Verteilung des Data Standards Check Tools v1.35_20230321
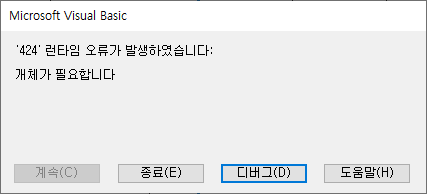
Bei Verwendung der Standardprüffunktion basierend auf dem physischen Namen ist der Laufzeitfehler „‚424‘“ aufgetreten. Es ist ein Objekt erforderlich.“ Möglicherweise enthält die Nachricht Fehler. Verteilen Sie das Datenstandard-Inspektionstool v1.35_20230321, das diesen Fehler behoben hat.
*(Referenz) Letzter Vertriebsartikel: Stellen Sie das Data Standards Check Tool v1.34_20221215 bereit
1. Phänomen
Wenn Sie im Blatt „Standardprüfung (Physikalischer Name)“ in Spalte C (Spaltenname (physischer Name)) einen Spaltennamen eingeben und auf die Schaltfläche „Standardprüfung“ klicken, ist der folgende „Laufzeitfehler ‚424‘“ aufgetreten. Es ist ein Objekt erforderlich.“ Es ist ein Fehler aufgetreten.
2. Ursache
Dieser Fehler tritt nicht immer auf, sondern tritt auf, wenn jedes Token nicht im physischen Namen des Wortwörterbuchs vorhanden ist, wenn der physische Name durch ein Trennzeichen (_, Unterstrich) geteilt wird.
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx)) '<-- 오류 발생
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sLName = sLName + IIf(sLName = "", "", "_") + oStdWord.m_s단어논리명
End If
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
In Zeile 15 des obigen Codes bedeutet aColNamePart(lColNamePartIdx) den n-ten Wert von Token geteilt durch den Unterstrich. Ein Fehler tritt auf, wenn dieser Wert in ItemP (einem Wörterbuchobjekt, das physische Namen als Schlüssel und Wortobjekte als Werte verwaltet) von oStdWordDic (Wortwörterbuchobjekt) nicht vorhanden ist.
3. Maßnahmen
Ich habe den Code wie folgt geändert.
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
Dim sTokenP As String, sTokenL As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
sTokenP = aColNamePart(lColNamePartIdx)
sTokenL = ""
If oStdWordDic.ExistsP(sTokenP) Then '단어 물리명이 사전에 있는 경우
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx))
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sTokenL = oStdWord.m_s단어논리명
End If
Else
'단어 물리명이 사전에 없는 경우
sTokenL = "[" + sTokenP + "]"
End If
sLName = sLName + IIf(sLName = "", "", "_") + sTokenL
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
Wenn das Wort physischer Name im Wörterbuch enthalten ist (Zeile 18) und wenn nicht (Zeile 25), liegt kein Fehler vor, und wenn es nicht im Wörterbuch enthalten ist, „[…] ]“-Formular hinzugefügt und durch bedingte Formatierung hervorgehoben.
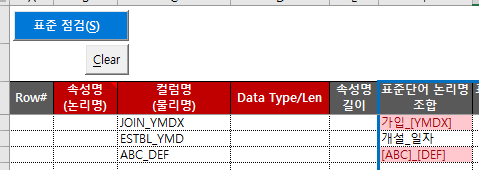
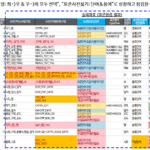
Wenn der physische Name eines Wortes nicht im Wörterbuch vorhanden ist, wird er wie im folgenden Beispiel angezeigt. Dies ist ein Beispiel für die absichtliche Eingabe von YMDX, ABC und DEF, die nicht im Wörterbuch enthalten sind.
4. Laden Sie das Data Standard Check Tool v1.35_20230321 herunter
Die Patch-Version wurde auf Github hochgeladen und kann von der untenstehenden URL heruntergeladen werden.
In Verbindung stehende Artikel:
 Stellen Sie das Data Standards Check Tool v1.34_20221215 bereit
Stellen Sie das Data Standards Check Tool v1.34_20221215 bereit
 Data Standard Check Tool Beschreibung Inhalt , Download
Data Standard Check Tool Beschreibung Inhalt , Download
 Datenstandard-Prüftool_4.Anhang
Datenstandard-Prüftool_4.Anhang
 Data Standard Check Tool_3. Ergebnisse der Standardprüfung
Data Standard Check Tool_3. Ergebnisse der Standardprüfung
 Datenstandard-Überprüfungstool_2.3 Konfiguration des Datenstandard-Wörterbuchs
Datenstandard-Überprüfungstool_2.3 Konfiguration des Datenstandard-Wörterbuchs
 Data Standard Check Tool_1.Übersicht
Data Standard Check Tool_1.Übersicht
 DA#-Makro(2): DA#-Makrofunktion(1) – Gemeinsame Funktion, Entity Get/Set
DA#-Makro(2): DA#-Makrofunktion(1) – Gemeinsame Funktion, Entity Get/Set
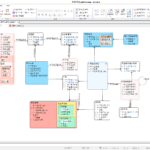 DA#-Makro(1): DA#, DA#-API, DA#-Makroübersicht
DA#-Makro(1): DA#, DA#-API, DA#-Makroübersicht










Standardwörterbuchabfrage für Standardwörterbuch-Repository-bezogene Konfiguration.
Repository-Datenbank: PostgreSQL, standardisierte Datenbank: SQL Server
– Standardwortwörterbuch abfragen
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS „Wortlogikname“
,D.DIC_PHY_NM AS „physischer Wortname“
,D.DIC_PHY_FLL_NM AS „Englischer Wortname“
,D.DIC_DESC AS „Wortbeschreibung“
,D.STANDARD_YN ALS „Standard“
,(Fall D.ATTR_CLSS_YN, wenn 'Y', dann 'Y', sonst 'N' END) AS „ob Attributklassifikator vorhanden ist“
,FALL
WENN D.STANDARD_YN = 'Y' UND SIM.Standard-Logikname NULL IST, DANN D.DIC_LOG_NM
WENN D.STANDARD_YN = 'Y' UND SIM.standard-Logikname NICHT NULL IST, DANN SIM.standard-Logikname
ELSE SIM. Standardlogikname
END „Standard-Logikname“
,SIM. Synonym
,G.DOM_GRP_NM AS „Domänenklassifizierungsname“
/*
,D.ENT_CLSS_YN AS „Entitätsklassifikator
*/
VON dataware.STD_AREA A
,dataware.STD_DIC D
Linke äußere Verbindung
(SELECT DM.KEY_DOM_NM
,MAX(DM.DOM_GRP_ID) DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
VON dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
WHERE DM.STD_AREA_ID = 'Schlüsselwert muss überprüft werden!!!'
AND DM.AVAL_END_DT = '99991231235959'
UND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
UND DM.DOM_GRP_ID = DG.DOM_GRP_ID
GRUPPE NACH DM.KEY_DOM_NM) G
auf D.DIC_LOG_NM = G.KEY_DOM_NM
Linke äußere Verbindung
(
— wenn Standard
SELECT A.P_DIC_ID „Gruppen-ID“
,A.P_DIC_ID DIC_ID
,P.DIC_LOG_NM „Standard-Logikname“
,STRING_AGG(C.DIC_LOG_NM, ',' ORDER BY A.C_DIC_ID) „Synonym“
VON dataware.STD_DIC_REL A
Linker äußerer Join dataware.STD_DIC P
auf A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = '99991231235959'
Linker äußerer Join dataware.STD_DIC C
auf A.C_DIC_ID = C.DIC_ID und C.AVAL_END_DT = '99991231235959'
WO 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Standard Dictionary')
AND A.AVAL_END_DT = '99991231235959'
GRUPPE NACH A.P_DIC_ID, P.DIC_LOG_NM
UNION ALLE
– wenn nicht standardisiert
SELECT AA.P_DIC_ID „Gruppen-ID“
,A.C_DIC_ID DIC_ID
,P.DIC_LOG_NM „Standard-Logikname“
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ',' ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN '0' ELSE AA.C_DIC_ID END) „Synonym“
VON dataware.STD_DIC_REL A
,dataware.STD_DIC_REL AA
,dataware.STD_DIC P
,dataware.STD_DIC C
WO 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Standard Dictionary')
AND A.AVAL_END_DT = '99991231235959'
UND A.P_DIC_ID = AA.P_DIC_ID
UND AA.P_DIC_ID = P.DIC_ID
AND P.AVAL_END_DT = '99991231235959'
UND AA.C_DIC_ID = C.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
GROUP BY AA.P_DIC_ID, A.C_DIC_ID, P.DIC_LOG_NM
) SIM
auf D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = 'Standardwörterbuch'
UND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0001' /* '0001': Wort */
/* AND D.STANDARD_YN = 'Y' extrahiert nur Standardwörter */
ORDER BY D.DIC_LOG_NM, (Fall D.STANDARD_YN, wenn 'Y', dann 1, sonst 2 Ende)
;
– Standardbegriffswörterbuch abfragen
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS „Begriffslogikname“
,
(
SELECT STRING_AGG(X.DIC_LOG_NM, '_')
AUS
(
SELECT WRD.DIC_LOG_NM
VON STD_DIC ALS WRD
LEFT OUTER JOIN STD_WORD_COMBI AS C
ON WRD.STD_AREA_ID = C.STD_AREA_ID
UND WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Standard Dictionary')
UND C.TERM_ID = D.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
ORDER BY C.ORDER_NO
) AS X
) AS „Wortlogische Namenskombination“
,D.DIC_PHY_NM AS „Physischer Name des Begriffs“
,D.DIC_DESC AS „Glossar“
,DM.DOM_NM AS „Logischer Domänenname“
,UPPER(DT.DATA_TYPE) AS „Datentyp“
— ,DM.DATA_LEN AS „Länge“
,(Fall wenn DM.DATA_LEN = -1, dann 'MAX' sonst text(DM.DATA_LEN) END) AS „Länge“
,DM.DATA_SCALE AS „Grad“
, als „Aufgabendefinition“
,UPPER(DT.DATA_TYPE)
||Fall
wenn DM.DATA_LEN null ist und UPPER(DT.DATA_TYPE) nicht in ('INT', 'DATETIME2') ist, dann null
wenn DM.DATA_LEN null ist und UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') dann „
WENN DM.DATA_LEN = -1 UND DM.DATA_SCALE NULL und UPPER(DT.DATA_TYPE) in ('VARCHAR', 'VARBINARY') IST, DANN '(MAX'
sonst '('||DM.DATA_LEN
Ende
||FALL, WENN DM.DATA_LEN NICHT NULL IST UND DM.DATA_SCALE NULL IST, DANN ')'
WENN DM.DATA_LEN NICHT NULL IST und DM.DATA_LEN > 0 UND DM.DATA_SCALE NICHT NULL IST, DANN ','||DM.DATA_SCALE||')'
WENN DM.DATA_LEN NULL IST UND DM.DATA_SCALE NULL IST und UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') DANN ”
ELSE NULL Ende
AS „TypeSize“
VON dataware.STD_AREA A
,dataware.STD_DIC D
,dataware.STD_DOM DM
,dataware.STD_DATATYPE DT
WHERE A.STD_AREA_NM = 'Standardwörterbuch'
UND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0002' /* '0002': term */
AND D.STANDARD_YN = 'Y' /* Nur Standardbegriffe extrahieren */
UND DM.STD_AREA_ID = D.STD_AREA_ID
AND DM.AVAL_END_DT = '99991231235959'
UND DM.DOM_ID = D.DOM_ID
AND DT.DB_TYPE = '0006' –SQL SERVER
UND DT.CD_NO = DM.DATA_TYPE_CD
;
–Standardabfrage des Domänenwörterbuchs
SELECT ROW_NUMBER() OVER (ORDER BY DG.DOM_GRP_NM, DM.DOM_NM) AS NO
,DG.DOM_GRP_NM AS „Domänenklassifizierungsname“
,DM.DOM_NM AS „Logischer Domänenname“
,DM.KEY_DOM_PHY_NM AS „Physischer Schlüsseldomänenname“
,(Fall DM.DOM_DESC, wenn null, dann DM.KEY_DOM_NM, sonst DM.DOM_DESC END) AS „Domänenbeschreibung“
,UPPER(DT.DATA_TYPE) AS „Datentypname“
,(Fall wenn DM.DATA_LEN = -1, dann 'MAX' sonst text(DM.DATA_LEN) END) AS „Länge“
,DM.DATA_SCALE AS „Grad“
,UPPER(DT.DATA_TYPE)
||Fall
wenn DM.DATA_LEN null ist und UPPER(DT.DATA_TYPE) nicht in ('INT', 'DATETIME2') ist, dann null
wenn DM.DATA_LEN null ist und UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') dann „
WENN DM.DATA_LEN = -1 UND DM.DATA_SCALE NULL und UPPER(DT.DATA_TYPE) in ('VARCHAR', 'VARBINARY') IST, DANN '(MAX'
sonst '('||DM.DATA_LEN
Ende
||FALL, WENN DM.DATA_LEN NICHT NULL IST UND DM.DATA_SCALE NULL IST, DANN ')'
WENN DM.DATA_LEN NICHT NULL IST und DM.DATA_LEN > 0 UND DM.DATA_SCALE NICHT NULL IST, DANN ','||DM.DATA_SCALE||')'
WENN DM.DATA_LEN NULL IST UND DM.DATA_SCALE NULL IST und UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') DANN ”
ELSE NULL Ende
AS „TypeSize“
/*
,DM.KEY_DOM_NM AS „Schlüsseldomänenname“
*/
VON dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
,dataware.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = 'Standard Dictionary')
AND DM.AVAL_END_DT = '99991231235959'
UND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
UND DG.DOM_GRP_ID = DM.DOM_GRP_ID
AND DT.DB_TYPE = '0006'
UND DT.CD_NO = DM.DATA_TYPE_CD
;
Vielen Dank, dass Sie das Standard-Wörterbuch-Lookup-SQL geteilt haben.
Ich werde es auch verwenden, wenn ich die PostgreSQL-Version verwende.
Einrückungen durch Leerzeichen werden in Kommentaren nicht angezeigt.
Lasst uns einen Weg finden.
Wenn bei der Überprüfung des Standards der Eigenschaftsname (KUNDENNUMMER) nur mit englischen Wörtern kombiniert wird, besteht das Symptom, dass die Standardwortkombination und die Standard-Englisch-Übereinstimmung nicht überprüft werden können, selbst wenn der Standardbegriff registriert ist. Ich frage mich, ob es etwas mit der Logik zu tun hat, die Trennzeichen als Unterstriche und Leerzeichen behandelt?
EX)
*Standardwörter, Abkürzungen
KUNDEN, KUNDEN
NUMMER, NR
*Standardbegriff, Domain
KUNDENNUMMER, NUMMER V10
*Standarddomäne, Datentyp
NUMMER V10, VARCHAR(10)
https://prodskill.com/ko/data-standard-checker-4-case-study/#33_%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80_%EC%98%88%EC%8B%9C_Case_2_%ED%91%9C%EC%A4%80%EB%8B%A8%EC%96%B4_%EC%A1%B0%ED%95%A9
Dieser Artikel enthält Folgendes:
—————————————————————
Das Attribut „ob es sich um ein privates Objekt handelt“ (Row# 9) enthält ein Leerzeichen. Im Element „Standardwort-Logiknamenkombination“ wird „[persönliches Ziel]_ob“ angezeigt, was bedeutet, dass „[persönliches Ziel]“ nicht im Standardwortwörterbuch vorhanden ist und „ob“ im Standardwortwörterbuch vorhanden ist. Diese Zelle enthält auch nicht registrierte Zeichen, daher ist die Hintergrundfarbe auf Rot eingestellt. Wenn im Eigenschaftsnamen ein Trennzeichen enthalten ist, wird es im Element „Ergebnis der Eigenschaftsnamenprüfung“ als „(Benutzerbezeichnung)“ angezeigt.
—————————————————————
Leerzeichen in den prüfpflichtigen Eigenschaftsnamen werden bewusst zur Trennung von Wörtern verwendet.
Wenn bei der aktuell implementierten Funktion Leerzeichen im logischen Namen des Standardbegriffs zulässig sind, erfolgt keine Übereinstimmungsprüfung anhand des Standardbegriffs.
Es scheint, dass die gewünschte Überprüfung durchgeführt werden kann, indem eine Option erstellt wird, mit der ausgewählt werden kann, ob die im zu überprüfenden Eigenschaftsnamen eingegebenen Leerzeichen als „absichtliche Worttrennzeichen“ oder als „Leerzeichen“ selbst behandelt werden sollen.
brauchst du es ^^
Bei der Modellierung auf Englisch ist es schwierig, Wörter zu identifizieren, wenn der Eigenschaftsname wie ein koreanisches Wort angehängt wird. Wenn Sie also englische Wörter durch ein Leerzeichen trennen müssen, benötigen Sie eine Option. ^^;;
https://github.com/DAToolset/ToolsForDataStandard/raw/main/%EC%86%8D%EC%84%B1%20%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80%20%EB%8F%84%EA%B5%AC_v1.36_20230426_1.xlsm
In Version 1.36 wurde es dahingehend geändert, dass Leerzeichen in Eigenschaftsnamen, die einer Standardprüfung unterliegen, nicht als Worttrennzeichen behandelt werden.
Dementsprechend wurden die Regeln zur Erstellung des zu prüfenden Eigenschaftsnamens wie folgt geändert.
※ Regeln für die Erstellung von Attributnamen
1. Geben Sie ohne Leerzeichen zwischen Wörtern ein: Standard
– Beispiel: Ob die Aufgabe automatisch ausgeführt werden soll oder nicht
2. Leerzeichen zwischen Wörtern eingeben: Beim Schreiben des Eigenschaftslogiknamens auf Englisch
– Beispiel: KUNDENNUMMER
3. Geben Sie getrennt durch „_“ ein: Bei der Angabe einer Wortstruktur
– Beispiel: ob der job_automatically_executed_oder nicht
Bitte testen Sie es und kommentieren Sie es.
Eigenschaftsname: CUSTOMER SPLIT NUMBER
Bei der Standardinspektion wird das Ergebnis der Eigenschaftsnameninspektion als Standardwortkombination angezeigt, aber die Ergebnisse der Standardwortkombination aus logischem Namen und physischer Namenskombination werden falsch verarbeitet.
KUNDE, SPLIT, NUMMER: 3 Standardwörter registriert
Standardwortkombination für logische Namen: CUSTOMER_[ ]_SPLIT_[ ]_NUMBER
Standardkombination für physische Wortnamen: CUST_[ ]_SPLT_[ ]_NO
Ich habe es so einfach gesehen ^^;;
Ich werde noch ein paar Tests durchführen und es erneut bereitstellen.
v1.36 Neu bereitgestellt.
https://prodskill.com/ko/data-standard-checker-v1-36/
Repository-Datenbank: PostgreSQL, Standardisierungsziel-Datenbank: PostgreSQL
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS „Wortlogikname“
,D.DIC_PHY_NM AS „physischer Wortname“
,D.DIC_PHY_FLL_NM AS „Englischer Wortname“
,D.DIC_DESC AS „Wortbeschreibung“
,D.STANDARD_YN ALS „Standard“
,(Fall D.ATTR_CLSS_YN, wenn 'Y', dann 'Y', sonst 'N' END) AS „ob Attributklassifikator vorhanden ist“
,FALL
WENN D.STANDARD_YN = 'Y' UND SIM.Standard-Logikname NULL IST, DANN D.DIC_LOG_NM
WENN D.STANDARD_YN = 'Y' UND SIM.standard-Logikname NICHT NULL IST, DANN SIM.standard-Logikname
ELSE SIM. Standardlogikname
END „Standard-Logikname“
,SIM. Synonym
,G.KEY_DOM_NM AS „Domänenklassifizierungsname“
/*
,D.ENT_CLSS_YN AS „Entitätsklassifikator
*/
VON dataware.STD_AREA A
,dataware.STD_DIC D
Linke äußere Verbindung
(SELECT DM.KEY_DOM_NM
,MAX(DM.DOM_GRP_ID) DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
VON dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
WHERE DM.STD_AREA_ID = '47430eed-15a9-4697-90e3-a70040266517'
AND DM.AVAL_END_DT = '99991231235959'
UND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
UND DM.DOM_GRP_ID = DG.DOM_GRP_ID
GRUPPE NACH DM.KEY_DOM_NM) G
auf D.DIC_LOG_NM = G.KEY_DOM_NM
Linke äußere Verbindung
(
–Wenn Standard
SELECT A.P_DIC_ID „Gruppen-ID“
,A.P_DIC_ID DIC_ID
,P.DIC_LOG_NM „Standard-Logikname“
,STRING_AGG(C.DIC_LOG_NM, ',' ORDER BY A.C_DIC_ID) „Synonym“
VON dataware.STD_DIC_REL A
Linker äußerer Join dataware.STD_DIC P
auf A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = '99991231235959'
Linker äußerer Join dataware.STD_DIC C
auf A.C_DIC_ID = C.DIC_ID und C.AVAL_END_DT = '99991231235959'
WO 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Standard Dictionary')
AND A.AVAL_END_DT = '99991231235959'
GRUPPE NACH A.P_DIC_ID, P.DIC_LOG_NM
UNION ALLE
–Im Falle von Nicht-Standard
SELECT AA.P_DIC_ID „Gruppen-ID“
,A.C_DIC_ID DIC_ID
,P.DIC_LOG_NM „Standard-Logikname“
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ',' ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN '0' ELSE AA.C_DIC_ID END) „Synonym“
VON dataware.STD_DIC_REL A
,dataware.STD_DIC_REL AA
,dataware.STD_DIC P
,dataware.STD_DIC C
WO 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Standard Dictionary')
AND A.AVAL_END_DT = '99991231235959'
UND A.P_DIC_ID = AA.P_DIC_ID
UND AA.P_DIC_ID = P.DIC_ID
AND P.AVAL_END_DT = '99991231235959'
UND AA.C_DIC_ID = C.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
GROUP BY AA.P_DIC_ID, A.C_DIC_ID, P.DIC_LOG_NM
) SIM
auf D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = '0.Standardwörterbuch'
UND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0001' /* '0001': Wort */
/* AND D.STANDARD_YN = 'Y' extrahiert nur Standardwörter */
ORDER BY D.DIC_LOG_NM, (Fall D.STANDARD_YN, wenn 'Y', dann 1, sonst 2 Ende)
;
– Standardbegriffswörterbuch abfragen
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
,D.DIC_LOG_NM AS „Begriffslogikname“
,
(
SELECT STRING_AGG(X.DIC_LOG_NM, '_')
AUS
(
SELECT WRD.DIC_LOG_NM
VON STD_DIC ALS WRD
LEFT OUTER JOIN STD_WORD_COMBI AS C
ON WRD.STD_AREA_ID = C.STD_AREA_ID
UND WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Standard Dictionary')
UND C.TERM_ID = D.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
AND WRD.AVAL_END_DT = '99991231235959'
ORDER BY C.ORDER_NO
) AS X
) AS „Wortlogische Namenskombination“
,D.DIC_PHY_NM AS „Physischer Name des Begriffs“
,D.DIC_DESC AS „Glossar“
,DM.DOM_NM AS „Logischer Domänenname“
,UPPER(DT.DATA_TYPE) AS „Datentyp“
— ,DM.DATA_LEN AS „Länge“
,(Fall wenn DM.DATA_LEN = -1, dann 'MAX' sonst text(DM.DATA_LEN) END) AS „Länge“
,DM.DATA_SCALE AS „Grad“
, als „Aufgabendefinition“
, ersetzen(
UPPER(DT.DATA_TYPE)
||'(''
|| Wenn DM.DATA_LEN null ist, dann endet „sonst cast(DM.DATA_LEN als Text)“.
|| Fall, wenn DM.DATA_SCALE null ist, dann „sonst cast(DM.DATA_SCALE als Text) Ende.“
||')'’
, '()', ) AS „TypeSize“
VON dataware.STD_AREA A
,dataware.STD_DIC D
,dataware.STD_DOM DM
,dataware.STD_DATATYPE DT
WHERE A.STD_AREA_NM = '0.Standardwörterbuch'
UND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0002' /* '0002': term */
AND D.STANDARD_YN = 'Y' /* Nur Standardbegriffe extrahieren */
UND DM.STD_AREA_ID = D.STD_AREA_ID
AND DM.AVAL_END_DT = '99991231235959'
UND DM.DOM_ID = D.DOM_ID
AND DT.DB_TYPE = '0024'
UND DT.CD_NO = DM.DATA_TYPE_CD
;
–Standardabfrage des Domänenwörterbuchs
SELECT ROW_NUMBER() OVER (ORDER BY DG.DOM_GRP_NM, DM.DOM_NM) AS NO
,DM.key_dom_nm AS „Domänenklassifizierungsname“
,DM.DOM_NM AS „Logischer Domänenname“
,DM.KEY_DOM_PHY_NM AS „Physischer Schlüsseldomänenname“
,(Fall DM.DOM_DESC, wenn null, dann DM.KEY_DOM_NM, sonst DM.DOM_DESC END) AS „Domänenbeschreibung“
,UPPER(DT.DATA_TYPE) AS „Datentypname“
,DM.DATA_LEN AS „Länge“
,DM.DATA_SCALE AS „Grad“
, ersetzen(
UPPER(DT.DATA_TYPE)
||'(''
|| Wenn DM.DATA_LEN null ist, dann endet „sonst cast(DM.DATA_LEN als Text)“.
|| Fall, wenn DM.DATA_SCALE null ist, dann „sonst cast(DM.DATA_SCALE als Text) Ende.“
||')'’
, '()', ) AS „TypeSize“
, dg.dom_grp_nm als „Standarddomänengruppenname“
/*
,DM.KEY_DOM_NM AS „Schlüsseldomänenname“
*/
VON dataware.STD_DOM DM
,dataware.STD_DOM_GRP DG
,dataware.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.Standard Dictionary')
AND DM.AVAL_END_DT = '99991231235959'
UND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
UND DG.DOM_GRP_ID = DM.DOM_GRP_ID
AND DT.DB_TYPE = '0024'
UND DT.CD_NO = DM.DATA_TYPE_CD
;
Danke fürs Teilen.