4. Caso de procesamiento paralelo del método de partición SQL definido por el usuario (DBMS_PARALLEL_EXECUTE)
Echemos un vistazo al caso del paralelismo de partición de SQL definido por el usuario usando Oracle DBMS_PARALLEL_EXECUTE. Abarca la escritura de SQL definido por el usuario, el entorno de prueba, la creación de trabajos, la división de trabajos, la ejecución de trabajos, la confirmación y eliminación de la finalización de trabajos.
Esta es una continuación del artículo anterior.
3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
* Documentación de Oracle de referencia: Procedimiento DBMS_PARALLEL_EXECUTE – CREATE_CHUNKS_BY_SQL (oracle.com)
4. Caso de procesamiento paralelo de partición SQL definido por el usuario
4.1. Descripción general de los métodos de partición de SQL personalizados
La partición a través de SQL definido por el usuario es útil en los siguientes casos.
- Particionamiento en casos en los que el método de particionamiento ROWID no es compatible (por ejemplo, particionamiento ROWID para tablas remotas a través de DB Link)
- División basada en columnas que no sean la columna NÚMERO (VARCHAR2, FECHA, etc.)
Aquí, explicaremos el caso de la división ROWID a través de DB Link en el primer caso.
Si intenta dividir el ROWID de una tabla a través de DB Link usando CREATE_CHUNKS_BY_ROWID, Se produce un error.
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)');
END;
/
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE
.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)',
TABLE_OWNER => USER,
-- TABLE _NAME을 “T1@DL_MS949”로 DB Link 지정
TABLE_NAME => 'T1@DL_MS949',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
--> 실행 오류 메시지
ORA-29491: 조각에 부적합한 테이블
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 27행
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 121행
ORA-06512: 4행
En este caso, el SQL que divide el ROWID de la tabla en el DB Link se puede crear y aplicar a través de CREATE_CHUNKS_BY_SQL.
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL ( task_name IN VARCHAR2, sql_stmt IN CLOB, by_rowid IN BOOLEAN);
sql_stmt es un tipo CLOB y se puede usar casi sin restricciones en su longitud, pero aquí sugerimos una forma de usar una función lineal en lugar de describir SQL directamente.
4.2. Escribir SQL personalizado
Cree un tipo definido por el usuario y cree una función canalizada que devuelva un conjunto de resultados de este tipo de la siguiente manera.
-- 1. TYPE 생성 (Pipe-Lined function에서 return하기 위함)
CREATE OR REPLACE TYPE TP_ROWID_RANGE AS OBJECT (
START_ROWID VARCHAR2(50)
,END_ROWID VARCHAR2(50)
);
CREATE OR REPLACE TYPE TL_ROWID_RANGE AS TABLE OF TP_ROWID_RANGE;
-- 2. Function 생성
CREATE OR REPLACE FUNCTION FN_SPLIT_BY_ROWID(
I_OWNER IN VARCHAR2, I_TABLE_NAME IN VARCHAR2, I_CHUNKS IN NUMBER)
RETURN TL_ROWID_RANGE
PIPELINED
AS
CURSOR C_ROWID_RANGE (CP_OWNER VARCHAR2, CP_TABLE_NAME VARCHAR2, CP_CHUNKS NUMBER)
IS
SELECT GRP,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, LO_FNO, LO_BLOCK, 0 ) MIN_RID,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, HI_FNO, HI_BLOCK, 10000 ) MAX_RID
FROM (
SELECT DISTINCT GRP,
FIRST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_FNO,
FIRST_VALUE(BLOCK_ID)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_BLOCK,
LAST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_FNO,
LAST_VALUE(BLOCK_ID+BLOCKS-1)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_BLOCK,
SUM(BLOCKS) OVER (PARTITION BY GRP) SUM_BLOCKS
FROM (
SELECT RELATIVE_FNO, BLOCK_ID, BLOCKS,
TRUNC( (SUM(BLOCKS) OVER (ORDER BY RELATIVE_FNO, BLOCK_ID)-0.01) /
(SUM(BLOCKS) OVER ()/ CP_CHUNKS) ) GRP
FROM DBA_EXTENTS@DL_MS949
WHERE SEGMENT_NAME = UPPER(CP_TABLE_NAME)
AND OWNER = UPPER(CP_OWNER)
ORDER BY BLOCK_ID
)
),
(SELECT DATA_OBJECT_ID
FROM DBA_OBJECTS@DL_MS949
WHERE OWNER = UPPER(CP_OWNER)
AND OBJECT_NAME = UPPER(CP_TABLE_NAME))
ORDER BY GRP
;
BEGIN
FOR ROWID_RANGE IN C_ROWID_RANGE(I_OWNER, I_TABLE_NAME, I_CHUNKS) LOOP
PIPE ROW(TP_ROWID_RANGE(ROWID_RANGE.MIN_RID, ROWID_RANGE.MAX_RID));
END LOOP;
RETURN;
END;
/
El SQL utilizado en la función anterior es la división ROWID en unidades de bloque basada en DBA_EXTENTS, y se modificó ligeramente para usar DB Link al referirse a la técnica sugerida por Thomas Kyte.
* URL de referencia: https://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:10498431232211
DB Link se usó especificando DL_MS 949. Si también desea designar dinámicamente DB Link, puede cambiar el cursor SQL de la función anterior a SQL dinámico y usarlo.
Si la tabla LEG.SUB_MON_STAT (número total de 7426) se particiona mediante ROWID mediante esta función, es como se indica a continuación.
-- DL_MS949 DB Link상의 LEG owner, SUB_MON_STAT table에 대해 4개의 Chunk로 ROWID 분할
SELECT ROWNUM RNO, START_ROWID, END_ROWID
FROM TABLE(FN_SPLIT_BY_ROWID('LEG', 'SUB_MON_STAT', 4))
;
| Fila# | START_ROWID | END_ROWID |
| 1 | AAAQXFAAEAAAACIAAA | AAAQXFAAEAAAAC3CcQ |
| 2 | AAAQXFAAEAAAAC4AAA | AAAQXFAAAEAAAADHCcQ |
| 3 | AAAQXFAAAEAAAADIAAA | AAAQXFAAAEAAAADXCcQ |
| 4 | AAAQXFAAEAAAADYAAA | AAAQXFAAAEAAAADnCcQ |
Al dividir datos con el ROWID generado aquí, verifique si hay alguna omisión en todos los datos con el SQL a continuación.
SELECT R.RNO, COUNT(*) CNT
FROM SUB_MON_STAT S
,(
SELECT 1 RNO, 'AAAQXFAAEAAAACIAAA' START_ROWID, 'AAAQXFAAEAAAAC3CcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 2 RNO, 'AAAQXFAAEAAAAC4AAA' START_ROWID, 'AAAQXFAAEAAAADHCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 3 RNO, 'AAAQXFAAEAAAADIAAA' START_ROWID, 'AAAQXFAAEAAAADXCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 4 RNO, 'AAAQXFAAEAAAADYAAA' START_ROWID, 'AAAQXFAAEAAAADnCcQ' END_ROWID FROM DUAL
) R
WHERE S.ROWID BETWEEN R.START_ROWID AND END_ROWID
GROUP BY R.RNO
ORDER BY R.RNO
;
El resultado de la ejecución es el siguiente. (CNT puede variar para cada entorno de prueba).
| RNO (fragmento no) | CNT |
| 1 | 1,790 |
| 2 | 2,206 |
| 3 | 2,209 |
| 4 | 1,221 |
La suma de CNT es 7426, que es igual al número total de filas de la tabla, lo que confirma que no hay omisión. Aquí, el número de filas divididas en cada RNO es 1790, 2206, 2209 y 1221, respectivamente, que no son iguales. Esta es la misma razón por la que no se realiza una partición equitativa como se describe en el método de partición ROWID.
4.3. Crear entorno de prueba y tabla de prueba
Base de datos de destino a
- Base de datos de origen utilizando DB Link de mesa Suponiendo que se haya importado un escenario de prueba en , continúe con la siguiente configuración del entorno.
- Cuando la tabla de destino es una tabla particionada y el DML es un INSERT
- Al particionar por el número de particiones y procesar datos en unidades de claves de partición, se espera que sea posible la E/S de ruta directa. (No lo he probado, pero parece posible)
- Necesita usar /*+ APPEND */ sugerencia en la sintaxis INSERT y establecer la partición en NOLOGGING
- Si la tabla de destino es una tabla sin particiones
- La E/S de ruta directa no es posible y solo es posible la E/S convencional
- Dado que la cantidad de UNDO puede ser bastante grande, es necesario asegurar espacio de almacenamiento gratuito con anticipación.
- Si establece el tamaño del fragmento en un tamaño pequeño, podrá limitar el tamaño de UNDO hasta cierto punto.
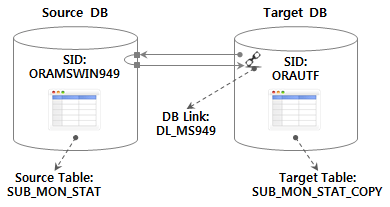
Base de datos de destino La tabla se crea de antemano con el siguiente DDL.
CREATE TABLE SUB_MON_STAT_COPY AS SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM, RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT FROM SUB_MON_STAT@DL_MS949 WHERE 1=2;
4.4. crear trabajo
4.4.1. crear trabajo
-- 1단계: 작업생성 BEGIN DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; / -- 작업 생성 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
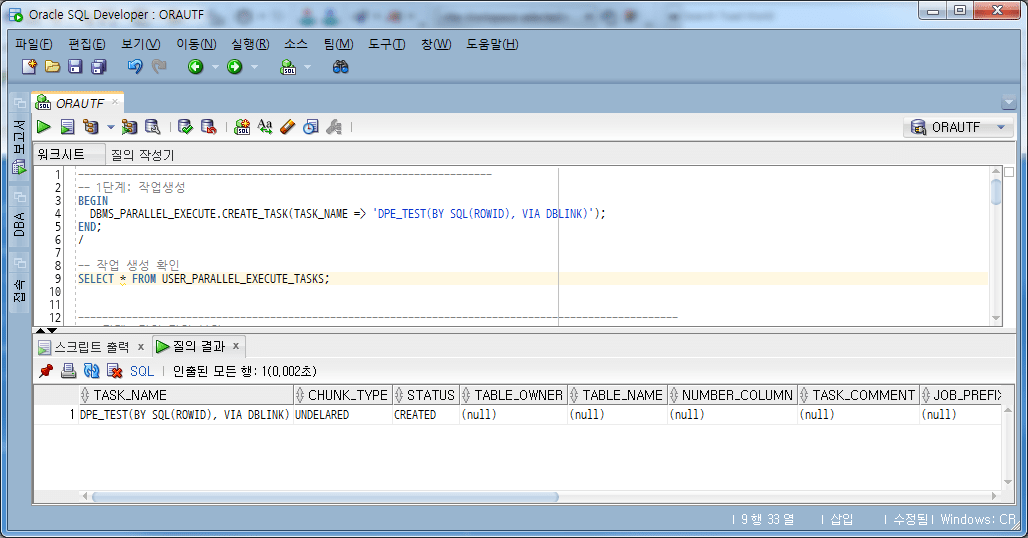
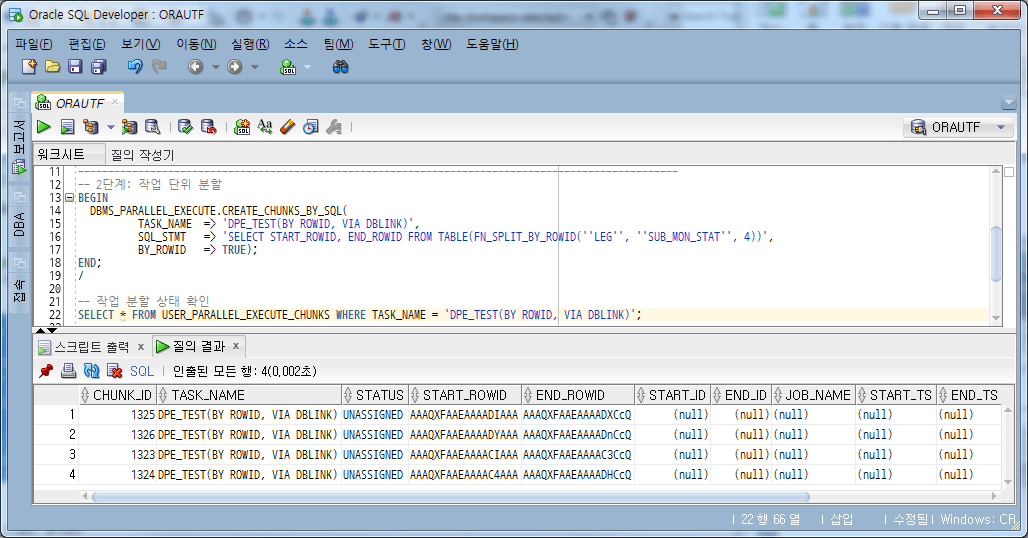
4.4.2. unidad de trabajo dividida
Usando la función FN_SPLIT_BY_ROWID, designe/divida la unidad de trabajo en 4.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(
TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => 'SELECT START_ROWID, END_ROWID FROM TABLE(FN_SPLIT_BY_ROWID(''LEG'', ''SUB_MON_STAT'', 4))',
BY_ROWID => TRUE);
END;
/
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
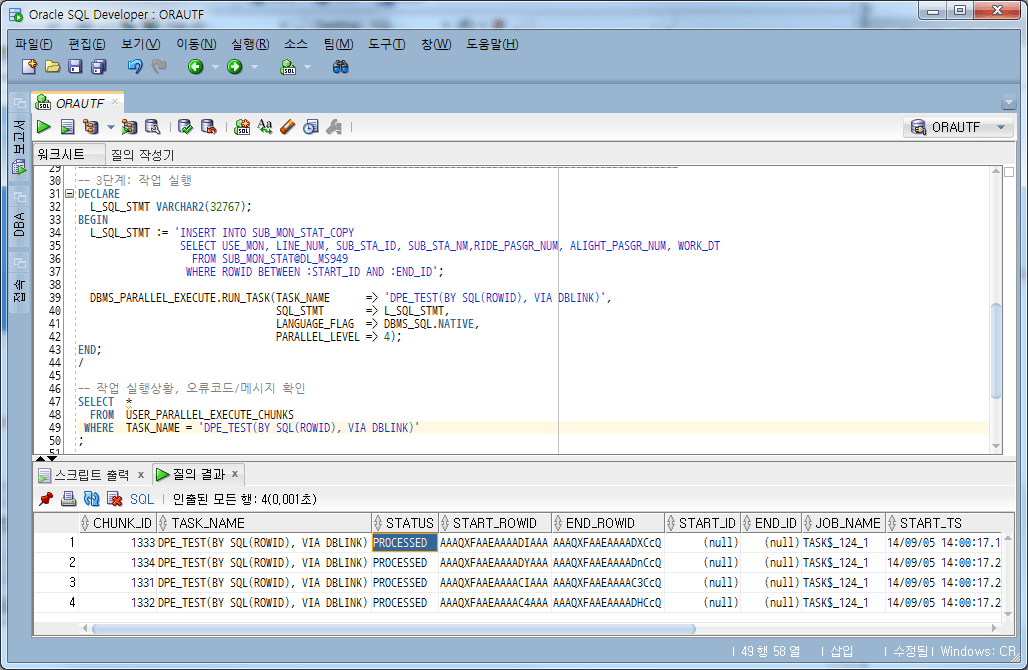
4.5. ejecución de trabajo
Ejecute la tarea especificando la condición ROWID en la cláusula WHERE. Aquí, el número de tareas se establece en 4, lo mismo que el número de unidades de trabajo.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'INSERT INTO SUB_MON_STAT_COPY
SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM,RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT
FROM SUB_MON_STAT@DL_MS949
WHERE ROWID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 4);
END;
/
-- 작업 실행상황, 오류코드/메시지 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
4.6. Confirmar la finalización de la tarea y eliminar
Puede verificar la finalización del trabajo con el siguiente SQL.
-- 작업 완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;

DROP_TAREA( ) para eliminar el trabajo.
-- 4단계: 작업삭제 BEGIN DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; /
5. Consideraciones
Arriba, vimos cómo usar DBMS_PARALLEL_EXECUTE. Este es un método que encontré mientras buscaba la carga paralela de tablas que contenían columnas CLOB en un proyecto hace unos años a través de DB Link. Espero haberlo explicado lo suficientemente bien para cualquiera que quiera usarlo.
Si tiene alguna pregunta, por favor déjela en los comentarios.
Artículos relacionados:
 Conversión de juego de caracteres de Oracle (7): 5.4. KO16MSWIN949 Entorno CSSCAN Resultado de ejecución
Conversión de juego de caracteres de Oracle (7): 5.4. KO16MSWIN949 Entorno CSSCAN Resultado de ejecución
 Conversión de juego de caracteres de Oracle (6): 5.3. Resultado de la ejecución de CSSCAN del entorno US7ASCII
Conversión de juego de caracteres de Oracle (6): 5.3. Resultado de la ejecución de CSSCAN del entorno US7ASCII
 Conversión de juegos de caracteres de Oracle (5): 5. Práctica recomendada de Oracle
Conversión de juegos de caracteres de Oracle (5): 5. Práctica recomendada de Oracle
 DBMS_PARALLEL_EXECUTE Descripción Tabla de contenido
DBMS_PARALLEL_EXECUTE Descripción Tabla de contenido
 3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
 2.5. Comprobación detallada de la partición de la unidad de trabajo (DBMS_PARALLEL_EXECUTE)
2.5. Comprobación detallada de la partición de la unidad de trabajo (DBMS_PARALLEL_EXECUTE)
 2. Caso de procesamiento paralelo de partición ROWID (DBMS_PARALLEL_EXECUTE)
2. Caso de procesamiento paralelo de partición ROWID (DBMS_PARALLEL_EXECUTE)
 1. Descripción general del procesamiento paralelo de trabajos DML (DBMS_PARALLEL_EXECUTE)
1. Descripción general del procesamiento paralelo de trabajos DML (DBMS_PARALLEL_EXECUTE)









