Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
Examine el código fuente de una herramienta de extracción de palabras implementada en Python.
Esta es una continuación del artículo anterior.
4. Código fuente de la herramienta de extracción de Word
4.1. describir
4.1.1. pon el codigo fuente
El código fuente de esta herramienta de extracción de palabras es casi el primer código que he escrito entre herramientas útiles hechas en Python. Dado que solo se enfoca en implementar funciones necesarias cuando aún no es familiar, está lejos de ser conciso, que es la ventaja de Python. Es más como el estilo C que el estilo Python.
Estaba pensando en escribir los resultados de extracción de texto y los resultados de extracción de palabras en clases separadas, pero intenté usar DataFrame de pandas como prueba y funcionó mejor de lo que pensaba, así que simplemente usé DataFrame. Como beneficio adicional, el tiempo de implementación se redujo considerablemente al usar las funciones groupby y to_excel proporcionadas por DataFrame.
“2.1.2. Elige un despalillador: MecabComo se menciona en “, se utilizó el lematizador de lenguaje natural Mecab para la extracción de palabras. Para usar otros analizadores de morfemas, modifique la función get_word_list.
El número de línea del código insertado en el texto se configura para que sea el mismo que el número de línea del código fuente cargado en github, y todos los comentarios se incluyen sin excluir comentarios tanto como sea posible.
4.1.2 Relación de llamada de función de la herramienta de extracción de palabras
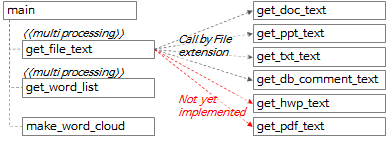
La relación general de llamadas de funciones se puede resumir como el diagrama anterior y el contenido a continuación.
- En la función principal, se llama a la función get_file_text para extraer texto en unidades de línea y unidades de párrafo de cada archivo.
- Dentro de la función get_file_text, llame a las funciones get_doc_text, get_ppt_text, get_txt_text y get_db_comment_text según la extensión del archivo.
- Las funciones get_hwp_text y get_pdf_text aún no se han implementado y se implementarán más adelante cuando sea necesario. (Si tiene experiencia implementándolo o conoce el código implementado, deje un comentario).
- El resultado de la ejecución de la función get_file_text se transfiere a la función get_word_list para extraer palabras candidatas.
- Las funciones get_file_text y get_word_list son multiprocesamiento.
- Llame a la función make_word_cloud para crear una imagen de nube de palabras.
4.2. función principal
4.2.1. análisis de argumentos
def main():
"""
지정한 경로 하위 폴더의 File들에서 Text를 추출하고 각 Text의 명사를 추출하여 엑셀파일로 저장
:return: 없음
"""
# region Args Parse & Usage set-up -------------------------------------------------------------
# parser = argparse.ArgumentParser(usage='usage test', description='description test')
usage_description = """--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment"""
# ToDo: 옵션추가: 복합어 추출할지 여부, 영문자 추출할지 여부, 영문자 길이 1자리 제외여부, ...
parser = argparse.ArgumentParser(description=usage_description, formatter_class=argparse.RawTextHelpFormatter)
# name argument 추가
parser.add_argument('--multi_process_count', required=False, type=int,
help='text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)')
parser.add_argument('--db_comment_file', required=False,
help='DB Table, Column comment 정보 파일명(예: comment.xlsx)')
parser.add_argument('--in_path', required=False, help='입력파일(ppt, doc, txt) 경로명(예: .\in) ')
parser.add_argument('--out_path', required=True, help='출력파일(xlsx, png) 경로명(예: .\out)')
args = parser.parse_args()
if args.multi_process_count:
multi_process_count = int(args.multi_process_count)
else:
multi_process_count = multiprocessing.cpu_count()
db_comment_file = args.db_comment_file
if db_comment_file is not None and not os.path.isfile(db_comment_file):
print('db_comment_file not found: %s' % db_comment_file)
exit(-1)
in_path = args.in_path
out_path = args.out_path
print('------------------------------------------------------------')
print('Word Extractor v%s start --- %s' % (_version_, get_current_datetime()))
print('##### arguments #####')
print('multi_process_count: %d' % multi_process_count)
print('db_comment_file: %s' % db_comment_file)
print('in_path: %s' % in_path)
print('out_path: %s' % out_path)
print('------------------------------------------------------------')
- Línea 395: Cree un objeto ArgumentParser del paquete argparse.
- Líneas 397 a 404: agregue los argumentos necesarios y analice los argumentos especificados en el momento de la ejecución.
- Líneas 406~425: Los argumentos se establecen como variables internas y se emiten los valores establecidos.
4.2.2. Extraer la lista de archivos para procesar
file_list = []
if in_path is not None and in_path.strip() != '':
print('[%s] Start Get File List...' % get_current_datetime())
in_abspath = os.path.abspath(in_path) # os.path.abspath('.') + '\\test_files'
file_types = ('.ppt', '.pptx', '.doc', '.docx', '.txt')
for root, dir, files in os.walk(in_abspath):
for file in sorted(files):
# 제외할 파일
if file.startswith('~'):
continue
# 포함할 파일
if file.endswith(file_types):
file_list.append(root + '\\' + file)
print('[%s] Finish Get File List.' % get_current_datetime())
print('--- File List ---')
print('\n'.join(file_list))
if db_comment_file is not None:
file_list.append(db_comment_file)
- Línea 436: Definir la lista de extensiones de archivo correspondientes a los archivos a procesar.
- Líneas 437~444: busque recursivamente todas las carpetas en in_path entre los argumentos especificados en el momento de la ejecución, determine si cada archivo es un archivo de destino y, de ser así, agréguelo a file_list.
- Líneas 451~452: si hay db_comment_file entre los argumentos especificados en la ejecución, agréguelo a file_list.
4.2.3. Ejecute get_file_text con procesamiento múltiple
print('[%s] Start Get File Text...' % get_current_datetime())
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_text_result = pool.map(get_file_text, file_list)
df_text = pd.concat(mp_text_result, ignore_index=True)
print('[%s] Finish Get File Text.' % get_current_datetime())
# 여기까지 text 추출완료. 아래에 단어 추출 시작
- Líneas 455~456: Ejecute la función get_file_text con file_lsit como entrada en cada proceso ejecutando tantos procesos como multi_process_count especificado en el momento de la ejecución y colocando el resultado en mp_text_result.
- Línea 457: Concatene cada elemento de la lista de mp_text_result, que tiene la forma de una lista de DataFrames, para hacer df_text, que es un DataFrame.
4.2.4. Ejecute get_word_list con procesamiento múltiple
# ---------- 병렬 실행 ----------
print('[%s] Start Get Word from File Text...' % get_current_datetime())
df_text_split = np.array_split(df_text, multi_process_count)
# mp_result = []
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_result = pool.map(get_word_list, df_text_split)
df_result = pd.concat(mp_result, ignore_index=True)
if 'DB' not in df_result.columns:
df_result['DB'] = ''
df_result['Schema'] = ''
df_result['Table'] = ''
df_result['Column'] = ''
print('[%s] Finish Get Word from File Text.' % get_current_datetime())
# ------------------------------
- Línea 463: divida las filas de df_text por multi_process_count y coloque cada trama de datos dividida en df_text_split (tipo de lista).
- Por ejemplo, si df_text tiene 1000 filas y multi_process_count es 4, se crean 4 DataFrames con 250 filas cada uno y se crean variables df_text_split con estos 4 DataFrames como elementos.
- Líneas 465~466: Ejecute la función get_word_list con df_text_split como entrada en cada proceso ejecutando tantos procesos como multi_process_count especificado en el momento de la ejecución y colocando el resultado en mp_result.
- Línea 468: Concatene cada elemento de la lista de mp_result, que tiene la forma de una lista de DataFrames, para crear un DataFrame, df_result.
- Líneas 469-473: 'DB', 'Schema', 'Table', 'Column' para simplificar la lógica de procesamiento posterior y evitar errores cuando 'DB' no existe en df_result.columns, es decir, cuando no se especifica db_comment_file. una columna con el nombre de ' como un valor vacío.
4.2.5. Obtenga frecuencias de palabras y ejecute make_word_cloud
print('[%s] Start Get Word Frequency...' % get_current_datetime())
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
df_group = df_group.sort_values(by='Freq', ascending=False)
print('[%s] Finish Get Word Frequency.' % get_current_datetime())
# df_group['Len'] = df_group['Word'].str.len()
# df_group['Len'] = df_group['Word'].apply(lambda x: len(x))
print('[%s] Start Make Word Cloud...' % get_current_datetime())
now_dt = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
make_word_cloud(df_group, now_dt, out_path)
print('[%s] Finish Make Word Cloud.' % get_current_datetime())
- Línea 480: cree un marco de datos df_result_subset seleccionando solo las columnas 'Palabra' y 'Fuente' de df_result.
- Línea 482: obtenga el recuento agrupando df_result_subset con la columna 'Palabra', extraiga los primeros 10 valores de 'Fuente' y conéctelos con un separador de filas para crear df_group DataFrame.
- Líneas 483~484: Designe el nombre de índice de df_group DataFrame como 'Word' y los nombres de columna como 'Freq' y 'Source', respectivamente.
- Línea 485: ordenación inversa df_group por 'Freq' (frecuencia de palabra).
- Línea 491: Pase df_group a la función make_word_cloud para crear y guardar la imagen de nube de palabras.
4.2.6. Guarde la lista de palabras extraídas y la frecuencia de palabras como un archivo de Excel, imprima el tiempo de ejecución y salga
print('[%s] Start Save the Extract result to Excel File...' % get_current_datetime())
df_result.index += 1
excel_style = {
'font-size': '10pt'
}
df_result = df_result.style.set_properties(**excel_style)
df_group = df_group.style.set_properties(**excel_style)
out_file_name = '%s\\extract_result_%s.xlsx' % (out_path, now_dt) # 'out\\extract_result_%s.xlsx' % now_dt
print('start writing excel file...')
with pd.ExcelWriter(path=out_file_name, engine='xlsxwriter') as writer:
df_result.to_excel(writer,
header=True,
sheet_name='단어추출결과',
index=True,
index_label='No',
freeze_panes=(1, 0),
columns=['Word', 'FileName', 'FileType', 'Page', 'Text', 'DB', 'Schema', 'Table', 'Column'])
df_group.to_excel(writer,
header=True,
sheet_name='단어빈도',
index=True,
index_label='단어',
freeze_panes=(1, 0))
workbook = writer.book
worksheet = writer.sheets['단어빈도']
wrap_format = workbook.add_format({'text_wrap': True})
worksheet.set_column("C:C", None, wrap_format)
# print('finished writing excel file')
print('[%s] Finish Save the Extract result to Excel File...' % get_current_datetime())
end_time = time.time()
# elapsed_time = end_time - start_time
elapsed_time = str(datetime.timedelta(seconds=end_time - start_time))
print('------------------------------------------------------------')
print('[%s] Finished.' % get_current_datetime())
print('overall elapsed time: %s' % elapsed_time)
print('------------------------------------------------------------')
- Líneas 495 a 501: establezca el tamaño de fuente de Excel en 10 puntos y establezca la ruta y el nombre del archivo de Excel que se guardará.
- Líneas 504~521: Guarde df_result y df_group DataFrame como un archivo de Excel usando pandas ExcelWriter.
- Líneas 526 a 532: Calcule el tiempo necesario para la ejecución, envíelo y salga.
Este artículo es largo, así que lo estoy publicando en dos partes. Continúa en el siguiente artículo.
<< Lista de artículos relacionados >>
- Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
- Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
- Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
- Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
- Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
- Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
- Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
Artículos relacionados:
 Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
 Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
 Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
 Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
 Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
 Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
 Optimización de la distribución del trabajo utilizando un algoritmo de empaque de contenedores unidimensional_4.Adjunto
Optimización de la distribución del trabajo utilizando un algoritmo de empaque de contenedores unidimensional_4.Adjunto
 Optimización de la distribución del trabajo mediante el algoritmo bin packing unidimensional_3.Implementación (2)
Optimización de la distribución del trabajo mediante el algoritmo bin packing unidimensional_3.Implementación (2)










Hola
Hice una función get_pdf_text usando el código de palabras de la herramienta de extracción de palabras y 'pdfplumber' que publicaste.
¿Puedo mostrártelo en un comentario o correo electrónico?
¡hola!
Implementé la función get_pdf_text usando el código fuente del extractor de palabras que publicaste.
Se confirmó que funciona cuando se agrega pdf a la parte del código existente relacionada con la extensión del archivo y se agrega la función get_pdf_tex.
Dime lo que necesita ser corregido y me encargaré de ello.
Necesita pip install pdfplomber.
importar pdfplomero
def get_pdf_text(nombre_de_archivo) -> Marco de datos:
hora_inicio = hora.hora()
imprimir('\r\nget_txt_text: ' + nombre_archivo)
df_text = pd.DataFrame()
archivo_pdf = pdfplumber.open(nombre_archivo)
página = 0
para pg en pdf_file.pages:
textos = pág.extraer_texto()
página += 1
para texto en textos.split():
si texto.strip() != ”:
sr_text = Series([nombre_archivo, 'pdf', página, texto, f'{nombre_archivo}:{página}:{texto}'],
index=['Nombre de archivo', 'Tipo de archivo', 'Página', 'Texto', 'Fuente'])
df_text = df_text.append(sr_text, ignore_index=True)
imprimir ('recuento de texto: %s' % str (df_text. forma [0]))
imprimir ('recuento de páginas: %d' % página)
archivo_pdf.cerrar()
hora_fin = hora.hora()
tiempo_transcurrido = str(datetime.timedelta(segundos=end_time – start_time))
print('[pid:%d] get_pdf_text tiempo transcurrido: %s' % (os.getpid(), tiempo_transcurrido))
devolver df_text
Gracias por compartir el código fuente de la función get_pdf_text.
El código fuente que escribió está sangrado, pero es un poco incómodo verlo porque la sangría no se muestra en los comentarios de WordPress.
Configuremos la sangría para que sea visible.
Al configurar la sangría para que sea visible, si necesita el código fuente original con sangría, lo subiré nuevamente.