Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
Echemos un vistazo a cómo ejecutar la herramienta de extracción de palabras y verifiquemos los resultados.
Esta es una continuación del artículo anterior.
3. Ejecute la herramienta de extracción de palabras
3.1. Descargar herramienta de extracción de palabras
La herramienta de extracción de palabras se ha subido a github.
https://github.com/DAToolset/ToolsForDataStandard/tree/main/WordExtractor
Los códigos fuente, las fuentes, los archivos de ejemplo de listas de tablas/columnas y los archivos de ejemplo de salida necesarios para la ejecución se agrupan en un archivo comprimido para su distribución, por lo que puede descargar este archivo.
https://github.com/DAToolset/ToolsForDataStandard/raw/main/WordExtractor/word_extractor.7z
Este archivo de distribución contiene los siguientes archivos:
[font] - NanumBarunGothic.ttf - NanumSquareR.ttf [out] - extract_result_20210829111836.xlsx - wordcloud_20210829111836.png - table,column comments.xlsx - word_extractor.py
La descripción de cada carpeta y archivo es la siguiente.
- [fuente]
- Carpeta que contiene las fuentes necesarias al crear WordCloud
- Si es necesario, se pueden agregar y usar otras fuentes cambiando el código fuente.
- Función a cambiar en el código fuente: make_word_cloud
- [afuera]
- Carpeta que contiene archivos de ejemplo de resultados de extracción de palabras
- El contenido de este archivo se puede encontrar en el siguiente artículo.
1.3.3. Datos de salida de la herramienta de extracción de palabras
- tabla, columna comentarios.xlsx
- Tabla DB, archivo de ejemplo de entrada de comentario de columna
- El contenido de este archivo se puede encontrar en el siguiente artículo.
1.3.1._word_extraction_tool_input_data
- word_extractor.py: Código fuente del extractor de palabras (Python)
- Nota: este archivo de código fuente está sujeto a cambios, por lo tanto, consulte el archivo github para obtener la última versión, no el archivo de distribución.
3.2. Cómo ejecutar la herramienta de extracción de Word
3.2.1. Descomprima el archivo descargado y active el entorno virtual Python
Extraiga el archivo comprimido de distribución que descargó anteriormente en una ruta apropiada. (por ejemplo, "d:\Proyecto\WordExtractor")
Ejecute Miniconda Prompt, muévase a la ruta descomprimida y active el entorno virtual de Python.
Para activar el entorno virtual de Python, consulte el siguiente artículo.
2.3. Creación y activación de un entorno virtual
Continúe en el siguiente estado de Miniconda Prompt.
(wordextr) d:\Project\WordExtractor>
3.2.2. Consultar ayuda
Puede consultar la ayuda especificando el argumento “–help” y ejecutándolo.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
La salida cuando se ejecuta es la siguiente.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
usage: word_extractor.py [-h] [--multi_process_count MULTI_PROCESS_COUNT] [--db_comment_file DB_COMMENT_FILE] [--in_path IN_PATH] --out_path OUT_PATH
--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment
optional arguments:
-h, --help show this help message and exit
--multi_process_count MULTI_PROCESS_COUNT
text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)
--db_comment_file DB_COMMENT_FILE
DB Table, Column comment 정보 파일명(예: comment.xlsx)
--in_path IN_PATH 입력파일(ppt, doc, txt) 경로명(예: .\in)
--out_path OUT_PATH 출력파일(xlsx, png) 경로명(예: .\out)
Hay tres formas de hacerlo. (Consulte "* Ejemplo de ejecución" en la ayuda anterior)
- Extraiga palabras solo de archivos de documentos
- Designe la carpeta donde se guardan los archivos de MS Word, PowerPoint y texto como “–in_path”, y designe la carpeta para generar los resultados como “–out_path”
- Extraiga palabras solo de la tabla DB, comentarios de columna
- Designe el archivo de Excel guardado en el formato de archivo de comentarios como “–db_comment_file” y designe la carpeta para generar los resultados como “–out_path”
- Extraiga palabras de ambos archivos de documentos, tablas de base de datos y comentarios de columna (cómo extraer 1 y 2 a la vez)
- Especifique todo “–in_path”, “–db_comment_file”, “–out_path”
El argumento “–multi_process_count” es el número de procesos que se ejecutarán en paralelo al extraer texto de un archivo y extraer palabras del texto. El rendimiento se puede mejorar especificando un número adecuado según el entorno de ejecución.
En este artículo, el argumento “-multi_process_count” no se especifica ni ejecuta. En este caso, se establece en el número de CPU lógicas en el entorno de ejecución durante el proceso de ejecución del código. (por ejemplo, 8 para CPU i5-8250U)
3.2.3. Método 1: extraer palabras solo de archivos de documentos
Primero, cree una carpeta para guardar el archivo del documento en la ruta donde se encuentra el código fuente de Python.
Por ejemplo, cree la carpeta "in" en "d:\Project\WordExtractor" y cree la ruta "d:\Project\WordExtractor\in".
Luego, copie los archivos de formato de MS Word, PowerPoint y texto a la carpeta "in". Incluso si hay varios niveles de carpetas en la carpeta "en", todos ellos se pueden explorar y procesar, por lo que se recomienda organizar las subcarpetas por unidad de negocio, etc.
Como referencia, en el momento de escribir este artículo (2021-10-24), los archivos HWP y PDF aún no son compatibles.
Ejecútalo con el siguiente comando: (Especifique –in_path, –out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out
Un ejemplo del resultado de la ejecución es el siguiente.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:15:11.985581 ##### arguments ##### multi_process_count: 8 db_comment_file: None in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:15:11.985581] Start Get File List... [2021-10-24 12:15:11.985581] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:15:11.985581] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx text count: 25 line count: 34 [pid:17976] get_txt_text elapsed time: 0:00:00.135933 text count: 124 page count: 5 [pid:5412] get_ppt_text elapsed time: 0:00:03.370637 text count: 59 page count: 3 [pid:22052] get_doc_text elapsed time: 0:00:04.100849 [2021-10-24 12:15:18.094089] Finish Get File Text. [2021-10-24 12:15:18.094089] Start Get Word from File Text... [pid:25016] input text count:26, extracted word count: 31 [pid:25016] get_word_list finished. total: 26, elapsed time: 0:00:00.109351 [pid:17704] input text count:26, extracted word count: 54 [pid:17704] get_word_list finished. total: 26, elapsed time: 0:00:00.156214 [pid:18468] input text count:26, extracted word count: 52 [pid:18468] get_word_list finished. total: 26, elapsed time: 0:00:00.140596 [pid:3456] input text count:26, extracted word count: 38 [pid:3456] get_word_list finished. total: 26, elapsed time: 0:00:00.109350 [pid:15400] input text count:26, extracted word count: 50 [pid:15400] get_word_list finished. total: 26, elapsed time: 0:00:00.140594 [pid:25892] input text count:26, extracted word count: 65 [pid:25892] get_word_list finished. total: 26, elapsed time: 0:00:00.171835 [pid:3592] input text count:26, extracted word count: 147 [pid:3592] get_word_list finished. total: 26, elapsed time: 0:00:00.312458 [pid:9512] input text count:26, extracted word count: 180 [pid:9512] get_word_list finished. total: 26, elapsed time: 0:00:00.374976 [2021-10-24 12:15:20.320614] Finish Get Word from File Text. [2021-10-24 12:15:20.320614] Start Get Word Frequency... [2021-10-24 12:15:20.336234] Finish Get Word Frequency. [2021-10-24 12:15:20.336234] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:06.681665 [2021-10-24 12:15:27.017899] Finish Make Word Cloud. [2021-10-24 12:15:27.017899] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:15:27.643679] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:15:27.643679] Finished. overall elapsed time: 0:00:15.658098 ------------------------------------------------------------
3.2.4. Método 2: extraer palabras solo de la tabla DB, comentarios de columna
Primero, abra el archivo "table,column comments.xlsx" incluido en el archivo comprimido en Excel, complete el contenido de acuerdo con el formato y guarde.
Vea a continuación ejemplos de formato y contenido.
1.3.1. material de entrada de la herramienta de extracción de palabras
Ejecútalo con el siguiente comando: (Especifique –db_comment_file, –out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
El nombre del archivo estaba entre comillas dobles (“) porque el nombre del archivo de entrada contenía caracteres en blanco.
Si el archivo "table,column comments.xlsx" es diferente de la ruta del archivo de código fuente de Python, especifíquelo incluyendo la ruta. Se supone aquí que están en el mismo camino.
Un ejemplo del resultado de la ejecución es el siguiente.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:34:23.369210 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: None out_path: .\out ------------------------------------------------------------ [2021-10-24 12:34:23.370209] Start Get File Text... get_db_comment_text: table,column comments.xlsx table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:17088] get_db_comment_text elapsed time: 0:00:01.216618 text count: 1680 [2021-10-24 12:34:26.577237] Finish Get File Text. [2021-10-24 12:34:26.577237] Start Get Word from File Text... [pid:25240] current: 100, total: 210, progress: 47.62% [pid:21792] current: 100, total: 210, progress: 47.62% [pid:14788] current: 100, total: 210, progress: 47.62% [pid:10660] current: 100, total: 210, progress: 47.62% [pid:17208] current: 100, total: 210, progress: 47.62% [pid:13300] current: 100, total: 210, progress: 47.62% [pid:23764] current: 100, total: 210, progress: 47.62% [pid:25068] current: 100, total: 210, progress: 47.62% [pid:13300] current: 200, total: 210, progress: 95.24% [pid:14788] current: 200, total: 210, progress: 95.24% [pid:13300] input text count:210, extracted word count: 804 [pid:13300] get_word_list finished. total: 210, elapsed time: 0:00:02.900049 [pid:10660] current: 200, total: 210, progress: 95.24% [pid:14788] input text count:210, extracted word count: 850 [pid:14788] get_word_list finished. total: 210, elapsed time: 0:00:03.005057 [pid:10660] input text count:210, extracted word count: 819 [pid:10660] get_word_list finished. total: 210, elapsed time: 0:00:03.040949 [pid:17208] current: 200, total: 210, progress: 95.24% [pid:25240] current: 200, total: 210, progress: 95.24% [pid:17208] input text count:210, extracted word count: 929 [pid:17208] get_word_list finished. total: 210, elapsed time: 0:00:03.182333 [pid:25240] input text count:210, extracted word count: 871 [pid:25240] get_word_list finished. total: 210, elapsed time: 0:00:03.320128 [pid:23764] current: 200, total: 210, progress: 95.24% [pid:21792] current: 200, total: 210, progress: 95.24% [pid:23764] input text count:210, extracted word count: 1054 [pid:23764] get_word_list finished. total: 210, elapsed time: 0:00:03.362429 [pid:25068] current: 200, total: 210, progress: 95.24% [pid:21792] input text count:210, extracted word count: 1077 [pid:21792] get_word_list finished. total: 210, elapsed time: 0:00:03.651294 [pid:25068] input text count:210, extracted word count: 1163 [pid:25068] get_word_list finished. total: 210, elapsed time: 0:00:03.616955 [2021-10-24 12:34:32.287245] Finish Get Word from File Text. [2021-10-24 12:34:32.287245] Start Get Word Frequency... [2021-10-24 12:34:32.313363] Finish Get Word Frequency. [2021-10-24 12:34:32.313363] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.572230 [2021-10-24 12:34:42.886547] Finish Make Word Cloud. [2021-10-24 12:34:42.886547] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:34:48.636633] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:34:48.636633] Finished. overall elapsed time: 0:00:25.266424 ------------------------------------------------------------
3.2.5. Método 3: extracción de palabras de ambos archivos de documentos, tablas de base de datos y comentarios de columna
Este es un método que puede ejecutar el método 1 y el método 2 al mismo tiempo.
Ejecútalo con el siguiente comando: (Especifique –db_comment_file, –in_path, –out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out
Un ejemplo del resultado de la ejecución es el siguiente.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:43:31.847674 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:43:31.848673] Start Get File List... [2021-10-24 12:43:31.849672] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:43:31.849672] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx get_db_comment_text: table,column comments.xlsx text count: 25 line count: 34 [pid:11692] get_txt_text elapsed time: 0:00:00.135359 table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:21044] get_db_comment_text elapsed time: 0:00:01.580088 text count: 1680 text count: 124 page count: 5 [pid:23812] get_ppt_text elapsed time: 0:00:04.757793 text count: 59 page count: 3 [pid:23724] get_doc_text elapsed time: 0:00:06.661778 [2021-10-24 12:43:40.690639] Finish Get File Text. [2021-10-24 12:43:40.690639] Start Get Word from File Text... [pid:18392] current: 100, total: 236, progress: 42.37% [pid:8036] current: 100, total: 236, progress: 42.37% [pid:26864] current: 100, total: 236, progress: 42.37% [pid:23288] current: 100, total: 236, progress: 42.37% [pid:15596] current: 100, total: 236, progress: 42.37% [pid:8036] current: 200, total: 236, progress: 84.75% [pid:18208] current: 100, total: 236, progress: 42.37% [pid:17976] current: 100, total: 236, progress: 42.37% [pid:4324] current: 100, total: 236, progress: 42.37% [pid:18392] current: 200, total: 236, progress: 84.75% [pid:26864] current: 200, total: 236, progress: 84.75% [pid:8036] input text count:236, extracted word count: 739 [pid:8036] get_word_list finished. total: 236, elapsed time: 0:00:02.651907 [pid:18392] input text count:236, extracted word count: 780 [pid:18392] get_word_list finished. total: 236, elapsed time: 0:00:02.879298 [pid:15596] current: 200, total: 236, progress: 84.75% [pid:26864] input text count:236, extracted word count: 887 [pid:26864] get_word_list finished. total: 236, elapsed time: 0:00:03.161543 [pid:15596] input text count:236, extracted word count: 979 [pid:15596] get_word_list finished. total: 236, elapsed time: 0:00:03.443786 [pid:18208] current: 200, total: 236, progress: 84.75% [pid:23288] current: 200, total: 236, progress: 84.75% [pid:17976] current: 200, total: 236, progress: 84.75% [pid:18208] input text count:236, extracted word count: 1181 [pid:18208] get_word_list finished. total: 236, elapsed time: 0:00:03.831052 [pid:4324] current: 200, total: 236, progress: 84.75% [pid:23288] input text count:236, extracted word count: 1242 [pid:23288] get_word_list finished. total: 236, elapsed time: 0:00:04.139228 [pid:17976] input text count:236, extracted word count: 1294 [pid:17976] get_word_list finished. total: 236, elapsed time: 0:00:04.113296 [pid:4324] input text count:236, extracted word count: 1082 [pid:4324] get_word_list finished. total: 236, elapsed time: 0:00:04.334706 [2021-10-24 12:43:47.324098] Finish Get Word from File Text. [2021-10-24 12:43:47.325098] Start Get Word Frequency... [2021-10-24 12:43:47.353058] Finish Get Word Frequency. [2021-10-24 12:43:47.353058] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.604237 [2021-10-24 12:43:57.958289] Finish Make Word Cloud. [2021-10-24 12:43:57.958289] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:44:04.752046] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:44:04.752046] Finished. overall elapsed time: 0:00:32.903374 ------------------------------------------------------------
Una parte del proceso de ejecución anterior se captura y pega como una imagen.
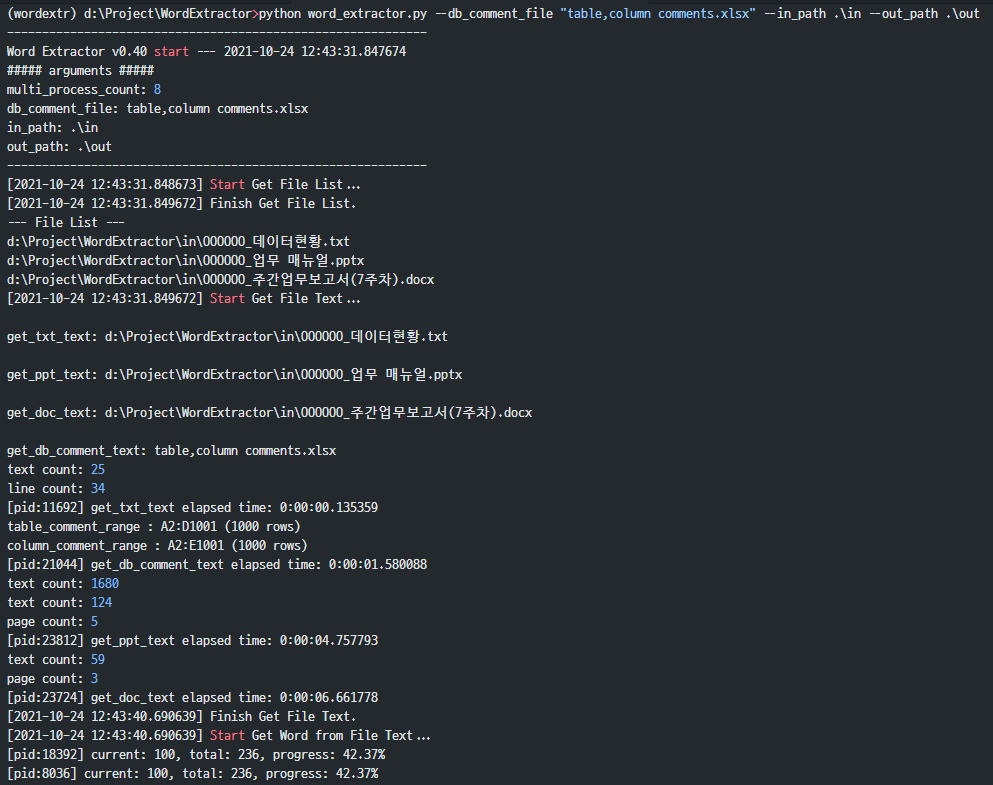
3.2.6. Cómo comprobar los resultados de la ejecución
Cuando se ejecuta, se crean dos archivos (xlsx, png) en la carpeta (\out) designada como la ruta de salida. El año, el mes, la hora, el minuto y el segundo (AAAAMMDHHMISS) se asignan automáticamente al nombre del archivo para que pueda comprobar cuándo se creó.
Por ejemplo, el archivo de resultados de ejecución incluido en la carpeta de salida del archivo comprimido de distribución es el siguiente.
- extract_result_20210829111836.xlsx: archivo Excel de resultados de extracción de Word
- wordcloud_20210829111836.png: archivo de imagen de nube de palabras creado con la hoja de "frecuencia de palabras" del archivo de Excel de resultados de extracción de palabras
Para conocer el formato y el contenido del archivo de resultados de la ejecución, consulte el artículo siguiente.
1.3.3. Datos de salida de la herramienta de extracción de palabras
3.2.7. Precauciones/Notas sobre la ejecución
- Si ejecuta aplicaciones de MS-Word o PowerPoint antes de la ejecución, el rendimiento de la ejecución mejora ligeramente.
- Durante la ejecución, el archivo se abre en la aplicación MS-Word o PowerPoint y se cierra después del procesamiento. Mientras se ejecuta el extractor de palabras, no use cada aplicación y déjelo como está.
- Cuantos más archivos, más páginas en el archivo y más filas de datos en el archivo de comentarios de Excel, mayor será el tiempo de ejecución.
- Se recomienda probar si funciona bien guardando por separado una parte del archivo de entrada y una parte de los datos del archivo de comentarios de Excel antes de ejecutarlo todo.
- Teniendo en cuenta que llevará mucho tiempo ejecutarlo todo, es mejor hacerlo durante una comida o un descanso.
Este artículo analizó cómo usar la herramienta de extracción de palabras. Deje un comentario si tiene alguna pregunta sobre el uso o si tiene alguna buena característica para agregar.
El próximo artículo echará un vistazo al código fuente.
<< Lista de artículos relacionados >>
- Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
- Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
- Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
- Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
- Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
- Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
- Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
Artículos relacionados:
 Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
 Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
 Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
 Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
 Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
 Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
 Optimización de la distribución del trabajo utilizando un algoritmo de empaque de contenedores unidimensional_4.Adjunto
Optimización de la distribución del trabajo utilizando un algoritmo de empaque de contenedores unidimensional_4.Adjunto
 Optimización de la distribución del trabajo mediante el algoritmo bin packing unidimensional_3.Implementación (2)
Optimización de la distribución del trabajo mediante el algoritmo bin packing unidimensional_3.Implementación (2)










¡Hola! gracias por el buen código
Tengo una pregunta al ejecutar el código con un archivo pptx como entrada.
Probé extrayendo palabras de un archivo .pptx.
Existe el fenómeno de que una ventana ppt vacía no se cierra y flota cuando se ejecuta el código.
Word, txt y excel no tienen un fenómeno similar.
Me gustaría preguntar si este es un fenómeno temporal dependiendo de la versión de Office.
el medio ambiente es
Estoy usando Windows 11, versión Office 365.
gracias
Hola, gracias por visitar y comentar.
Me gustaría saber más sobre la situación de Kiyoung Kim.
¿Cuál de los siguientes es el caso?
1) Un fenómeno en el que la aplicación de PowerPoint no responde "durante la ejecución del código" y no pasa al siguiente archivo
2) Un fenómeno en el que la aplicación de PowerPoint permanece abierta sin cerrarse “después” de la ejecución del código
Si 1) es el caso,
– Si cierra a la fuerza PowerPoint en el administrador de tareas, ¿podrá pasar al siguiente archivo?
– Existe la posibilidad de que el archivo actual no se haya procesado correctamente.
– Se recomienda volver a ejecutar la tarea desde el principio.
Si 2) es el caso,
– Es normal que la aplicación de PowerPoint permanezca abierta si ejecuta la herramienta de extracción de palabras después de ejecutar PowerPoint por adelantado.
– Si no ha ejecutado PowerPoint, es un comportamiento extraño, pero si se procesan todos los archivos, no necesita preocuparse por eso.
Como referencia, si ejecuta la herramienta de extracción de palabras sin ejecutar aplicaciones como PowerPoint y Excel, es normal que las aplicaciones como PowerPoint y Excel se ejecuten durante el proceso de automatización OLE y luego finalicen después de que se complete el procesamiento.
De lo contrario, por favor deje comentarios adicionales.
Hola, gracias por la rápida respuesta!
En mi caso, 2) "después" de la ejecución del código, la aplicación de powerpoint permanece abierta sin cerrarse.
Como dijiste, parece ser un comportamiento anormal ya que PowerPoint no se ejecutó con anticipación.
Todos los archivos fueron procesados sin anomalías.
¡gracias!
Gracias por informarnos de la situación y los resultados.
Por favor, úsalo bien~ ^^
Hola. Actualmente estoy usando esa herramienta, pero no funciona. ¿Es un problema con miniforge? Primero, instalaré miniconda en un entorno diferente y lo ejecutaré nuevamente.
——————————————————————————————
(wordextr) C:\Users\User\Downloads\word_extractor>python word_extractor.py –in_path .\in –out_path .\out
C:\Users\User\Downloads\word_extractor\word_extractor.py:382: Advertencia de sintaxis: secuencia de escape no válida '\o'
use_description = “””— Descripción —
C:\Users\User\Downloads\word_extractor\word_extractor.py:406: Advertencia de sintaxis: secuencia de escape no válida '\i'
parser.add_argument('–in_path', require=False, help='Archivo de entrada (ppt, doc, txt) nombre de ruta (por ejemplo, .\in) ')
C:\Users\User\Downloads\word_extractor\word_extractor.py:407: Advertencia de sintaxis: secuencia de escape no válida '\o'
parser.add_argument('–out_path', require=True, help='Nombre de ruta del archivo de salida (xlsx, png) (por ejemplo, .\out)')
————————————————————
Inicio de Word Extractor v0.41 — 2024-01-18 17:36:57.283006
##### argumentos #####
recuento_multiproceso: 16
db_comment_file: Ninguno
in_path: .\en
ruta_salida: .\salida
————————————————————
[2024-01-18 17:36:57.288351] Iniciar Obtener lista de archivos…
[2024-01-18 17:36:57.289390] Finalizar Obtener lista de archivos.
— Lista de archivos —
[2024-01-18 17:36:57.290381] Iniciar Obtener texto del archivo…
Rastreo (llamadas recientes más última):
Archivo “C:\Users\User\Downloads\word_extractor\word_extractor.py”, línea 559, en
principal()
Archivo “C:\Users\User\Downloads\word_extractor\word_extractor.py”, línea 461, en principal
df_text = pd.concat (mp_text_result, ignore_index = Verdadero)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Archivo “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, línea 380, en concat
op = _Concatenador(
^^^^^^^^^^^^^^
Archivo “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, línea 443, en __init__
objs, claves = self._clean_keys_and_objs(objs, claves)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Archivo “C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”, línea 505, en _clean_keys_and_objs
elevar ValueError ("No hay objetos para concatenar")
ValueError: No hay objetos para concatenar
La información de la versión es la siguiente.
Pitón 3.12.1
Versión del paquete
————— ————
contorno 1.2.0
ciclador 0.12.1
eunjeon 0.4.0
herramientas de fuentes 4.47.2
Jinja2 3.1.3
kiwisolver 1.4.5
MarkupSafe 2.1.3
matplotlib 3.8.2
numeroso 1.26.3
embalaje 23.2
pandas 2.1.4
almohada 10.2.0
pipa 23.3.2
pyparsing 3.1.1
python-dateutil 2.8.2
Pytz 2023.3.post1
pywin32 306
herramientas de configuración69.0.3
seis 1.16.0
datos tz 2023.4
rueda 0.42.0
nube de palabras 1.9.3
XlsxWriter 3.1.9
Este error aparece si no hay ningún archivo con la siguiente extensión en el directorio de entrada.
– .ppt, .pptx
– .doc, .docx
- .TXT
Lo probé de la siguiente manera:
————————————————————————–
(.venv) D:\Temp\python_venv\wordextr_test>python –versión
Pitón 3.11.1
(.venv) D:\Temp\python_venv\wordextr_test>python word_extractor.py –in_path .\in –out_path .\out
————————————————————
Inicio de Word Extractor v0.41 — 2024-01-19 08:55:44.842578
##### argumentos #####
recuento_multiproceso: 8
db_comment_file: Ninguno
in_path: .\en
ruta_salida: .\salida
————————————————————
[2024-01-19 08:55:44.845602] Iniciar Obtener lista de archivos…
[2024-01-19 08:55:44.845602] Finalizar Obtener lista de archivos.
— Lista de archivos —
[2024-01-19 08:55:44.845602] Iniciar Obtener texto del archivo…
Rastreo (llamadas recientes más última):
Archivo “D:\Temp\python_venv\wordextr_test\word_extractor.py”, línea 164, en
principal()
Archivo “D:\Temp\python_venv\wordextr_test\word_extractor.py”, línea 152, en principal
df_text = pd.concat (mp_text_result, ignore_index = Verdadero)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Archivo “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, línea 380, en concat
op = _Concatenador(
^^^^^^^^^^^^^^
Archivo “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, línea 443, en __init__
objs, claves = self._clean_keys_and_objs(objs, claves)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Archivo “D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”, línea 505, en _clean_keys_and_objs
elevar ValueError ("No hay objetos para concatenar")
ValueError: No hay objetos para concatenar
(.venv) D:\Temp\python_venv\wordextr_test>dir .\in
Volumen en la unidad D: Datos
Número de serie del volumen: D6EC-7CFE
Directorio D:\Temp\python_venv\wordextr_test\in
2024-01-18 21:41
2024-01-18 21:41
0 archivos 0 bytes
2 directorios 34.305.060.864 bytes restantes
Hola. Actualmente estoy usando esa herramienta, pero sigo recibiendo un error. Lo busqué y parece ser un problema con la versión Pandas. (Parece que la función .appen no se proporciona a partir de Pandas 2). ¿O es otro error?
(wordextr) C:\Users\hyelm\Documents\word_extractor>python word_extractor.py. –db_comment_file “table_column_comments1.xlsx” –out_path 'C:\Users\hyelm\Documents\word_extractor\out'
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: Advertencia de sintaxis: secuencia de escape no válida '\o'
use_description = “””— Descripción —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: Advertencia de sintaxis: secuencia de escape no válida '\i'
parser.add_argument('–in_path', require=False, help='Archivo de entrada (ppt, doc, txt) nombre de ruta (por ejemplo, .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: Advertencia de sintaxis: secuencia de escape no válida '\o'
parser.add_argument('–out_path', require=True, help='Nombre de ruta del archivo de salida (xlsx, png) (por ejemplo, .\out)')
————————————————————
Inicio de Word Extractor v0.41 — 2024-04-29 14:28:41.474667
##### argumentos #####
recuento_multiproceso: 4
db_comment_file: tabla_columna_comentarios1.xlsx
in_path: Ninguno
out_path: 'C:\Usuarios\hyelm\Documentos\word_extractor\out'
————————————————————
[2024-04-29 14:28:41.479798] Iniciar Obtener texto del archivo…
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: Advertencia de sintaxis: secuencia de escape no válida '\o'
use_description = “””— Descripción —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: Advertencia de sintaxis: secuencia de escape no válida '\i'
parser.add_argument('–in_path', require=False, help='Archivo de entrada (ppt, doc, txt) nombre de ruta (por ejemplo, .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: Advertencia de sintaxis: secuencia de escape no válida '\o'
parser.add_argument('–out_path', require=True, help='Nombre de ruta del archivo de salida (xlsx, png) (por ejemplo, .\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: Advertencia de sintaxis: secuencia de escape no válida '\o'
use_description = “””— Descripción —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: Advertencia de sintaxis: secuencia de escape no válida '\i'
parser.add_argument('–in_path', require=False, help='Archivo de entrada (ppt, doc, txt) nombre de ruta (por ejemplo, .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: Advertencia de sintaxis: secuencia de escape no válida '\o'
parser.add_argument('–out_path', require=True, help='Nombre de ruta del archivo de salida (xlsx, png) (por ejemplo, .\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: Advertencia de sintaxis: secuencia de escape no válida '\o'
use_description = “””— Descripción —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: Advertencia de sintaxis: secuencia de escape no válida '\i'
parser.add_argument('–in_path', require=False, help='Archivo de entrada (ppt, doc, txt) nombre de ruta (por ejemplo, .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: Advertencia de sintaxis: secuencia de escape no válida '\o'
parser.add_argument('–out_path', require=True, help='Nombre de ruta del archivo de salida (xlsx, png) (por ejemplo, .\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: Advertencia de sintaxis: secuencia de escape no válida '\o'
use_description = “””— Descripción —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: Advertencia de sintaxis: secuencia de escape no válida '\i'
parser.add_argument('–in_path', require=False, help='Archivo de entrada (ppt, doc, txt) nombre de ruta (por ejemplo, .\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: Advertencia de sintaxis: secuencia de escape no válida '\o'
parser.add_argument('–out_path', require=True, help='Nombre de ruta del archivo de salida (xlsx, png) (por ejemplo, .\out)')
get_db_comment_text: table_column_comments1.xlsx
table_comment_range: A2:D7112 (7111 filas)
column_comment_range: A2:E181935 (181934 filas)
multiprocesamiento.pool.RemoteTraceback:
“””
Rastreo (llamadas recientes más última):
Archivo “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, línea 125, en trabajador
resultado = (Verdadero, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
Archivo “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, línea 48, en mapstar
lista de retorno (mapa (* argumentos))
^^^^^^^^^^^^^^^^
Archivo “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, línea 369, en get_file_text
df_text = get_db_comment_text(nombre_archivo)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Archivo “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, línea 343, en get_db_comment_text
df_text = df_column.append(df_table, ignore_index=True)
^^^^^^^^^^^^^^^^
Archivo “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\site-packages\pandas\core\generic.py”, línea 6296, en __getattr__
devolver objeto.__getattribute__(yo, nombre)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: el objeto 'DataFrame' no tiene el atributo 'append'. ¿Quiso decir: '_append'?
“””
La excepción anterior fue la causa directa de la siguiente excepción:
Rastreo (llamadas recientes más última):
Archivo “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, línea 559, en
principal()
Archivo “C:\Users\hyelm\Documents\word_extractor\word_extractor.py”, línea 460, en principal
mp_text_result = pool.map(get_file_text, file_list)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Archivo “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, línea 367, en el mapa
devolver self._map_async(func, iterable, mapstar, chunksize).get()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Archivo “C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”, línea 774, en get
aumentar self._value
AttributeError: el objeto 'DataFrame' no tiene el atributo 'añadir'
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: el objeto 'DataFrame' no tiene el atributo 'append'. ¿Quiso decir: '_append'?
“””
El código del comentario anterior se copió de forma demasiado extraña, así que lo dejaré de nuevo.
¿Este error se debe a un problema con la versión de Pandas?
A partir de Pandas v2.0, ya no se admite append, por lo que es correcto cambiar a concat.
He hecho referencia a los dos documentos siguientes.
https://yunwoong.tistory.com/253
https://stackoverflow.com/questions/75956209/error-dataframe-object-has-no-attribute-append
Me está costando mucho encontrar tiempo estos días, así que no sé cuándo podré cambiar el código fuente.
Al instalar Pandas, ¿le gustaría especificar e instalar una versión anterior?
Espero que vaya bien ~