Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
Una descripción general de las herramientas de extracción de palabras que pueden ser útiles para el trabajo de estandarización de datos, especialmente para crear palabras candidatas estándar.
1. Descripción general de la herramienta de extracción de palabras
1.1. Por qué desarrollamos la herramienta de extracción de palabras
Entre las tareas iniciales de estandarización de datos, la tarea más difícil es recopilar la mayor cantidad de candidatos posible y rápidamente para que se registren como palabras estándar. Herramienta de verificación de estándares de datos (ver: Herramienta de verificación estándar de datos_1.Descripción general) se puede utilizar para extraer palabras candidatas estándar, pero tiene las siguientes dificultades.
- Si la tabla de base de datos, los datos de comentarios de columna contienen muchos caracteres especiales (símbolos como #, $, %, ., \, etc. y separadores de línea, etc.), se requiere un esfuerzo considerable para eliminarlos o refinarlos.
- Es difícil saber la frecuencia de las palabras, por lo que es difícil determinar si registrar solo palabras sueltas, solo palabras compuestas o tanto palabras sueltas como compuestas.
- Si una palabra compuesta se identifica más tarde después de confirmar una palabra estándar y afecta el nombre físico de un término estándar que ya se ha registrado, las excepciones a la regla de nomenclatura estándar pueden dificultar la gestión.
La herramienta de extracción de palabras se desarrolló para paliar algunas de estas dificultades. En particular, esperamos que sea útil en los siguientes casos.
- Si no hay un diccionario estándar de datos actual o incluso si la cantidad de palabras estándar es pequeña
- Su trabajo es tan único que no existe un diccionario estándar de datos que sea adecuado como referencia.
- Cuando la tabla de la base de datos y los comentarios de las columnas son demasiado grandes y lleva mucho tiempo extraer manualmente las palabras
- O, por el contrario, cuando hay poco contenido en las tablas de la base de datos y en los comentarios de las columnas, por lo que no es adecuado extraer palabras estándar y sí lo es extraerlas de documentos como manuales de trabajo.
- Además, si es necesario extraer palabras y frecuencias de los documentos
1.2. concepto de herramienta de extracción de palabras
La herramienta de extracción de palabras es una herramienta que recibe varios tipos de archivos como entrada, extrae palabras y palabras compuestas utilizando un analizador de morfemas de procesamiento de lenguaje natural y genera la frecuencia y la fuente (nombre de archivo, nombre de tabla, nombre de columna, etc.) como un Archivo Excel.
Mecab, un analizador de morfemas de procesamiento de lenguaje natural (NLP) coreano, se utilizó y desarrolló en Python v3.8. Kkma, Komoran, Hannanum, Okt (anteriormente conocido como Twitter) y Mecab son bibliotecas representativas entre los analizadores de morfemas de procesamiento del lenguaje natural coreano. Entre ellos, Mecab fue seleccionado por tener el mejor desempeño.
La comparación de rendimiento de los analizadores de morfemas de procesamiento de lenguaje natural se puede encontrar en el siguiente enlace.
referencia: https://konlpy.org/ko/latest/morph/#comparison-between-pos-tagging-classes
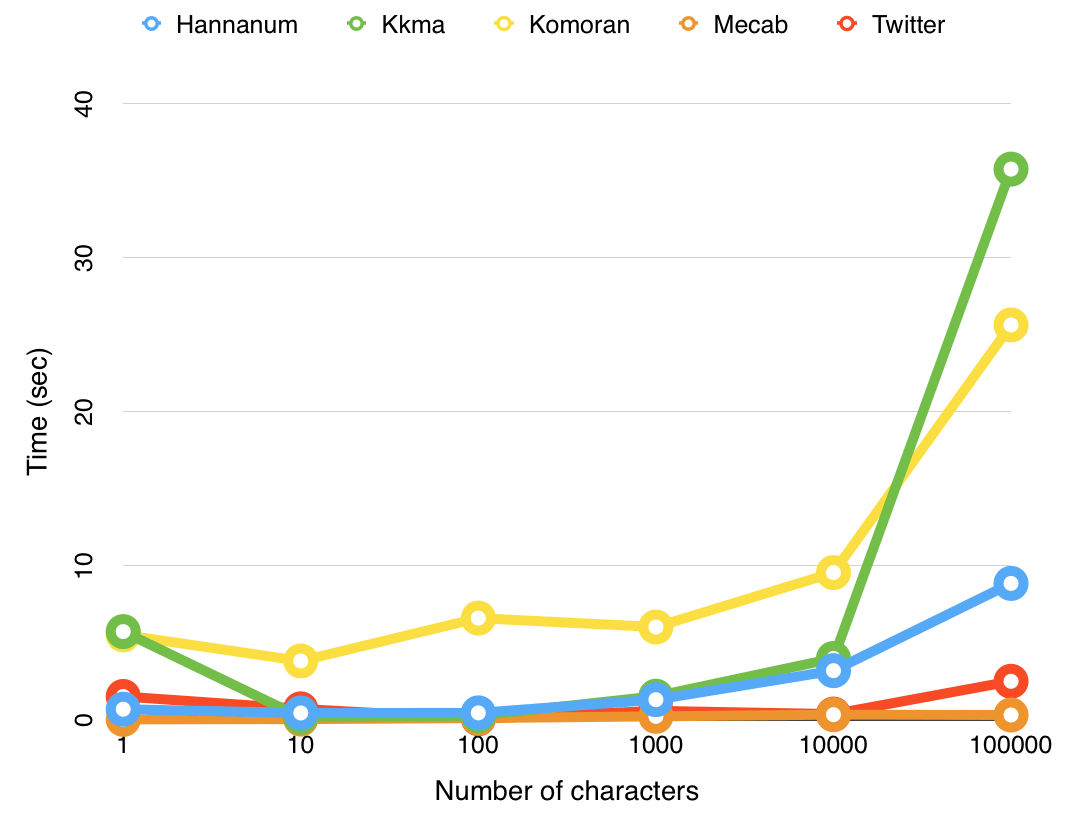
El tiempo de ejecución de acuerdo con el aumento en el número de caracteres de entrada se puede resumir de la siguiente manera. (El tiempo de ejecución disminuye y el rendimiento mejora a medida que avanza de izquierda a derecha)
Kkma > Komoran > Hannanum > Okt (Twitter) > Mecab
Para referencia, el enlace de arriba es Paquete KoNLPyEste es el sitio de la persona que lo desarrolló. KoNLPyes un paquete basado en Python que agrupa varios analizadores de morfemas en uno.
KoNLPy: https://konlpy.org/ko/latest/
1.3. Cómo funciona el extractor de palabras
Mire brevemente los datos de entrada, la lógica de procesamiento y los datos de salida.
1.3.1. material de entrada de la herramienta de extracción de palabras
Los datos de entrada se pueden especificar en una o ambas de las dos formas siguientes.
- Documentos: MS Word, PowerPoint, archivos de texto
- Al momento de escribir este artículo (2021-08-29), los formatos HWP y PDF aún no son compatibles.
- Tabla DB, comentario de columna Fuente: archivo de Excel
- Elementos de datos de comentario de tabla: base de datos, esquema, nombre de tabla, comentario de tabla
- Elementos de datos de comentario de columna: base de datos, esquema, nombre de tabla, comentario de tabla, nombre de columna, comentario de columna
▼ Un ejemplo de datos de comentarios de tabla es el siguiente.
| Base de datos | Esquema | Nombre de la tabla | Comentario de tabla |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | codigo administrativo |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODERECPTNLOG | Registro de recepción de código de administración |
| DB1 | PROPIETARIO1 | COMTCCMNCLCODE | Código de clasificación común |
| DB1 | PROPIETARIO1 | COMTCCMNCODE | código común |
| DB1 | PROPIETARIO1 | COMTCCMNDETAILCODE | Código de detalle común |
▼ Ejemplos de datos de comentarios de columna son los siguientes. Esta es la lista de columnas de COMTCADMINISTCODE (código administrativo) entre la lista de tablas anterior.
| Base de datos | Esquema | Nombre de la tabla | Nombre de columna | Comentario de columna |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE | división del distrito administrativo |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE | código de distrito administrativo |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | USE_AT | Si usar o no |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM | nombre del distrito administrativo |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | UPPER_ADMINIST_ZONE_CODE | Código del Distrito Administrativo Superior |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | CREAT_DE | fecha de creación |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ABL_DE | fecha de abolición |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | FRST_REGIST_PNTTM | primer registro |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | FRST_REGISTER_ID | ID de registrante inicial |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | LAST_UPDT_PNTTM | Última hora de modificación |
| DB1 | PROPIETARIO1 | COMTCADMINISTCODE | LAST_UPDUSR_ID | Última identificación modificada |
* Los datos de ejemplo anteriores se crearon utilizando los scripts de comentarios de tabla y columna en la página "Información de configuración de tabla de componentes comunes" del Marco estándar de gobierno electrónico v3.8.
(fuente: https://www.egovframe.go.kr/wiki/doku.php?id=egovframework:com:v3.8:init_table)
1.3.2. Lógica de procesamiento de la herramienta de extracción de palabras
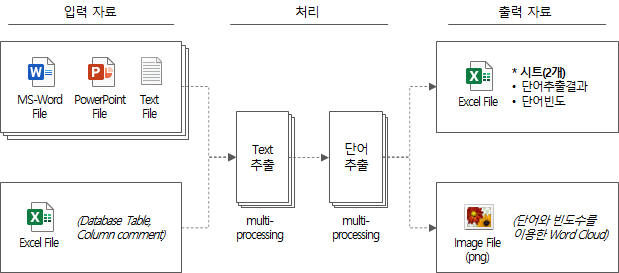
Un breve resumen de toda la lógica de procesamiento es el siguiente.
- Extraiga texto (línea por fila, tabla/columna) abriendo los datos de entrada secuencialmente
- Extracción de palabras candidatas en forma de 1 sustantivo, n sustantivos, prefijo + n sustantivos, n sustantivos + sufijos, prefijo + n sustantivos + sufijos usando Mecab, un paquete analizador de morfemas de lenguaje natural
- Encuentre la frecuencia de las palabras extraídas de todos los datos de entrada y guarde el resultado de la extracción de palabras como un archivo de salida
- Cree y guarde la nube de palabras como archivo png con lista de palabras y frecuencia
- Emite el tiempo total requerido y sale
Un diagrama simplificado del proceso anterior es el siguiente.
1.3.3. Datos de salida de la herramienta de extracción de palabras
Los datos de salida, que son el resultado del procesamiento de los datos de entrada, son un archivo de Excel y un archivo de imagen (png) en forma de nube de palabras.
El archivo de Excel consta de dos hojas. El siguiente es un ejemplo de datos de comentario de columna y tabla DB como entrada.
▼ Ficha “Ejemplo de resultado de extracción de palabras”
| No | palabra | Nombre del archivo | Tipo de archivo | Página | Texto | base de datos | Esquema | mesa | Columna |
| 1 | administración | tabla,columna comentarios.xlsx | columna | 0 | división del distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 2 | área | tabla,columna comentarios.xlsx | columna | 0 | división del distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 3 | división | tabla,columna comentarios.xlsx | columna | 0 | división del distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 4 | División administrativa [compuesto] | tabla,columna comentarios.xlsx | columna | 0 | división del distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 5 | administración | tabla,columna comentarios.xlsx | columna | 0 | código de distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 6 | área | tabla,columna comentarios.xlsx | columna | 0 | código de distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 7 | código | tabla,columna comentarios.xlsx | columna | 0 | código de distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 8 | Código de distrito administrativo [compuesto] | tabla,columna comentarios.xlsx | columna | 0 | código de distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 9 | usar | tabla,columna comentarios.xlsx | columna | 0 | Si usar o no | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | USE_AT |
| 10 | Si | tabla,columna comentarios.xlsx | columna | 0 | Si usar o no | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | USE_AT |
| 11 | Ya sea para usar [palabra compuesta] | tabla,columna comentarios.xlsx | columna | 0 | Si usar o no | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | USE_AT |
| 12 | región | tabla,columna comentarios.xlsx | columna | 0 | nombre del distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 13 | Nombre de estación | tabla,columna comentarios.xlsx | columna | 0 | nombre del distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 14 | Nombre del distrito administrativo [compuesto] | tabla,columna comentarios.xlsx | columna | 0 | nombre del distrito administrativo | DB1 | PROPIETARIO1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
- Columna "Texto": Este es el valor original extraído de los datos de entrada, y en este ejemplo, corresponde a la tabla, comentario de columna.
- Columna “Palabra”: Candidatos de palabra extraídos de Texto usando Mecab. Para palabras compuestas, especifique "[palabra compuesta]" como sufijo.
- Línea 12 “distrito de administración”, línea 13 “nombre de la estación” son palabras extraídas de “nombre de la administración” en Mecab.
- Se puede ver que la precisión no es 100% porque se extrae de forma diferente a la palabra realmente utilizada.
▼ Ejemplo de hoja de “Frecuencia de palabras”
| palabra | frecuencia | Fuente |
| código | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (código de zona administrativa) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (cambiar código de identificación) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CPRVN_CODE (código de intento) … |
| número | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(número de serie del trabajo) DB1.OWNER1.COMTCZIP.ZIP (código postal) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (número de aprobación) … |
| número de personas | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (nombre de la libreta de direcciones) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (nombre del código de clasificación) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (nombre de código) … |
| Día | 85 | DB1.OWNER1.COMTCADMINISTCODE.CREAT_DE(fecha de creación) DB1.OWNER1.COMTCADMINISTCODE.ABL_DE (fecha de jubilación) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OCCRRNC_DE(fecha de ocurrencia) … |
| información | 77 | DB1.OWNER1.COMTHDBMNTRNGLOGINFO.LOG_INFO (información de registro) DB1.OWNER1.COMTNBACKUPRESULT.ERROR_INFO (información de error) DB1.OWNER1.COMTNINDVDLINFOPOLICY.INDVDL_INFO_POLICY_ID (ID de política de privacidad) … |
| Si | 75 | DB1.OWNER1.COMTCADMINISTCODE.USE_AT (si se usa) DB1.OWNER1.COMTNANNVRSRYMANAGE.REPTIT_AT (si repetir) DB1.OWNER1.COMTNBANNER.REFLCT_AT (ya sea para reflejar) … |
- Columna "Palabra": este es un valor de cadena obtenido al eliminar duplicados de la columna "Palabra" de la hoja "Resultado de extracción de palabras". Este valor es candidato a ser registrado como palabra estándar.
- Columna “Freq”: Este es el conteo de frecuencia que indica cuántas veces se usó la palabra. La lista resultante se ordena en orden inverso desde estas palabras de alta frecuencia a las de baja frecuencia.
- Columna “Fuente”: Indica la fuente de la palabra. Muestra hasta 10 fuentes.
- Si la fuente es Tabla, el formato es: DB.Schema.TableName(Comentario de tabla)
- Si el origen es Columna, el formato es: DB.Schema.TableName.ColumnName(Column comment)
- Si la fuente es Formato de archivo: Nombre de archivo: Número de página: Texto
A continuación se muestra un ejemplo de una imagen de nube de palabras generada por la frecuencia de las palabras extraídas. Las palabras con alta frecuencia se muestran en tamaño grande.

La herramienta de extracción de palabras es una herramienta desarrollada en Python y requiere un proceso de configuración del entorno, como la instalación de Python y los paquetes necesarios antes de la ejecución. A continuación, veremos el proceso de configuración del entorno.
<< Lista de artículos relacionados >>
- Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
- Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
- Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
- Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
- Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
- Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
- Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
Artículos relacionados:
 Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
 Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
 Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
 Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
 Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
 Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
 Optimización de la distribución del trabajo utilizando un algoritmo de empaque de contenedores unidimensional_4.Adjunto
Optimización de la distribución del trabajo utilizando un algoritmo de empaque de contenedores unidimensional_4.Adjunto
 Optimización de la distribución del trabajo mediante el algoritmo bin packing unidimensional_3.Implementación (2)
Optimización de la distribución del trabajo mediante el algoritmo bin packing unidimensional_3.Implementación (2)









