1. Übersicht über Parallelität in DML-Aufgaben (DBMS_PARALLEL_EXECUTE)
Stellt DBMS_PARALLEL_EXECUTE vor, das von Oracle 11g R2 verwendet werden kann, und untersucht Anwendungsfälle.
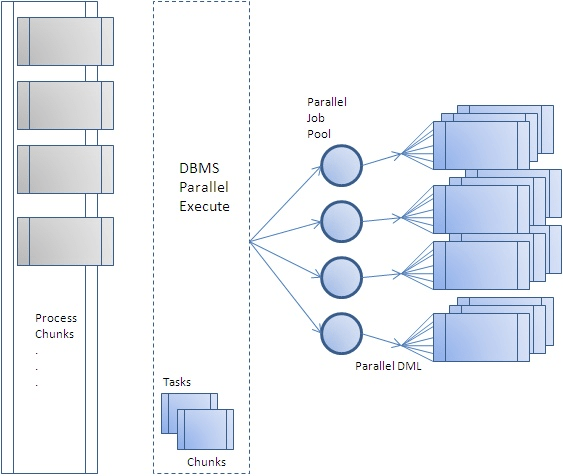
Bildquelle: https://blogs.oracle.com/warehousebuilder/parallel-processing-with-dbmsparallelexecute
1. Überblick über die parallele Verarbeitung von DML-Aufgaben
1.1. DML-Parallelverarbeitungsmethode
Die parallele Verarbeitung wird verwendet, wenn Sie schnell einen DML-Job (INSERT, UPDATE, DELETE) in der Datenbank mit möglichst vielen Ressourcen verarbeiten möchten. Es gibt zwei Hauptmethoden der Parallelverarbeitung.
Die erste Methode besteht darin, den Parallelitätsgrad als Hinweis anzugeben, während eine SQL ausgeführt wird (Parallel-DML, Einzeltransaktion), und die zweite Methode besteht darin, mehrere SQLs auszuführen, indem ein Bereich von Daten angegeben wird (Program Parallel DML, Multi Transaction). Sein.
In den meisten Fällen ist die erste Methode, die parallele DML-Methode, hinsichtlich der Datenkonsistenz vorteilhaft, da sie als einzelne Transaktion verarbeitet wird. Wenn die erste Methode jedoch nicht anwendbar ist oder Sie die Größe oder den Umfang der Arbeitseinheit selbst definieren möchten, wenden Sie besser die zweite Methode an. (Die zweite Methode heißt also auch DIY (Do It Yourself) Parallel DML)
Beispiele für Situationen, in denen Parallel DML nicht angewendet werden kann, sind die folgenden.
- DML, um eine Tabelle mit LOB-Spalten auszuwählen
- DML auf DB Link
- Parallelverarbeitung von DML in PL/SQL-Einheiten anstelle von SQL-Einheiten oder Prozedureinheiten, die in komplexen Prozeduren implementiert sind
- DML, die nicht in PL/SQL implementiert ist und in einer Sprache wie Java ausgeführt wird
Die Schritte zum Ausführen von Program Parallel DML unterscheiden sich je nach Situation leicht, sind aber im Allgemeinen wie folgt.
- Auswahl des Arbeitsziels
- Auswahl der Parallelität und Aufteilung der Arbeitseinheiten (Partition, Datum, Nummer, ROWID usw.) -> Erstellung von .sql-Dateien nach Arbeitseinheiten
- Aufgabenausführung und Überwachung -> Führen Sie jede .sql-Datei in einer einzelnen Sitzung aus (SQL*Plus usw.)
- Task-Erledigung bestätigen -> Verifizierung von Reihenzahlvergleich, Summenvergleich etc.
Wenn sich Anforderungen oder Situationen ändern und der Parallelitätsgrad (DOP) geändert werden muss oder eine Nacharbeit erforderlich ist, werden die Schritte 2 und 3 wiederholt ausgeführt, und die Verwaltung und Bestätigung sind nicht einfach. Es ist unbequem, ähnliche Aufgaben immer wieder manuell wiederholen zu müssen, wenn eine Änderung erforderlich ist.
1.2. DBMS_PARALLEL_EXECUTE-Konzept
Bei Verwendung der Program Parallel-Methode kann die Verwendung von DBMS_PARALLEL_EXECUTE diese Aufgabe bequemer ausführen und verwalten.
* Referenz-Oracle-Dokument: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS233
(Als Referenz verwendet DBMS_PARALLEL_EXECUTE JOB intern, daher muss dem ausführenden Benutzer die CREATE JOB-Berechtigung erteilt werden.)
DBMS_PARALLEL_EXECUTE ist ein Paket, das als neue Funktion in Oracle 11g R2 eingeführt wurde. Die Liste der wichtigsten Unterprogramme ist in der folgenden Tabelle aufgeführt, und die vollständige Liste und Erklärung finden Sie im Oracle-Dokument.
| Unterprogramm | Erläuterung |
| CREATE_TASK-Prozedur | Erstellen Sie eine Aufgabe |
| CREATE_CHUNKS_BY_NUMBER_COL Prozedur | Erstellen Sie Chunk nach NUMBER-Spalte |
| CREATE_CHUNKS_BY_ROWID-Prozedur | Chunks mit ROWID erstellen |
| CREATE_CHUNKS_BY_SQL-Prozedur | Chunks mit benutzerdefiniertem SQL erstellen |
| DROP_TASK-Prozedur | Aufgabe entfernen |
| DROP_CHUNKS-Prozedur | Brocken eliminieren |
| RESUME_TASK Prozeduren | Führen Sie eine angehaltene Aufgabe erneut aus |
| RUN_TASK-Prozedur | Führen Sie die Aufgabe aus |
| STOP_TASK-Prozedur | Stoppen Sie die Aufgabe |
| TASK_STATUS-Prozedur | Gibt den aktuellen Status der Aufgabe zurück |
Die Schritte zum Anwenden von DBMS_PARALLEL_EXECUTE ähneln fast den Schritten zum Ausführen von Program Parallel DML wie folgt.
- Aufgabe erstellen (CREATE_TASK)
- Aufteilung der Arbeitseinheit (Chunk) (drei Methoden von ROWID, NUMBER und SQL werden bereitgestellt)
- CREATE_CHUNKS_BY_ROWID
- CREATE_CHUNKS_BY_NUMBER_COL
- CREATE_CHUNKS_BY_SQL
- Aufgabe ausführen (RUN_TASK)
- Nach Abschluss der Aufgabe löschen (DROP_TASK)
1.3. Erstellen Sie Tabellen und Daten für den DBMS_PARALLEL_EXECUTE-Test
Erstellen Sie mit dem folgenden Skript zu testende Tabellen und Daten.
-- 테스트 테이블과 데이터 생성
DROP TABLE Z_DPE_TEST_TAB PURGE;
CREATE TABLE Z_DPE_TEST_TAB (
ID NUMBER(10)
,MSG VARCHAR2(100)
,VAL NUMBER
,AUDSID NUMBER
) NOLOGGING;
-- 100만건 테스트 데이터 생성
INSERT /*+ APPEND */ INTO Z_DPE_TEST_TAB (ID, MSG)
SELECT LEVEL AS ID
,'Test Data ID: ' || TO_CHAR(LEVEL)
FROM DUAL
CONNECT BY LEVEL <= 1000000;
COMMIT;
Es gibt 4 Spalten, die im Test verwendet werden müssen, und jeder Zweck ist wie folgt.
| Spaltenname | Zweck |
| ICH WÜRDE | Ein Wert zum Identifizieren jeder Zeile in der Tabelle |
| Nachricht | ein Wert, der eine Beschreibung bereitstellt |
| WERT | Zufallswert bei Testausführung aktualisiert |
| AUDID | Ein Wert, um zu prüfen, in wie vielen Sitzungen der Test ausgeführt wird. Es wird mit SYS_CONTEXT('USERENV','SESSIONID') aktualisiert. |
Als Referenz ist die Umgebung, in der dieser Test durchgeführt wurde, wie folgt.
- DBMS: Oracle 11g R2 Enterprise 11.2.0.1.0 32 Bit (unter Windows 7 x64)
- Hardware: CPU i5-5200U 2,20 GHz, Speicher 8 GB, SSD 250 GB
Sehen wir uns als Nächstes einen Fall an, indem wir jede Arbeitseinheit (Chunk) aufteilen.
In Verbindung stehende Artikel:
 Beschreibung der Oracle-Zeichensatzkonvertierung Vollständiges Inhaltsverzeichnis
Beschreibung der Oracle-Zeichensatzkonvertierung Vollständiges Inhaltsverzeichnis
 Oracle-Zeichensatzkonvertierung (4): 4.Konfigurieren der Testumgebung
Oracle-Zeichensatzkonvertierung (4): 4.Konfigurieren der Testumgebung
 Oracle-Zeichensatzkonvertierung (3): 3. Konfiguration der Client-Umgebung (2)
Oracle-Zeichensatzkonvertierung (3): 3. Konfiguration der Client-Umgebung (2)
 DBMS_PARALLEL_EXECUTE Beschreibung Inhaltsverzeichnis
DBMS_PARALLEL_EXECUTE Beschreibung Inhaltsverzeichnis
 4. Fall der benutzerdefinierten SQL-partitionierten parallelen Verarbeitung (DBMS_PARALLEL_EXECUTE)
4. Fall der benutzerdefinierten SQL-partitionierten parallelen Verarbeitung (DBMS_PARALLEL_EXECUTE)
 3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
 2.5. Detailprüfung der Aufteilung der Arbeitseinheiten (DBMS_PARALLEL_EXECUTE)
2.5. Detailprüfung der Aufteilung der Arbeitseinheiten (DBMS_PARALLEL_EXECUTE)
 2. ROWID-Partitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
2. ROWID-Partitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)









