Conversión de juego de caracteres de Oracle (3): 3. Configuración del entorno del cliente (2)
Continuando con el artículo anterior, analizamos la configuración del entorno del cliente de conversión de Oracle Character Set. Se pueden verificar cuatro configuraciones recomendadas de Oracle Server Character Set y Client NLS_LANG.
3.2. Resumen de los resultados de ejecución del caso de prueba
Publicación anterior Conversión del juego de caracteres de Oracle (2): 3. Configuración del entorno del cliente (1)Los resultados de ejecución de cada caso de prueba se resumen a continuación.
| Caso # | Servidor Conjunto de caracteres | Cliente NLS_LANG | valor | aporte | Imprimir | VERTEDERO valor |
|---|---|---|---|---|---|---|
| 1 | US7ASCII | KO16KSC5601 | 'hangul' | éxito | fractura | Tipo = 1 Longitud = 2 Conjunto de caracteres = US7ASCII: 3f, 3f |
| 'Afilado' | falla | - | - | |||
| 2 | US7ASCII | KO16MSWIN949 | 'hangul' | éxito | fractura | Tipo = 1 Longitud = 2 Conjunto de caracteres = US7ASCII: 3f, 3f |
| 'Afilado' | éxito | fractura | Tipo=1 Longitud=1 Juego de caracteres=US7ASCII: 3f | |||
| 3 | US7ASCII | US7ASCII | 'hangul' | éxito | normal | Tipo=1 Longitud=4 Juego de caracteres=US7ASCII: c7,d1,b1,db |
| 'Afilado' | éxito | normal | Tipo=1 Longitud=2 Juego de caracteres=US7ASCII: 98,de | |||
| 4 | KO16MSWIN949 | KO16KSC5601 | 'hangul' | éxito | normal | Tipo = 1 Len = 4 Conjunto de caracteres = KO16MSWIN949: c7, d1, b1, db |
| 'Afilado' | falla | - | - | |||
| 5 | KO16MSWIN949 | KO16MSWIN949 | 'hangul' | éxito | normal | Tipo = 1 Len = 4 Conjunto de caracteres = KO16MSWIN949: c7, d1, b1, db |
| 'Afilado' | éxito | normal | Typ=1 Len=2 CharacterSet=KO16MSWIN949: 98,de | |||
| 6 | KO16MSWIN949 | US7ASCII | 'hangul' | éxito | fractura | Tipo = 1 Longitud = 4 Juego de caracteres = KO16MSWIN949: 3f, 3f, 3f, 3f |
| 'Afilado' | éxito | fractura | Tipo = 1 Len = 2 Conjunto de caracteres = KO16MSWIN949: 3f, 3f | |||
| 7 | AL32UTF8 | KO16KSC5601 | 'hangul' | éxito | normal | Tipo=1 Longitud=6 Conjunto de caracteres=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'Afilado' | falla | - | - | |||
| 8 | AL32UTF8 | KO16MSWIN949 | 'hangul' | éxito | normal | Tipo=1 Longitud=6 Conjunto de caracteres=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'Afilado' | éxito | normal | Tipo=1 Longitud=3 Conjunto de caracteres=AL32UTF8: ec,83,be | |||
| 9-1 | AL32UTF8 | AL32UTF8 (comando) | 'hangul' | falla | - | - |
| 'Afilado' | falla | - | - | |||
| 9-2 | AL32UTF8 | AL32UTF8 (Potencia Shell) | 'hangul' | éxito | normal | Tipo=1 Longitud=6 Conjunto de caracteres=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'Afilado' | éxito | normal | Tipo=1 Longitud=3 Conjunto de caracteres=AL32UTF8: ec,83,be |
3.3 Conjunto de caracteres del servidor Oracle y configuración recomendada del cliente NLS_LANG
La configuración del entorno Oracle Server and Client para entrada/salida Hangul es posible en las siguientes cuatro combinaciones.
| Caso # | Servidor Conjunto de caracteres | Cliente NLS_LANG | Comentario |
| 3 | US7ASCII | US7ASCII | nunca lo uses ¡Utilícelo solo si no puede cambiar el entorno existente! |
| 5 | KO16MSWIN949 | KO16MSWIN949 | Almacena e ingresa y emite solo caracteres coreanos, caracteres ingleses, números, caracteres especiales, caracteres chinos, etc. compatibles con Windows coreano (los caracteres multilingües no se pueden almacenar en el servidor) |
| 8 | AL32UTF8 | KO16MSWIN949 | Se usa cuando el servidor es un entorno multilingüe y el cliente ingresa y emite solo coreano. Se puede usar cuando la aplicación cliente no puede manejar Unicode |
| 9 | AL32UTF8 | AL32UTF8 | El valor almacenado en el servidor se transmite al cliente tal como está sin conversión. Es decir, el cliente debe manejar directamente los datos codificados en UTF8. |
El caso #3 parece no tener problemas con la entrada/salida, pero mirando el valor de volcado, puede ver que el conjunto de caracteres es US7ASCII. Es decir, significa que la entrada/salida real se ejecuta en unidades de 1 byte de US7ASCII y se almacena incorrectamente.
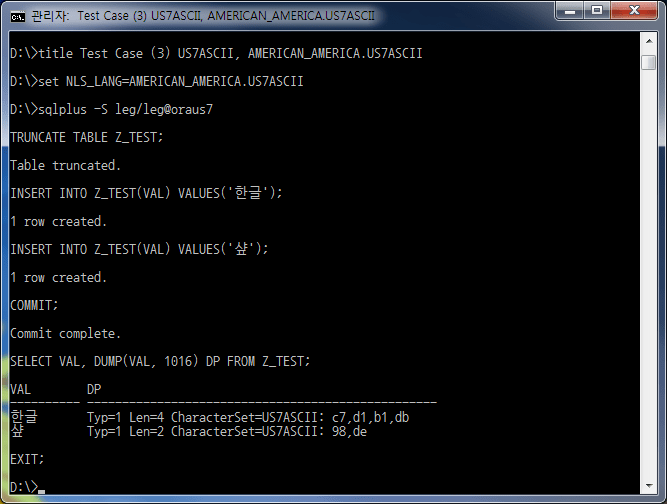
Cuando estos datos se transmiten a un sistema externo a través de EAI, ETL, ESB, etc., los caracteres Hangul se rompen y es difícil intercambiar datos con precisión. Por lo tanto, el caso #3 es una configuración que debe evitarse por completo.
El caso 9-1 es un fenómeno que ocurre porque la entrada/salida Unicode no es compatible con cmd.exe, un símbolo del sistema de Windows, aunque la configuración original de entrada/salida no presenta ningún problema.
Si marca el Caso 9-2 en Windows PowerShell, puede ver que la entrada/salida es normal.
Para almacenar caracteres multilingües como caracteres chinos, japoneses, tailandeses y de Europa occidental además del coreano, son posibles las dos combinaciones siguientes.
| Caso # | Servidor Conjunto de caracteres | Cliente NLS_LANG | Comentario |
| 8 | AL32UTF8 | Establecer de acuerdo con cada carácter de idioma | Configuración del cliente NLS_LANG – En caso de coreano: KO16MSWIN949 – Caracteres chinos: ZHS16GBK o ZHT16MSWIN950 o ZHT16HKSCS – Caracteres japoneses: JA16SJIS – Caracteres tailandeses: TH8TISASCII, etc. Vea la tabla de abajo |
| 9 | AL32UTF8 | AL32UTF8 | El valor almacenado en el servidor se transmite al cliente tal como está sin conversión. Es decir, el cliente debe manejar directamente los datos codificados en UTF8. |
La lista de valores de Client NLS_LANG mencionados anteriormente <establecidos según cada carácter de idioma> es la siguiente.
| Configuración regional del sistema operativo | Valor NLS_LANG |
| Árabe (EAU) | ARABIC_EMIRATOS ÁRABES UNIDOS.AR8MSWIN1256 |
| búlgaro | BULGARIO_BULKARIA.CL8MSWIN1251 |
| catalán | CATALÁN_CATALUÑA.WE8MSWIN1252 |
| chino (RPC) | CHINO SIMPLIFICADO_CHINA.ZHS16GBK |
| chino (Taiwán) | CHINO TRADICIONAL_TAIWAN.ZHT16MSWIN950 |
| Chino (HKCS de Hong Kong) | CHINO TRADICIONAL_HONG KONG.ZHT16HKSCS |
| Chino (Hong Kong HKCS2001) | CHINO TRADICIONAL_HONG KONG.ZHT16HKSCS2001 (nuevo en 10gR1) |
| croata | CROATA_CROACIA.EE8MSWIN1250 |
| checo | CHECA_REPÚBLICA CHECA.EE8MSWIN1250 |
| danés | DANÉS_DINAMARCA.WE8MSWIN1252 |
| Holandés (Países Bajos) | HOLANDÉS_PAÍSES BAJOS.WE8MSWIN1252 |
| Holandés (Bélgica) | HOLANDÉS_BÉLGICA.WE8MSWIN1252 |
| Inglés reino unido) | INGLÉS_REINO UNIDO.WE8MSWIN1252 |
| Inglés Estados Unidos) | AMERICAN_AMERICA.WE8MSWIN1252 |
| estonio | ESTONIO_ESTONIA.BLT8MSWIN1257 |
| finlandés | FINLANDÉS_FINLANDIA.WE8MSWIN1252 |
| Francés (Canadá) | FRANCÉS CANADIENSE_CANADÁ.WE8MSWIN1252 |
| Francés Francia) | FRANCÉS_FRANCIA.WE8MSWIN1252 |
| Alemán Alemania) | ALEMÁN_ALEMANIA.WE8MSWIN1252 |
| Griego | GRIEGO_GRECIA.EL8MSWIN1253 |
| hebreo | HEBREO_ISRAEL.IW8MSWIN1255 |
| húngaro | HUNGARIAN_HUNGARY.EE8MSWIN1250 |
| islandés | ISLANDIA_ISLANDIA.WE8MSWIN1252 |
| indonesio | INDONESIA_INDONESIA.WE8MSWIN1252 |
| italiano (Italia) | ITALIANO_ITALIA.WE8MSWIN1252 |
| japonés | JAPONÉS_JAPON.JA16SJIS |
| coreano | KOREAN_COREA.KO16MSWIN949 |
| letón | LETONIA_LETONIA.BLT8MSWIN1257 |
| lituano | LITUANO_LITUANIA.BLT8MSWIN1257 |
| noruego | NORUEGO_NORUEGA.WE8MSWIN1252 |
| Polaco | POLACO_POLONIA.EE8MSWIN1250 |
| Portugués (Brasil) | PORTUGUÉS BRASILEÑO_BRAZIL.WE8MSWIN1252 |
| Portugués (Portugal) | PORTUGUÉS_PORTUGAL.WE8MSWIN1252 |
| rumano | RUMANO_RUMANÍA.EE8MSWIN1250 |
| ruso | RUSSIAN_CIS.CL8MSWIN1251 |
| eslovaco | ESLOVAQUIA_ESLOVAQUIA.EE8MSWIN1250 |
| Español (España) | ESPAÑOL_ESPAÑA.WE8MSWIN1252 |
| sueco | SUECO_SUECIA.WE8MSWIN1252 |
| tailandés | THAI_TAILANDIA.TH8TISASCII |
| Español (México) | ESPAÑOL MEXICANO_MEXICO.WE8MSWIN1252 |
| Español (Venezuela) | ESPAÑOL LATINOAMERICANO_VENEZUELA.WE8MSWIN1252 |
| turco | TURQUÍA_TURQUÍA.TR8MSWIN1254 |
| ucranio | UCRANIANO_UCRANIA.CL8MSWIN1251 |
| vietnamita | VIETNAMITA_VIETNAM.VN8MSWIN1258 |
*fuente: Preguntas frecuentes sobre NLS_LANG (oracle.com) del documento detalle
Aquí puede surgir una pregunta.
El conjunto de caracteres del servidor se designa como AL32UTF8, un sistema Unicode, pero ¿por qué el cliente NLS_LANG debe especificar KO16MSWIN949, un sistema de 2 bytes?
Esto se debe a que el sistema operativo Windows es el método básico para codificar/decodificar Hangul. (Como referencia, es común usar KO16KSC5601 cuando se ingresan y emiten caracteres coreanos en UNiX). Para mencionarlo nuevamente, el Conjunto de caracteres del servidor es una configuración para "almacenar" datos de cadenas de caracteres, y el Cliente NLS_LANG "muestra" datos de cadenas de caracteres. Es un escenario para “Transmisión”.
El conjunto de caracteres del servidor especifica AL32UTF8, un sistema Unicode, para "almacenar" caracteres de varios países, y el sistema básico de codificación/descodificación admitido por Windows para cada idioma se usa en el entorno del cliente (principalmente Windows) de varios países que se conecta a este servidor para especificar Los datos ingresados en Non-Unicode se convierten a Unicode y se guardan mientras se transmiten al servidor a través del cliente de Oracle y SQL*Net.
Cuando el conjunto de caracteres del servidor es AL32UTF8, si el cliente NLS_LANG está configurado en AL32UTF8, el valor Unicode almacenado en el servidor se transmite al cliente sin ningún proceso de conversión. En otras palabras, si el cliente NLS_LANG debe establecerse en AL32UTF8, el cliente debe poder codificar/decodificar Unicode.
Como referencia, entre las herramientas proporcionadas de forma gratuita, ORACLE SQL Developer es una herramienta representativa que admite bien Unicode. DBeaver también admite Unicode bien basado en jdbc.
Si cree que la selección del conjunto de caracteres es difícil porque los contenidos hasta ahora son complicados, solo necesita recordar los siguientes contenidos.
- Conjunto de caracteres del servidor establecido en AL32UTF8
- Cliente NLS_LANG
- Si el cliente no puede manejar Unicode o está limitado a un idioma específico, establezca el valor correspondiente al idioma
- AL32UTF8 si el cliente puede manejar Unicode
Hasta ahora, hemos analizado la configuración del entorno del cliente relacionada con el juego de caracteres de Oracle.
En el siguiente artículo, veremos cómo convertir el conjunto de caracteres en un entorno no válido donde el conjunto de caracteres del servidor es US7ASCII y se almacenan caracteres coreanos.
Artículos relacionados:
 Conversión de juegos de caracteres de Oracle (9): 6. Cómo convertir juegos de caracteres implementados por el usuario (2)
Conversión de juegos de caracteres de Oracle (9): 6. Cómo convertir juegos de caracteres implementados por el usuario (2)
 Conversión de conjuntos de caracteres de Oracle(8): 6. Cómo convertir un conjunto de caracteres implementado por el usuario (1)
Conversión de conjuntos de caracteres de Oracle(8): 6. Cómo convertir un conjunto de caracteres implementado por el usuario (1)
 Conversión de juego de caracteres de Oracle (7): 5.4. KO16MSWIN949 Entorno CSSCAN Resultado de ejecución
Conversión de juego de caracteres de Oracle (7): 5.4. KO16MSWIN949 Entorno CSSCAN Resultado de ejecución
 Conversión de juego de caracteres de Oracle (6): 5.3. Resultado de la ejecución de CSSCAN del entorno US7ASCII
Conversión de juego de caracteres de Oracle (6): 5.3. Resultado de la ejecución de CSSCAN del entorno US7ASCII
 Conversión de juegos de caracteres de Oracle (5): 5. Práctica recomendada de Oracle
Conversión de juegos de caracteres de Oracle (5): 5. Práctica recomendada de Oracle
 Conversión de juegos de caracteres de Oracle (4): 4.Configuración del entorno de prueba
Conversión de juegos de caracteres de Oracle (4): 4.Configuración del entorno de prueba
 Conversión del juego de caracteres de Oracle (2): 3. Configuración del entorno del cliente (1)
Conversión del juego de caracteres de Oracle (2): 3. Configuración del entorno del cliente (1)
 Conversión de juego de caracteres de Oracle(1): 1. Necesidad, guía de configuración correcta del juego de caracteres de Oracle
Conversión de juego de caracteres de Oracle(1): 1. Necesidad, guía de configuración correcta del juego de caracteres de Oracle









