Lanzamiento de la herramienta de extracción de palabras v0.41: agregue la frecuencia de aparición de DBSchema del elemento de palabras
* Consulte también la versión v0.42 recientemente lanzada para corregir errores.
Lanzamiento de Word Extractor v0.42: corrección de errores: habilidad de productividad (prodskill.com)
Distribuya después de complementar la función para agregar y extraer elementos de frecuencia de ocurrencia de DBSchema de palabras de la herramienta de extracción de palabras previamente distribuida (v0.40). El elemento DBSchema_Freq informa cuántos DB-Schemas se distribuye la fuente de la palabra.
Referencia: Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras

fuente: https://stocksnap.io/photo/dictionary-page-ELRF6CYOHI
1. Cambios en los resultados de la herramienta de extracción de palabras
Un ejemplo del resultado de la extracción de palabras de la herramienta distribuida anteriormente es el siguiente.
▼ Ejemplo de hoja de "Frecuencia de palabras" antes del cambio (v0.40)
| palabra | frecuencia | Fuente |
| código | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (código de zona administrativa) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (cambiar código de identificación) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CPRVN_CODE (código de intento) … |
| número | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(número de serie del trabajo) DB1.OWNER1.COMTCZIP.ZIP (código postal) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (número de aprobación) … |
| número de personas | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (nombre de la libreta de direcciones) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (nombre del código de clasificación) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (nombre de código) … |
Los elementos DBSchema_Freq se agregan a los resultados extraídos de v0.41 de la siguiente manera.
▼ Ejemplo de hoja de "Frecuencia de palabras" después del cambio (v0.41)
| palabra | frecuencia | Fuente | DBSchema_Freq |
| código | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (código de zona administrativa) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (cambiar código de identificación) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CPRVN_CODE (código de intento) … | 10 |
| número | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(número de serie del trabajo) DB1.OWNER1.COMTCZIP.ZIP (código postal) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (número de aprobación) … | 9 |
| número de personas | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (nombre de la libreta de direcciones) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (nombre del código de clasificación) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (nombre de código) … | 5 |
El elemento DBSchema_Freq informa cuántos DB-Schemas se distribuye la fuente de la palabra. La información necesaria para seleccionar candidatos de palabras estándar se puede proporcionar con un poco más de detalle.
- Cuando la frecuencia (Freq) es alta pero la frecuencia DBSchema (DBSchema_Freq) es baja
- La palabra aparece de forma intensiva solo en un DB-Schema específico
- Cuando tanto la frecuencia (Freq) como la frecuencia DBSchema (DBSchema_Freq) son altas
- La palabra se distribuye uniformemente en todo el DB-Schema
- Cuando la frecuencia (Freq) es baja pero la frecuencia DBSchema (DBSchema_Freq) es relativamente alta
- La palabra se revisa para su inclusión en lugar de su exclusión en los candidatos a palabras canónicas.
2. Cambios en el código fuente
Hay cambios en tres funciones.
2.1. Cambió la función get_db_comment_text
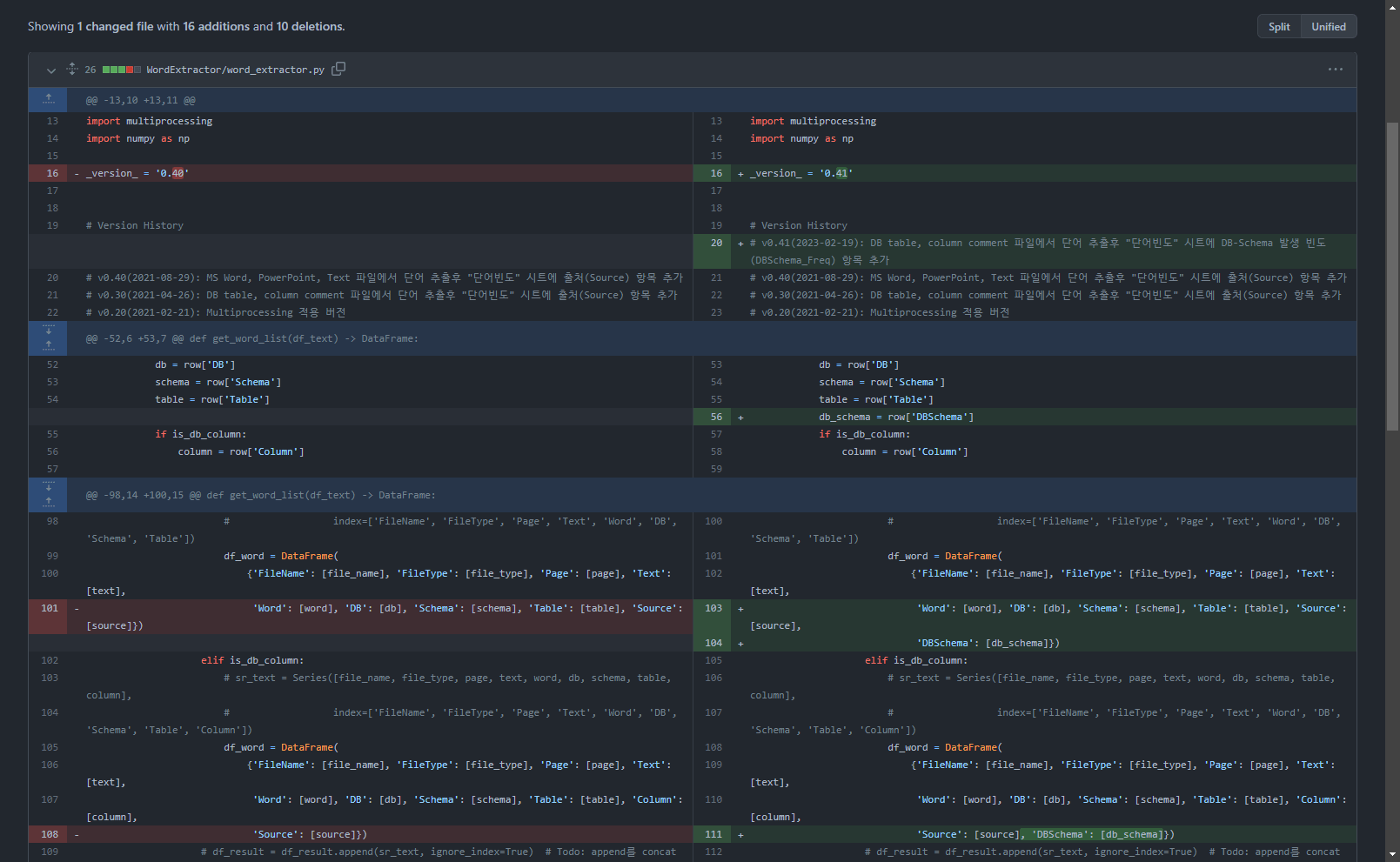
Agregue la línea 343: cree una columna DBSchema en la variable del marco de datos df_text que contenga el resultado de la extracción de texto y cree un valor.
df_text['DBSchema'] = df_text['DB'] + '.' + df_text['Schema'] # DB.Schema 값 생성(2023-02-19)
2.2. Cambiar la función get_word_list
Agregue la línea 104, 111: agregue el valor DBSchema al marco de datos de resultados de extracción de palabras
if len(words) >= 1:
# print(nouns, text)
for word in words:
# print(noun, '\t', text)
if not is_db:
# sr_text = Series([file_name, file_type, page, text, word],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'Source': [source]})
elif is_db_table:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Source': [source],
'DBSchema': [db_schema]})
elif is_db_column:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table, column],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table', 'Column'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Column': [column],
'Source': [source], 'DBSchema': [db_schema]})
2.3. cambiar la función principal
2.3.1. Contenido de la función principal antes del cambio
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
2.3.2. Contenido de la función principal después del cambio
df_group = df_result.groupby('Word').agg({
'Word': 'count',
'Source': lambda x: '\n'.join(list(x)[:10]),
'DBSchema': 'nunique'
}).rename(columns={
'Word': 'Freq',
'Source': 'Source',
'DBSchema': 'DBSchema_Freq'
})
Este código agrupa word (palabra) en df_result, que es una variable de marco de datos como resultado de la extracción de palabras (groupby), obtiene el número (núnico) de valores DBSchema con los duplicados eliminados y nombra el elemento como DBSchema_Freq.
Como referencia, este código es el código de prueba que escribí. ChatGPTEste es el código que se le entregó y solicitó para su simplificación. Antes de la simplificación, era un código complejo que se dividía en dos marcos de datos, aplicaba lambda y nunique a cada uno y luego los fusionaba de nuevo en uno. recientemente ChatGPT admirando la habilidad
2.4. Los detalles completos del código fuente cambiaron en v0.41
Puede consultar los detalles de los cambios en el enlace de github a continuación.
3. Descargue y ejecute la Herramienta de extracción de Word (v0.41)
Puede consultar el archivo word_extractor.py modificado en el siguiente enlace.
ToolsForDataStandard/word_extractor.py en el principal DAToolset/ToolsForDataStandard (github.com)
El método de ejecución es el mismo que en v0.40. Consulte la información a continuación.
La herramienta de extracción de palabras v0.41 no está bien probada y puede introducir errores o fallas. Por favor, deje cualquier error, error, consulta, etc. en los comentarios.
Artículos relacionados:
 Lanzamiento de Word Extraction Tool v0.42: Corrección de errores
Lanzamiento de Word Extraction Tool v0.42: Corrección de errores
 Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
Tabla de contenido completa del descriptor de la herramienta de extracción de palabras, descarga
 Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
Herramienta de extracción de palabras (6): Herramienta de extracción de palabras Descripción adicional
 Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
Herramienta de extracción de palabras (5): Descripción del código fuente de la herramienta de extracción de palabras (2)
 Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
Herramienta de extracción de palabras (4): Descripción del código fuente de la herramienta de extracción de palabras (1)
 Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
Herramienta de extracción de Word (3): cómo ejecutar la herramienta de extracción de Word y verificar los resultados
 Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
Herramienta de extracción de Word (2): configuración del entorno de ejecución de la herramienta de extracción de Word
 Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras
Herramienta de extracción de palabras (1): descripción general de la herramienta de extracción de palabras










¡hola!
Cuando se utiliza el método de extracción de palabras de un archivo sin un comentario DB, que es uno de los tres métodos de ejecución
(python word_extractor.py –in_path .\in –out_path .\out)
txt, palabra, ppt todo
miniconda3\envs\wordextr\lib\site-packages\pandas\core\apply.py”, línea 601, en normalize_dictlike_arg raise KeyError(f”La(s) columna(s) {cols_sorted} no existen”)
KeyError: "La(s) columna(s) ['DBSchema'] no existen"
Está saliendo con un error.
Los métodos de ejecución 2 y 3, donde se ingresa el archivo de comentarios de la base de datos, funcionan sin errores.
Puse 'DBSchema': [db_schema] en la línea 97, pero esta vez
En get_grouper, aumente KeyError (gpr) KeyError: se muestra el error 'Word'.
gracias
Gracias por informar el error.
Desplegó sin probar el caso de extraer palabras solo de Archivo.
Volveremos a lanzar una versión probada y corregida pronto.
V0.42 relanzado con correcciones de errores.
https://prodskill.com/ko/word-extractor-v0-42-bug-fix-for-dbschema/
gracias