2.5. Detailprüfung der Aufteilung der Arbeitseinheiten (DBMS_PARALLEL_EXECUTE)
Dies bezieht sich auf die Überprüfung der Details der Aufteilung der Arbeitseinheiten. Untersuchen Sie den Grad, in dem das Ergebnis der Division von Arbeitseinheiten (Chunks) durch ROWID gleichmäßig geteilt wird, ob die Summe der Arbeitseinheiten gleich dem Ganzen ist und ob es keine Auslassungen gibt, und die Korrelation zwischen der Anzahl der Arbeitseinheiten und die Zahl der Arbeitsplätze.
Dies ist eine Fortsetzung des vorherigen Artikels.
2. Parallelverarbeitungsfall des ROWID-Divisionsverfahrens
2.5. Prüfung der Details der Abteilung der Arbeitseinheit
Werfen wir einen Blick auf das Folgende, um zu sehen, ob die Arbeitseinheit gut aufgeteilt ist.
- Einheitlichkeit der durch ROWID partitionierten Arbeitseinheiten
- Stellen Sie sicher, dass keine Arbeitseinheiten geteilt durch ROWID fehlen
- Korrelation zwischen der Anzahl der Arbeitseinheiten (Chunks) und dem PARALLEL_LEVEL (der Anzahl der auszuführenden Jobs)
2.5.1. Einheitlichkeit der durch ROWID partitionierten Arbeitseinheiten
Die folgende Aufteilung bedeutet, die Tabelle Z_DPE_TEST_TAB basierend auf der ROW-Anzahl in 10.000 Arbeitseinheiten aufzuteilen.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
Mal sehen, ob es wirklich durch 10.000 geteilt wird.
-- 작업단위 개수 확인 --> 115 SELECT COUNT(*) FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY ROWID)';
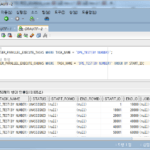
Da die Gesamtzahl der Zeilen 1.000.000 beträgt, scheint es, dass sie in 100 Blöcke unterteilt werden sollte, wenn sie in 10.000 Zeilen unterteilt ist, aber in Wirklichkeit ist sie in 115 Blöcke unterteilt.
Wenn Sie die Zeilenanzahl für jeden Chunk berechnen,
SELECT B.CHUNK_ID, COUNT(A.ID), MIN(A.ID) MIN_ID, MAX(A.ID) MAX_ID
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
Sie können sehen, dass es in verschiedene Counts unterteilt ist, z. B. 1334, 2064 und 1886, nicht 10.000.
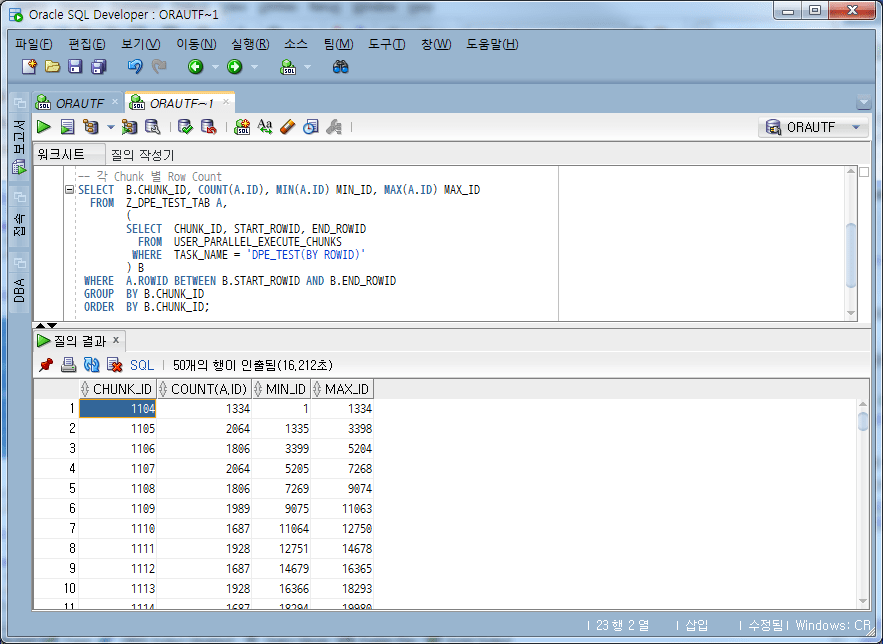
Die Anzahl der im Block enthaltenen Zeilen beträgt 14 im Abschnitt mit 1.000–2.000 Zeilen, 2 im Abschnitt mit 2.000 Zeilen, 33 im Abschnitt mit 6.000 Zeilen, 64 im Abschnitt mit 11.000 Zeilen und 2 im Abschnitt mit 12.000 Zeilen. (Möglicherweise ergibt es nicht jedes Mal das gleiche Ergebnis.)
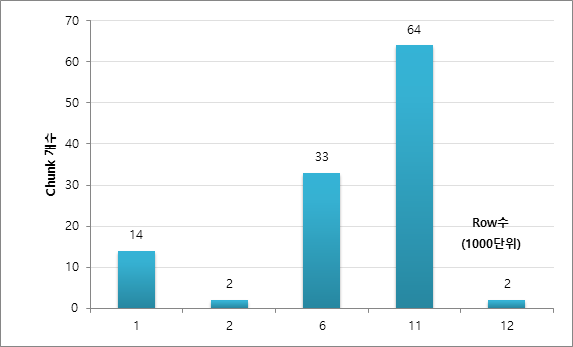
Als solches ist es nicht in eine völlig gleiche Anzahl von Zeilen unterteilt. Dies scheint daran zu liegen, dass die ROWID-Partitionierungsmethode auf DBA_EXTENTS basiert und die Anzahl der in jedem EXTENT enthaltenen Blöcke und die ROW-Anzahl jedes Blocks unterschiedlich sein können. Wenn durch DELETE usw. ungenutzte BLOCKS in der Tabelle vorhanden sind, kann ein ROWID-Abschnitt, in dem tatsächlich keine Daten vorhanden sind, als Chunk erstellt werden. Dies wird auch erwartet, wenn Daten gelöscht werden, nachdem sie DBA_EXTENT zugewiesen wurden, oder wenn EXTENTs zugewiesen wurden, aber keine eigentlichen Daten enthalten.
2.5.2. Stellen Sie sicher, dass keine Arbeitseinheiten geteilt durch ROWID fehlen
Könnten Daten fehlen, wenn die Abschnitte START_ROWID und END_ROWID jedes Blocks maximiert werden?
Lassen Sie uns zuerst die Zeilenanzahl überprüfen.
-- Chunk의 RowID range로 추출한 Row Count
SELECT COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID;
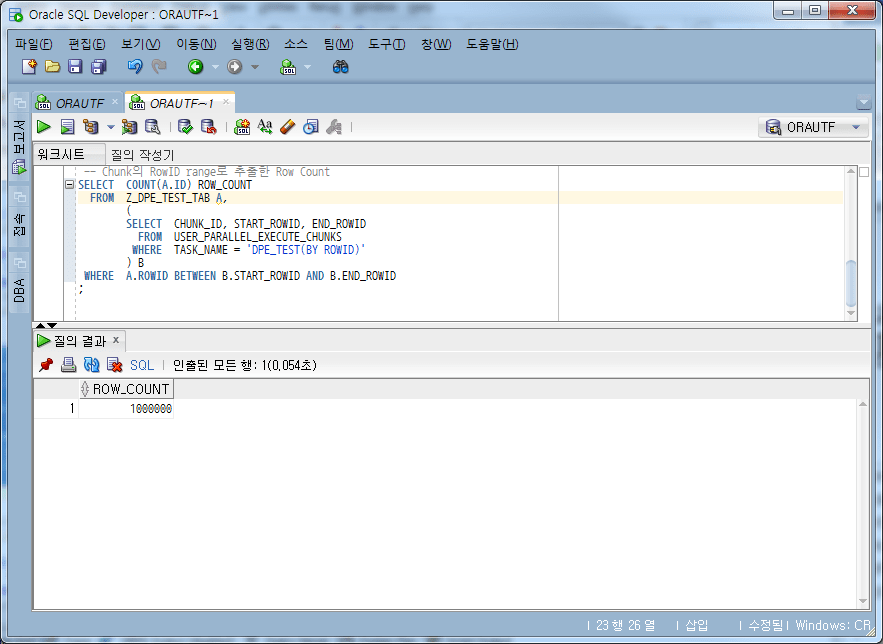
Übereinstimmung mit der Gesamtzeilenanzahl von 1.000.000, nachdem bestätigt wurde, dass die Anzahl nicht fehlte, und dann, basierend auf den im Bereich von START_ROWID bis END_ROWID des Chunks extrahierten Daten, wenn die ursprünglichen Daten LEFT OUTER JOINed waren, fehlt (missing) ). sehen, ob die Daten vorhanden sind.
-- Chunk의 RowID로 추출한 데이터의 누락없음 확인
SELECT *
FROM Z_DPE_TEST_TAB A LEFT OUTER JOIN
(
SELECT A.ID -- Chunk의 RowID range로 추출한 데이터
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ROWID, END_ROWID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY ROWID)'
) B
WHERE A.ROWID BETWEEN B.START_ROWID AND B.END_ROWID
) B ON (A.ID = B.ID)
WHERE B.ID IS NULL;
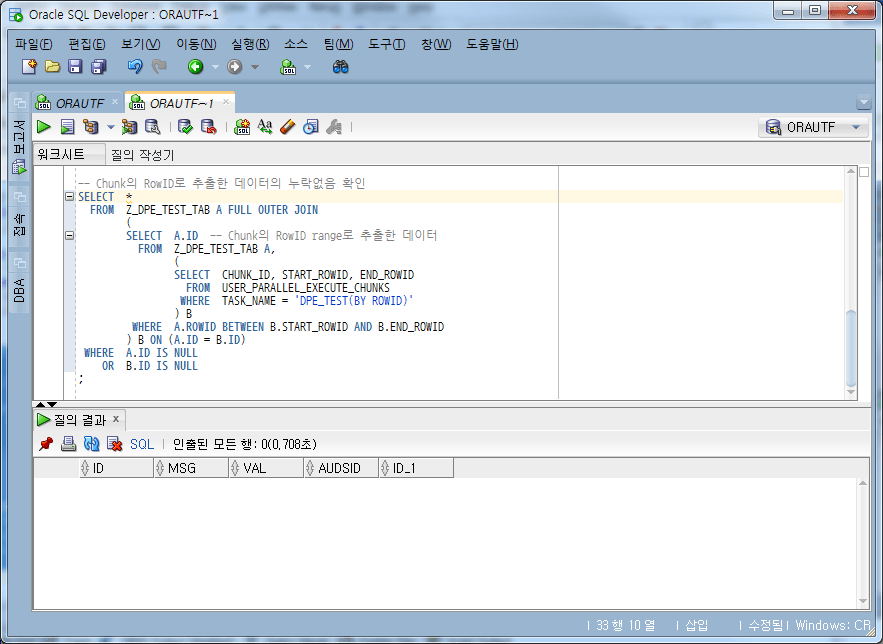
Aus den obigen Ergebnissen ist ersichtlich, dass es keine fehlenden Daten gibt.
2.5.3. Korrelation zwischen der Anzahl der Arbeitseinheiten (Chunks) und dem PARALLEL_LEVEL (der Anzahl der auszuführenden Jobs)
<2.3. In Task Execution> gab es folgenden Inhalt.
PARALLEL_LEVEL bedeutet die Anzahl von Jobs, die gleichzeitig ausgeführt werden sollen, d. h. den Parallelitätsgrad (DOP), und kann gleich oder kleiner sein als die Anzahl von Chunks, die Arbeitseinheiten sind. Im gleichen Fall verarbeitet ein Job einen Chunk, und in einem kleinen Fall verarbeitet ein Job mehrere Chunks.
* Bezug: 2. Parallelverarbeitungsfall der ROWID-Teilungsmethode_2.3. Job ausgeführt
Betrachten Sie die folgenden Fälle in Bezug auf die Anzahl der Chunks und die Anzahl der Jobs.
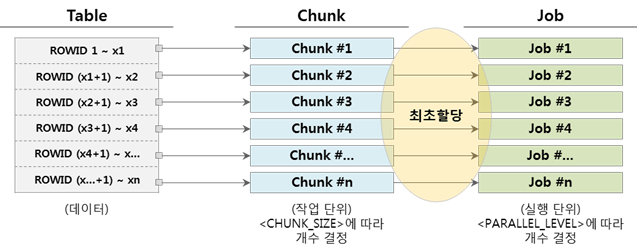
▼ Wenn die Anzahl der Chunks und die Anzahl der Jobs gleich sind (Chunk = Job)
Wenn ein Job die Ausführung des zugewiesenen Chunks abschließt, endet er, da keine Jobs mehr ausgeführt werden müssen.
▼ Wenn die Anzahl der Jobs geringer ist als die Anzahl der Chunks (Chunk > Job)
Wenn der Job des Chunks, dem der Job zugewiesen ist, abgeschlossen ist, wird der Chunk, der noch nicht ausgeführt wurde, zugewiesen und kontinuierlich ausgeführt. Unten ist ein Beispiel, wenn es 3 Jobs gibt.
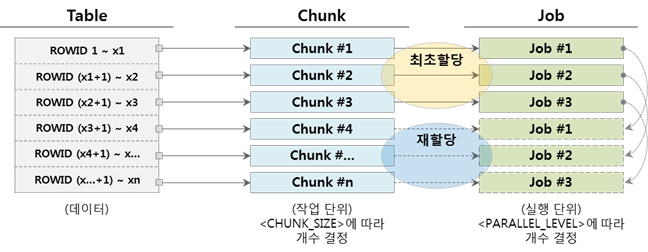
Wenn die Anzahl der Jobs größer ist als die Anzahl der Chunks (Chunk < Job), ist dies außerdem möglich, sollte jedoch besser nicht angewendet werden, da Chunks nicht zugewiesen werden und unnötige Ressourcen verwendet werden können, indem der Status „Running“ beibehalten wird .
* Bezug: Beispiel für DBMS_PARALLEL_EXECUTE Chunk nach ROWID
Bisher haben wir uns die ROWID-Partitionierungsmethode angesehen. Sehen Sie sich als Nächstes die NUMBER-Spaltenpartitionierungsmethode an.
In Verbindung stehende Artikel:
 Konvertierung von Oracle-Zeichensätzen (10): 6.3. So konvertieren Sie den CLOB-Typ in Koreanisch
Konvertierung von Oracle-Zeichensätzen (10): 6.3. So konvertieren Sie den CLOB-Typ in Koreanisch
 Oracle-Zeichensatzkonvertierung (3): 3. Konfiguration der Client-Umgebung (2)
Oracle-Zeichensatzkonvertierung (3): 3. Konfiguration der Client-Umgebung (2)
 Oracle-Zeichensatzkonvertierung (2): 3. Konfigurieren der Client-Umgebung (1)
Oracle-Zeichensatzkonvertierung (2): 3. Konfigurieren der Client-Umgebung (1)
 DBMS_PARALLEL_EXECUTE Beschreibung Inhaltsverzeichnis
DBMS_PARALLEL_EXECUTE Beschreibung Inhaltsverzeichnis
 4. Fall der benutzerdefinierten SQL-partitionierten parallelen Verarbeitung (DBMS_PARALLEL_EXECUTE)
4. Fall der benutzerdefinierten SQL-partitionierten parallelen Verarbeitung (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
 2. ROWID-Partitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
2. ROWID-Partitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
 1. Übersicht über Parallelität in DML-Aufgaben (DBMS_PARALLEL_EXECUTE)
1. Übersicht über Parallelität in DML-Aufgaben (DBMS_PARALLEL_EXECUTE)









