データ標準チェックツールv1.35_20230321展開
物理名基準の標準チェック機能を使用すると、「424」ランタイムエラーが発生しました。オブジェクトが必要です。メッセージのエラーが発生することがあります。このエラーを修正したデータ標準チェックツールv1.35_20230321を展開します。
*(参考)前回の配布記事: データ標準チェックツールv1.34_20221215展開
1.現象
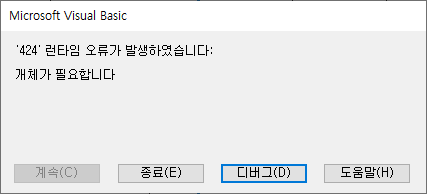
「標準チェック(物理名基準)」シートのC列(カラム名(物理名))にカラム名を入力し、標準チェックボタンをクリックすると、次の「424」ランタイムエラーが発生しました。オブジェクトが必要です。エラーが発生します。
2.原因
このエラーは常に発生するわけではなく、物理名を区切り文字(_、underscore)で割ったときに各トークンが単語辞書の物理名にない場合に発生します。
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx)) '<-- 오류 발생
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sLName = sLName + IIf(sLName = "", "", "_") + oStdWord.m_s단어논리명
End If
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
上記の15行目のaColNamePart(lColNamePartIdx)は、underscore文字に分割されたtokenのn番目の値を意味します。この値がoStdWordDic(単語辞書辞書オブジェクト)のItemP(物理名をキーに、単語オブジェクトを値として管理する辞書オブジェクト)に存在しないときにエラーが発生します。
3. アクション内容
次のようにコードを変更しました。
Private Sub cmdRun_Click()
...
'------------------------------------------------------------------------------------------
'물리명 기준으로 논리명 찾기
Dim aColNamePart() As String, lColNamePartIdx As Long, oColNamePartAsStdWord As Collection
Dim oStdWordObj As Object, oStdWord As CStdWord, sLName As String
Dim sTokenP As String, sTokenL As String
For lRow = LBound(vInRngArr) To UBound(vInRngArr)
sColName = vInRngArr(lRow, 1)
If Trim(sColName) = "" Then GoTo SkipBlank '점검할 속성명이 비어있는 경우 Skip
aColNamePart = Split(sColName, "_")
Set oColNamePartAsStdWord = Nothing
Set oColNamePartAsStdWord = New Collection
sLName = ""
For lColNamePartIdx = LBound(aColNamePart) To UBound(aColNamePart)
sTokenP = aColNamePart(lColNamePartIdx)
sTokenL = ""
If oStdWordDic.ExistsP(sTokenP) Then '단어 물리명이 사전에 있는 경우
Set oStdWordObj = oStdWordDic.ItemP(aColNamePart(lColNamePartIdx))
oColNamePartAsStdWord.Add oStdWordObj
If TypeOf oStdWordObj Is CStdWord Then
Set oStdWord = oStdWordObj
sTokenL = oStdWord.m_s단어논리명
End If
Else
'단어 물리명이 사전에 없는 경우
sTokenL = "[" + sTokenP + "]"
End If
sLName = sLName + IIf(sLName = "", "", "_") + sTokenL
oOutRange.Offset(lRow - 1, 0).Value2 = sLName
Next lColNamePartIdx
SkipBlank:
Next lRow
...
End Sub
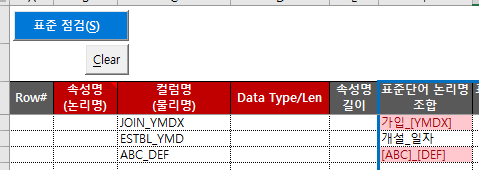
単語物理名が辞書にある場合(18行)とない場合(25行)を区別してエラーがないようにし、辞書にない場合「[… ]」の形に変形し、条件付き書式によって目立つようにした。
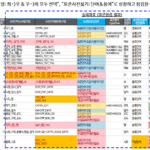
単語物理名が辞書にない場合は、次の例のように表示されます。わざわざ単語辞書にないYMDX、ABC、DEFを入力した例だ。
4. データ標準チェックツール v1.35_20230321 ダウンロード
パッチバージョンをgithubにアップロードし、以下のURLからダウンロードできます。
https://github.com/DAToolset/ToolsForDataStandard/raw/main/속성%20표준점검%20도구_v1.35_20230321_1.xlsm


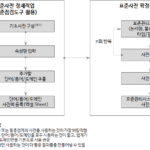
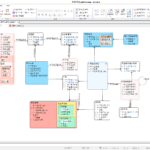










標準辞書Repository関連のConfigへの標準辞書クエリです。
Repository DB: PostgreSQL、標準化対象 DB: SQL Server
–標準単語辞書 Query
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
、D.DIC_LOG_NM AS「単語論理名」
、D.DIC_PHY_NM AS「単語物理名」
、D.DIC_PHY_FLL_NM AS「単語英語名」
、D.DIC_DESC AS「単語の説明」
、D.STANDARD_YN AS「標準かどうか」
,(case D.ATTR_CLSS_YN when 'Y' then 'Y' else 'N' END) AS “属性分類語かどうか”
,CASE
WHEN D.STANDARD_YN = 'Y' AND SIM.標準論理名IS NULL THEN D.DIC_LOG_NM
WHEN D.STANDARD_YN = 'Y' AND SIM.標準論理名 IS NOT NULL THEN SIM.標準論理名
ELSE SIM。標準論理名
END「標準論理名」
、SIM。同義語
、G.DOM_GRP_NM AS「ドメイン分類名」
/*
、D.ENT_CLSS_YN AS「エンティティ分類語があるかどうか
*/
FROM dataware.STD_AREA A
、dataware.STD_DIC D
left outer join
(SELECT DM.KEY_DOM_NM
、MAX(DM.DOM_GRP_ID)DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
FROM dataware.STD_DOM DM
、dataware.STD_DOM_GRP DG
WHERE DM.STD_AREA_ID = 'キー値の確認が必要!!!'
AND DM.AVAL_END_DT = '99991231235959'
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
AND DM.DOM_GRP_ID = DG.DOM_GRP_ID
GROUP BY DM.KEY_DOM_NM) G
on D.DIC_LOG_NM = G.KEY_DOM_NM
left outer join
(
— 標準の場合
SELECT A.P_DIC_ID “グループID”
、A.P_DIC_ID DIC_ID
、P.DIC_LOG_NM「標準論理名」
,STRING_AGG(C.DIC_LOG_NM, ',' ORDER BY A.C_DIC_ID) “同義語”
FROM dataware.STD_DIC_REL A
left outer join dataware.STD_DIC P
on A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = '99991231235959'
left outer join dataware.STD_DIC C
on A.C_DIC_ID = C.DIC_ID and C.AVAL_END_DT = '99991231235959'
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '標準辞書')
AND A.AVAL_END_DT = '99991231235959'
GROUP BY A.P_DIC_ID, P.DIC_LOG_NM
UNION ALL
- 非標準の場合
SELECT AA.P_DIC_ID “グループID”
、A.C_DIC_ID DIC_ID
、P.DIC_LOG_NM「標準論理名」
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ',' ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN '0' ELSE
FROM dataware.STD_DIC_REL A
、dataware.STD_DIC_REL AA
、dataware.STD_DIC P
、dataware.STD_DIC C
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '標準辞書')
AND A.AVAL_END_DT = '99991231235959'
AND A.P_DIC_ID = AA.P_DIC_ID
AND AA.P_DIC_ID = P.DIC_ID
AND P.AVAL_END_DT = '99991231235959'
AND AA.C_DIC_ID = C.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
GROUP BY AA.P_DIC_ID、A.C_DIC_ID、P.DIC_LOG_NM
) SIM
on D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = '標準辞書'
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0001' /* '0001': 単語 */
/* AND D.STANDARD_YN = 'Y' 標準単語のみ抽出 */
ORDER BY D.DIC_LOG_NM, (case D.STANDARD_YN when 'Y' then 1 else 2 end)
;
– 標準用語辞書 Query
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
、D.DIC_LOG_NM AS「用語論理名」
,
(
SELECT STRING_AGG(X.DIC_LOG_NM, '_')
FROM
(
SELECT WRD.DIC_LOG_NM
FROM STD_DIC AS WRD
LEFT OUTER JOIN STD_WORD_COMBI AS C
ON WRD.STD_AREA_ID = C.STD_AREA_ID
AND WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '標準辞書')
AND C.TERM_ID = D.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
ORDER BY C.ORDER_NO
) AS X
)AS「単語論理名組合」
、D.DIC_PHY_NM AS「用語物理名」
、D.DIC_DESC AS「用語説明」
、DM.DOM_NM AS「ドメイン論理名」
、UPPER(DT.DATA_TYPE) AS「データタイプ」
— ,DM.DATA_LEN AS “長さ”
,(case when DM.DATA_LEN = -1 then 'MAX' else text(DM.DATA_LEN) END) AS “長さ”
、DM.DATA_SCALE AS「精度」
, ” as “業務定義の”
、UPPER(DT.DATA_TYPE)
||case
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) not in ('INT', 'DATETIME2') then null
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') then ”
WHEN DM.DATA_LEN = -1 AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in('VARCHAR', 'VARBINARY') THEN '(MAX'
else '('||DM.DATA_LEN
end
||CASE WHEN DM.DATA_LEN IS NOT NULL AND DM.DATA_SCALE IS NULL THEN ')'
WHEN DM.DATA_LEN IS NOT NULL and DM.DATA_LEN > 0 AND DM.DATA_SCALE IS NOT NULL THEN ','||DM.DATA_SCALE||')'
WHEN DM.DATA_LEN IS NULL AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') THEN ”
ELSE NULL end
AS “TypeSize”
FROM dataware.STD_AREA A
、dataware.STD_DIC D
、dataware.STD_DOM DM
、dataware.STD_DATATYPE DT
WHERE A.STD_AREA_NM = '標準辞書'
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0002' /* '0002': 用語 */
AND D.STANDARD_YN = 'Y' /* 標準用語のみ抽出 */
AND DM.STD_AREA_ID = D.STD_AREA_ID
AND DM.AVAL_END_DT = '99991231235959'
AND DM.DOM_ID = D.DOM_ID
AND DT.DB_TYPE = '0006' –SQL SERVER
AND DT.CD_NO=DM.DATA_TYPE_CD
;
–標準ドメイン辞書 Query
SELECT ROW_NUMBER() OVER (ORDER BY DG.DOM_GRP_NM, DM.DOM_NM) AS NO
、DG.DOM_GRP_NM AS「ドメイン分類名」
、DM.DOM_NM AS「ドメイン論理名」
、DM.KEY_DOM_PHY_NM AS「キードメイン物理名」
,(case DM.DOM_DESC when null then DM.KEY_DOM_NM else DM.DOM_DESC END) AS “ドメイン説明”
、UPPER(DT.DATA_TYPE) AS「データタイプ名」
,(case when DM.DATA_LEN = -1 then 'MAX' else text(DM.DATA_LEN) END) AS “長さ”
、DM.DATA_SCALE AS「精度」
、UPPER(DT.DATA_TYPE)
||case
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) not in ('INT', 'DATETIME2') then null
when DM.DATA_LEN is null and UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') then ”
WHEN DM.DATA_LEN = -1 AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in('VARCHAR', 'VARBINARY') THEN '(MAX'
else '('||DM.DATA_LEN
end
||CASE WHEN DM.DATA_LEN IS NOT NULL AND DM.DATA_SCALE IS NULL THEN ')'
WHEN DM.DATA_LEN IS NOT NULL and DM.DATA_LEN > 0 AND DM.DATA_SCALE IS NOT NULL THEN ','||DM.DATA_SCALE||')'
WHEN DM.DATA_LEN IS NULL AND DM.DATA_SCALE IS NULL and UPPER(DT.DATA_TYPE) in ('INT', 'DATETIME2') THEN ”
ELSE NULL end
AS “TypeSize”
/*
、DM.KEY_DOM_NM AS「キードメイン名」
*/
FROM dataware.STD_DOM DM
、dataware.STD_DOM_GRP DG
、dataware.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '標準辞書')
AND DM.AVAL_END_DT = '99991231235959'
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
AND DG.DOM_GRP_ID = DM.DOM_GRP_ID
AND DT.DB_TYPE = '0006'
AND DT.CD_NO=DM.DATA_TYPE_CD
;
標準事前照会SQL共有していただきありがとうございます。
私はPostgreSQLバージョンを使用するときに活用します。
コメントに空白文字のインデントが表示されません。
方法を探してみましょう。
標準点検時に属性名(CUSTOMER NUMBER)を英文でのみ組み合わせた場合、標準用語を登録しておいても標準単語の組み合わせで標準英語の一致はチェックできない症状があります。区切り文字をアンダーバー、スペースで処理するロジック?と関連がないかと思います。
EX)
*標準単語、略語
CUSTOMER、CUST
NUMBER、NO
*標準用語、ドメイン
CUSTOMER NUMBER、NUMBER V10
*標準ドメイン、データタイプ
NUMBER V10、VARCHAR(10)
https://prodskill.com/ko/data-standard-checker-4-case-study/#33_%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80_%EC%98%88%EC%8B%9C_Case_2_%ED%91%9C%EC%A4%80%EB%8B%A8%EC%96%B4_%EC%A1%B0%ED%95%A9
この記事には次の内容があります。
———————————————————————
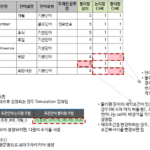
属性「個人対象かどうか」(Row# 9)にはスペースが含まれています。 「標準単語論理名の組み合わせ」項目に「[個人対象]_か否か」と表示されているのは、「[個人対象]」は標準単語辞書になく、「か否」は標準単語辞書にあるという意味である。このセルも未登録文字が含まれており、背景色が赤色に設定された。属性名に区切り文字が含まれている場合は、「属性名チェック結果」項目に「(ユーザー指定)」と表示します。
———————————————————————
標準チェック対象属性名に空白文字は意図的に単語を区切る意味で使用しています。
現在実装されている機能では、標準用語の論理名にスペースを入れることができます。
検査対象属性名に入力された空白を「意図された単語区切り文字」として扱うか、「空白文字」そのもので扱うかを選択するオプションを作成して処理すれば、必要な検査が可能になりそうです。
必要ですか? ^^
英語でモデリングする場合は、属性名をハングル単語のように貼り付けて使用すると単語識別が難しいため、英単語間を空白で区切る必要がある場合、オプションが必要になりそうです。^^;;
https://github.com/DAToolset/ToolsForDataStandard/raw/main/%EC%86%8D%EC%84%B1%20%ED%91%9C%EC%A4%80%EC%A0%90%EA%B2%80%20%EB%8F%84%EA%B5%AC_v1.36_20230426_1.xlsm
v1.36で標準チェック対象属性名の空白文字を単語区切り文字として扱わないように変更しました。
これにより、チェック対象属性名作成規則も次のように変更されました。
※属性名作成規則
1. 単語の間にスペースなしで入力: 基本
– 例: 作業自動実行の有無
2. 単語間に空白を入力: 属性論理名を英文で作成する場合
– 例: CUSTOMER NUMBER
3. 「_」で区切って入力:単語構成を指定する場合
– 例: ジョブ_自動_実行_かどうか
テストしてみてコメントありがとうございます。
属性名:CUSTOMER SPLIT NUMBER
標準チェック時の属性名チェック結果は標準単語の組み合わせで表示されるが、標準単語の論理名の組み合わせ、物理名の組み合わせ結果が誤って処理される
CUSTOMER、SPLIT、NUMBER:3つの標準単語が登録されている状態
標準単語論理名の組み合わせ:CUSTOMER_[]_SPLIT_[]_NUMBER
標準単語物理名の組み合わせ:CUST_[]_SPLT_[]_NO
とても簡単に見ました^^;;
もう少しテストしてから再配布します。
v1.36 再デプロイしました。
https://prodskill.com/ko/data-standard-checker-v1-36/
Repository DB: PostgreSQL、標準化対象DB: PostgreSQL
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
、D.DIC_LOG_NM AS「単語論理名」
、D.DIC_PHY_NM AS「単語物理名」
、D.DIC_PHY_FLL_NM AS「単語英語名」
、D.DIC_DESC AS「単語の説明」
、D.STANDARD_YN AS「標準かどうか」
,(case D.ATTR_CLSS_YN when 'Y' then 'Y' else 'N' END) AS “属性分類語かどうか”
,CASE
WHEN D.STANDARD_YN = 'Y' AND SIM.標準論理名IS NULL THEN D.DIC_LOG_NM
WHEN D.STANDARD_YN = 'Y' AND SIM.標準論理名 IS NOT NULL THEN SIM.標準論理名
ELSE SIM。標準論理名
END「標準論理名」
、SIM。同義語
、G.KEY_DOM_NM AS「ドメイン分類名」
/*
、D.ENT_CLSS_YN AS「エンティティ分類語があるかどうか
*/
FROM dataware.STD_AREA A
、dataware.STD_DIC D
left outer join
(SELECT DM.KEY_DOM_NM
、MAX(DM.DOM_GRP_ID)DOM_GRP_ID
,MAX(DG.DOM_GRP_NM) DOM_GRP_NM
FROM dataware.STD_DOM DM
、dataware.STD_DOM_GRP DG
WHERE DM.STD_AREA_ID = '47430eed-15a9-4697-90e3-a70040266517'
AND DM.AVAL_END_DT = '99991231235959'
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
AND DM.DOM_GRP_ID = DG.DOM_GRP_ID
GROUP BY DM.KEY_DOM_NM) G
on D.DIC_LOG_NM = G.KEY_DOM_NM
left outer join
(
-標準の場合
SELECT A.P_DIC_ID “グループID”
、A.P_DIC_ID DIC_ID
、P.DIC_LOG_NM「標準論理名」
,STRING_AGG(C.DIC_LOG_NM, ',' ORDER BY A.C_DIC_ID) “同義語”
FROM dataware.STD_DIC_REL A
left outer join dataware.STD_DIC P
on A.P_DIC_ID = P.DIC_ID AND P.AVAL_END_DT = '99991231235959'
left outer join dataware.STD_DIC C
on A.C_DIC_ID = C.DIC_ID and C.AVAL_END_DT = '99991231235959'
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.標準辞書')
AND A.AVAL_END_DT = '99991231235959'
GROUP BY A.P_DIC_ID, P.DIC_LOG_NM
UNION ALL
- 非標準の場合
SELECT AA.P_DIC_ID “グループID”
、A.C_DIC_ID DIC_ID
、P.DIC_LOG_NM「標準論理名」
,STRING_AGG(CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN P.DIC_LOG_NM ELSE C.DIC_LOG_NM END, ',' ORDER by CASE WHEN AA.C_DIC_ID = A.C_DIC_ID THEN '0' ELSE
FROM dataware.STD_DIC_REL A
、dataware.STD_DIC_REL AA
、dataware.STD_DIC P
、dataware.STD_DIC C
WHERE 1=1
AND A.P_STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.標準辞書')
AND A.AVAL_END_DT = '99991231235959'
AND A.P_DIC_ID = AA.P_DIC_ID
AND AA.P_DIC_ID = P.DIC_ID
AND P.AVAL_END_DT = '99991231235959'
AND AA.C_DIC_ID = C.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
GROUP BY AA.P_DIC_ID、A.C_DIC_ID、P.DIC_LOG_NM
) SIM
on D.DIC_ID = SIM.DIC_ID
WHERE A.STD_AREA_NM = '0.標準辞書'
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0001' /* '0001': 単語 */
/* AND D.STANDARD_YN = 'Y' 標準単語のみ抽出 */
ORDER BY D.DIC_LOG_NM, (case D.STANDARD_YN when 'Y' then 1 else 2 end)
;
– 標準用語辞書 Query
SELECT ROW_NUMBER() OVER (ORDER BY D.DIC_LOG_NM) AS NO
、D.DIC_LOG_NM AS「用語論理名」
,
(
SELECT STRING_AGG(X.DIC_LOG_NM, '_')
FROM
(
SELECT WRD.DIC_LOG_NM
FROM STD_DIC AS WRD
LEFT OUTER JOIN STD_WORD_COMBI AS C
ON WRD.STD_AREA_ID = C.STD_AREA_ID
AND WRD.DIC_ID = C.WORD_ID
WHERE C.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.標準辞書')
AND C.TERM_ID = D.DIC_ID
AND C.AVAL_END_DT = '99991231235959'
AND WRD.AVAL_END_DT = '99991231235959'
ORDER BY C.ORDER_NO
) AS X
)AS「単語論理名組合」
、D.DIC_PHY_NM AS「用語物理名」
、D.DIC_DESC AS「用語説明」
、DM.DOM_NM AS「ドメイン論理名」
、UPPER(DT.DATA_TYPE) AS「データタイプ」
— ,DM.DATA_LEN AS “長さ”
,(case when DM.DATA_LEN = -1 then 'MAX' else text(DM.DATA_LEN) END) AS “長さ”
、DM.DATA_SCALE AS「精度」
, ” as “業務定義の”
、replace(
UPPER(DT.DATA_TYPE)
||'(''
|| case when DM.DATA_LEN is null then ” else cast(DM.DATA_LEN as text) end
|| case when DM.DATA_SCALE is null then ” else cast(DM.DATA_SCALE as text) end
||')'’
, '()', ”) AS “TypeSize”
FROM dataware.STD_AREA A
、dataware.STD_DIC D
、dataware.STD_DOM DM
、dataware.STD_DATATYPE DT
WHERE A.STD_AREA_NM = '0.標準辞書'
AND A.STD_AREA_ID = D.STD_AREA_ID
AND D.AVAL_END_DT = '99991231235959'
AND D.DIC_GBN_CD = '0002' /* '0002': 用語 */
AND D.STANDARD_YN = 'Y' /* 標準用語のみ抽出 */
AND DM.STD_AREA_ID = D.STD_AREA_ID
AND DM.AVAL_END_DT = '99991231235959'
AND DM.DOM_ID = D.DOM_ID
AND DT.DB_TYPE = '0024'
AND DT.CD_NO=DM.DATA_TYPE_CD
;
–標準ドメイン辞書 Query
SELECT ROW_NUMBER() OVER (ORDER BY DG.DOM_GRP_NM, DM.DOM_NM) AS NO
、DM.key_dom_nm AS「ドメイン分類名」
、DM.DOM_NM AS「ドメイン論理名」
、DM.KEY_DOM_PHY_NM AS「キードメイン物理名」
,(case DM.DOM_DESC when null then DM.KEY_DOM_NM else DM.DOM_DESC END) AS “ドメイン説明”
、UPPER(DT.DATA_TYPE) AS「データタイプ名」
、DM.DATA_LEN AS「長さ」
、DM.DATA_SCALE AS「精度」
、replace(
UPPER(DT.DATA_TYPE)
||'(''
|| case when DM.DATA_LEN is null then ” else cast(DM.DATA_LEN as text) end
|| case when DM.DATA_SCALE is null then ” else cast(DM.DATA_SCALE as text) end
||')'’
, '()', ”) AS “TypeSize”
、dg.dom_grp_nm as「標準ドメイングループ名」
/*
、DM.KEY_DOM_NM AS「キードメイン名」
*/
FROM dataware.STD_DOM DM
、dataware.STD_DOM_GRP DG
、dataware.STD_DATATYPE DT
WHERE DM.STD_AREA_ID = (SELECT STD_AREA_ID FROM DATAWARE.STD_AREA WHERE AVAL_END_DT = '99991231235959' AND STD_AREA_NM = '0.標準辞書')
AND DM.AVAL_END_DT = '99991231235959'
AND DG.STD_AREA_ID = DM.STD_AREA_ID
AND DG.AVAL_END_DT = '99991231235959'
AND DG.DOM_GRP_ID = DM.DOM_GRP_ID
AND DT.DB_TYPE = '0024'
AND DT.CD_NO=DM.DATA_TYPE_CD
;
共有していただきありがとうございます。