagen wir eine Möglichkeit vor, eine Pipeline-Funktion zu verwenden, anstatt SQL direkt zu beschreiben.
4.2. Benutzerdefiniertes SQL schreiben
Erstellen Sie einen benutzerdefinierten Typ und eine Pipelinefunktion, die eine Ergebnismenge dieses Typs wie folgt zurückgibt.
-- 1. TYPE 생성 (Pipe-Lined function에서 return하기 위함)
CREATE OR REPLACE TYPE TP_ROWID_RANGE AS OBJECT (
START_ROWID VARCHAR2(50)
,END_ROWID VARCHAR2(50)
);
CREATE OR REPLACE TYPE TL_ROWID_RANGE AS TABLE OF TP_ROWID_RANGE;
-- 2. Function 생성
CREATE OR REPLACE FUNCTION FN_SPLIT_BY_ROWID(
I_OWNER IN VARCHAR2, I_TABLE_NAME IN VARCHAR2, I_CHUNKS IN NUMBER)
RETURN TL_ROWID_RANGE
PIPELINED
AS
CURSOR C_ROWID_RANGE (CP_OWNER VARCHAR2, CP_TABLE_NAME VARCHAR2, CP_CHUNKS NUMBER)
IS
SELECT GRP,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, LO_FNO, LO_BLOCK, 0 ) MIN_RID,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, HI_FNO, HI_BLOCK, 10000 ) MAX_RID
FROM (
SELECT DISTINCT GRP,
FIRST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_FNO,
FIRST_VALUE(BLOCK_ID)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_BLOCK,
LAST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_FNO,
LAST_VALUE(BLOCK_ID+BLOCKS-1)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_BLOCK,
SUM(BLOCKS) OVER (PARTITION BY GRP) SUM_BLOCKS
FROM (
SELECT RELATIVE_FNO, BLOCK_ID, BLOCKS,
TRUNC( (SUM(BLOCKS) OVER (ORDER BY RELATIVE_FNO, BLOCK_ID)-0.01) /
(SUM(BLOCKS) OVER ()/ CP_CHUNKS) ) GRP
FROM DBA_EXTENTS@DL_MS949
WHERE SEGMENT_NAME = UPPER(CP_TABLE_NAME)
AND OWNER = UPPER(CP_OWNER)
ORDER BY BLOCK_ID
)
),
(SELECT DATA_OBJECT_ID
FROM DBA_OBJECTS@DL_MS949
WHERE OWNER = UPPER(CP_OWNER)
AND OBJECT_NAME = UPPER(CP_TABLE_NAME))
ORDER BY GRP
;
BEGIN
FOR ROWID_RANGE IN C_ROWID_RANGE(I_OWNER, I_TABLE_NAME, I_CHUNKS) LOOP
PIPE ROW(TP_ROWID_RANGE(ROWID_RANGE.MIN_RID, ROWID_RANGE.MAX_RID));
END LOOP;
RETURN;
END;
/
Das in der obigen Funktion verwendete SQL ist eine ROWID-Division in Blockeinheiten basierend auf DBA_EXTENTS und wurde leicht modifiziert, um DB Link zu verwenden, indem auf die von Thomas Kyte vorgeschlagene Technik verwiesen wird.
* Referenz-URL: https://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:10498431232211
DB Link wurde durch Angabe von DL_MS949 verwendet.Wenn Sie auch DB Link dynamisch festlegen möchten, können Sie den Cursor-SQL-Wert der obigen Funktion in dynamisches SQL ändern und verwenden.
Wenn die LEG.SUB_MON_STAT-Tabelle (Gesamtzahl 7.426) mit dieser Funktion nach ROWID partitioniert wird, ist sie wie folgt.
-- DL_MS949 DB Link상의 LEG owner, SUB_MON_STAT table에 대해 4개의 Chunk로 ROWID 분할
SELECT ROWNUM RNO, START_ROWID, END_ROWID
FROM TABLE(FN_SPLIT_BY_ROWID('LEG', 'SUB_MON_STAT', 4))
;
| Reihe# | START_ROWID | END_ROWID |
| 1 | AAAQXFAAEAAAACIAAA | AAAQXFAAEAAAAC3CcQ |
| 2 | AAAQXFAAEAAAAC4AAA | AAAQXFAAAEAAAADHcQ |
| 3 | AAAQXFAAAEAAAADIAAA | AAAQXFAAAEAAAADXCcQ |
| 4 | AAAQXFAAEAAAADYAAA | AAAQXFAAAEAAAAADnCcQ |
Überprüfen Sie beim Aufteilen von Daten mit der hier generierten ROWID, ob es Auslassungen in den gesamten Daten mit der folgenden SQL gibt.
SELECT R.RNO, COUNT(*) CNT
FROM SUB_MON_STAT S
,(
SELECT 1 RNO, 'AAAQXFAAEAAAACIAAA' START_ROWID, 'AAAQXFAAEAAAAC3CcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 2 RNO, 'AAAQXFAAEAAAAC4AAA' START_ROWID, 'AAAQXFAAEAAAADHCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 3 RNO, 'AAAQXFAAEAAAADIAAA' START_ROWID, 'AAAQXFAAEAAAADXCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 4 RNO, 'AAAQXFAAEAAAADYAAA' START_ROWID, 'AAAQXFAAEAAAADnCcQ' END_ROWID FROM DUAL
) R
WHERE S.ROWID BETWEEN R.START_ROWID AND END_ROWID
GROUP BY R.RNO
ORDER BY R.RNO
;
Das Ausführungsergebnis ist wie folgt. (CNT kann für jede Testumgebung variieren.)
| RNO (Stücknummer) | CNT |
| 1 | 1,790 |
| 2 | 2,206 |
| 3 | 2,209 |
| 4 | 1,221 |
Die Summe von CNT beträgt 7.426, was der Gesamtzahl der Zeilen in der Tabelle entspricht, was bestätigt, dass keine Auslassung vorliegt. Hier beträgt die Anzahl der Zeilen, die in jede RNO unterteilt sind, 1790, 2206, 2209 bzw. 1221, was nicht gleich ist. Dies ist derselbe Grund dafür, dass die Partitionierung nicht gleichmäßig erfolgt, wie in der ROWID-Partitionierungsmethode beschrieben.
4.3. Testumgebung und Testtabelle erstellen
Ziel-DB bei
- Quell-DB mit DB-Link von Tisch Fahren Sie unter der Annahme eines in importierten Testszenarios mit der folgenden Umgebungskonfiguration fort.
- Wenn die Zieltabelle eine partitionierte Tabelle und die DML ein INSERT ist
- Bei der Partitionierung nach der Anzahl der Partitionen und der Verarbeitung von Daten in Einheiten von Partitionsschlüsseln wird erwartet, dass Direct Path I/O möglich ist. (Ich habe es nicht getestet, aber es scheint möglich)
- Verwenden Sie den Hinweis /*+ APPEND */ in der INSERT-Syntax und setzen Sie die Partition auf NOLOGGING
- Wenn die Zieltabelle eine nicht partitionierte Tabelle ist
- Direct Path I/O ist nicht möglich und nur konventionelle I/O ist möglich
- Da die Menge an UNDO sehr groß sein kann, ist es notwendig, sich im Voraus freien Speicherplatz zu sichern.
- Wenn Sie die Chunk-Größe auf eine kleine Größe einstellen, können Sie die Größe von UNDO in gewissem Maße einschränken.
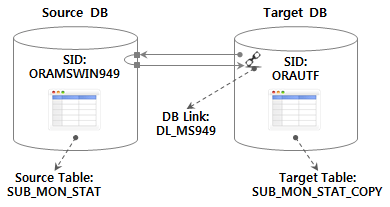
Ziel-DB Die Tabelle wird vorab mit der folgenden DDL erstellt.
CREATE TABLE SUB_MON_STAT_COPY AS SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM, RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT FROM SUB_MON_STAT@DL_MS949 WHERE 1=2;
4.4. Arbeitsplatz schaffen
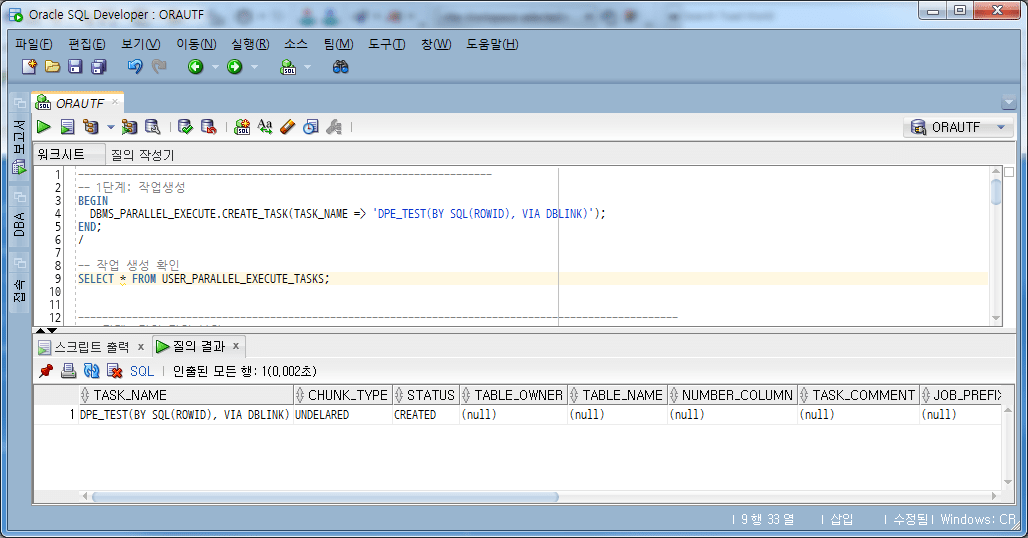
4.4.1. Arbeitsplatz schaffen
-- 1단계: 작업생성 BEGIN DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; / -- 작업 생성 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
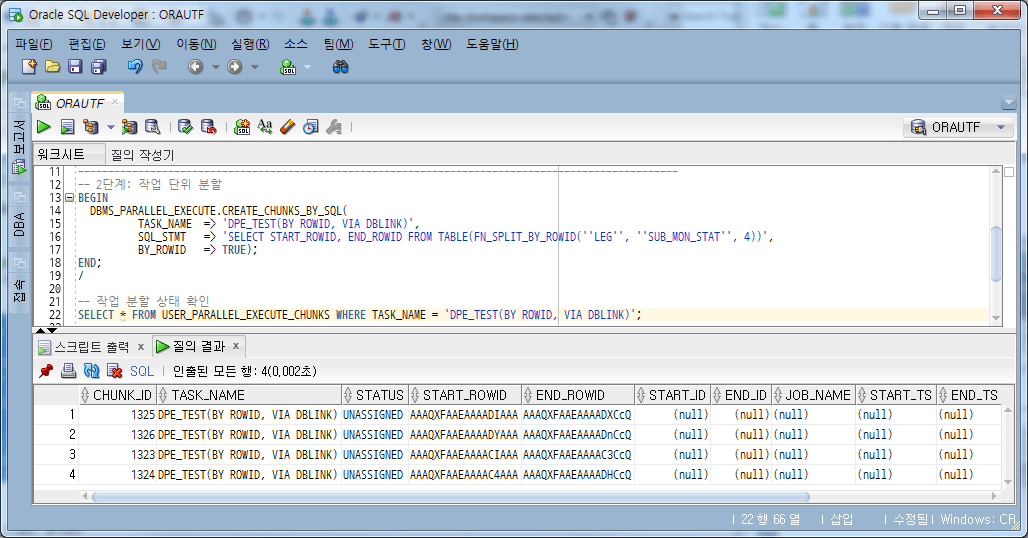
4.4.2. Geteilte Arbeitseinheit
Verwenden Sie die Funktion FN_SPLIT_BY_ROWID, um die Arbeitseinheit in 4 zu benennen/aufzuteilen.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(
TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => 'SELECT START_ROWID, END_ROWID FROM TABLE(FN_SPLIT_BY_ROWID(''LEG'', ''SUB_MON_STAT'', 4))',
BY_ROWID => TRUE);
END;
/
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
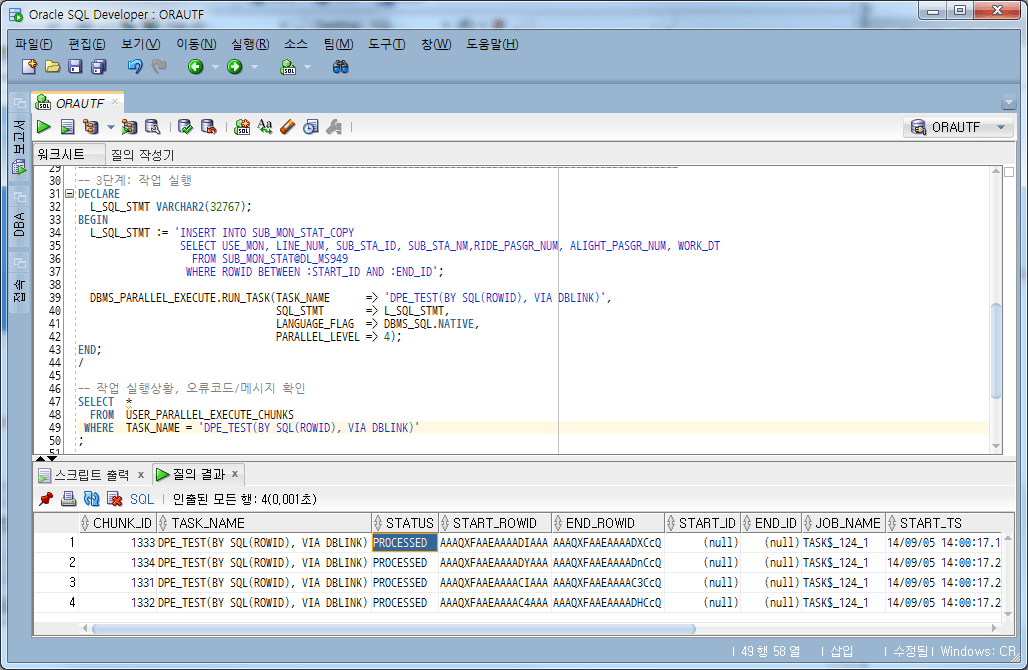
4.5. Job ausgeführt
Führen Sie die Aufgabe aus, indem Sie die ROWID-Bedingung in der WHERE-Klausel angeben. Hier wird die Anzahl der Aufgaben auf 4 gesetzt, genauso wie die Anzahl der Arbeitseinheiten.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'INSERT INTO SUB_MON_STAT_COPY
SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM,RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT
FROM SUB_MON_STAT@DL_MS949
WHERE ROWID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 4);
END;
/
-- 작업 실행상황, 오류코드/메시지 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
4.6. Aufgabenabschluss bestätigen und löschen
Sie können den Jobabschluss mit dem folgenden SQL überprüfen.
-- 작업 완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;

DROP_TASK( ), um den Auftrag zu löschen.
-- 4단계: 작업삭제 BEGIN DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; /
5. Überlegungen
Oben haben wir uns angesehen, wie DBMS_PARALLEL_EXECUTE verwendet wird. Dies ist eine Methode, die ich gefunden habe, als ich vor einigen Jahren in einem Projekt über DB Link nach dem parallelen Laden von Tabellen gesucht habe, die CLOB-Spalten enthalten. Ich hoffe, ich habe es für jeden, der es verwenden möchte, gut genug erklärt.
Wenn Sie Fragen haben, hinterlassen Sie diese bitte in den Kommentaren.
In Verbindung stehende Artikel:
 Konvertierung von Oracle-Zeichensätzen (7): 5.4. KO16MSWIN949 CSSCAN-Ausführungsergebnis der Umgebung
Konvertierung von Oracle-Zeichensätzen (7): 5.4. KO16MSWIN949 CSSCAN-Ausführungsergebnis der Umgebung
 Konvertierung von Oracle-Zeichensätzen (6): 5.3. CSSCAN-Ausführungsergebnis der US7ASCII-Umgebung
Konvertierung von Oracle-Zeichensätzen (6): 5.3. CSSCAN-Ausführungsergebnis der US7ASCII-Umgebung
 Oracle-Zeichensatzkonvertierung (5): 5. Von Oracle empfohlene Vorgehensweise
Oracle-Zeichensatzkonvertierung (5): 5. Von Oracle empfohlene Vorgehensweise
 DBMS_PARALLEL_EXECUTE Beschreibung Inhaltsverzeichnis
DBMS_PARALLEL_EXECUTE Beschreibung Inhaltsverzeichnis
 3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
 2.5. Detailprüfung der Aufteilung der Arbeitseinheiten (DBMS_PARALLEL_EXECUTE)
2.5. Detailprüfung der Aufteilung der Arbeitseinheiten (DBMS_PARALLEL_EXECUTE)
 2. ROWID-Partitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
2. ROWID-Partitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
 1. Übersicht über Parallelität in DML-Aufgaben (DBMS_PARALLEL_EXECUTE)
1. Übersicht über Parallelität in DML-Aufgaben (DBMS_PARALLEL_EXECUTE)









