1. Descripción general del procesamiento paralelo de trabajos DML (DBMS_PARALLEL_EXECUTE)
Presenta DBMS_PARALLEL_EXECUTE, que se puede usar desde Oracle 11g R2, y examina los casos de uso.
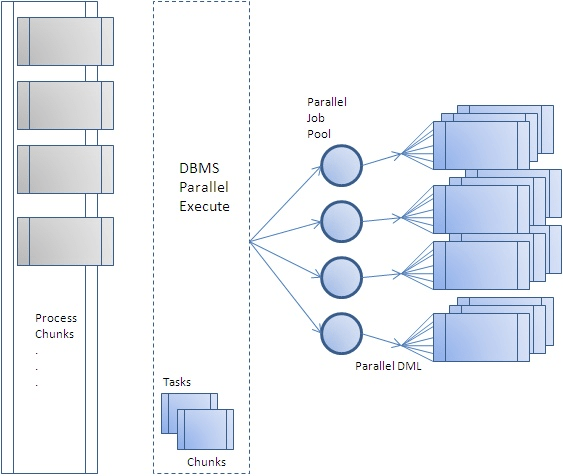
Fuente de imagen: https://blogs.oracle.com/warehousebuilder/parallel-processing-with-dbmsparallelexecute
1. Descripción general del procesamiento paralelo de tareas DML
1.1. Método de procesamiento paralelo DML
El procesamiento paralelo se usa cuando desea procesar rápidamente un trabajo DML (INSERTAR, ACTUALIZAR, ELIMINAR) en la base de datos utilizando tantos recursos como sea posible. Hay dos métodos principales de procesamiento paralelo.
El primer método es especificar el grado paralelo como una sugerencia mientras se ejecuta un SQL (DML paralelo, transacción única), y el segundo método es ejecutar múltiples SQL especificando un rango de datos (Programa DML paralelo, transacción múltiple). am .
En la mayoría de los casos, el primer método, el método DML paralelo, es ventajoso en términos de consistencia de datos porque se procesa como una sola transacción. Sin embargo, si no se puede aplicar el primer método o si desea definir usted mismo el tamaño o el alcance de la unidad de trabajo, es mejor aplicar el segundo método. (Entonces, el segundo método también se llama DIY (Do It Yourself) Parallel DML)
Los ejemplos de situaciones en las que no se puede aplicar Parallel DML son los siguientes.
- DML para SELECCIONAR una tabla que contiene columnas LOB
- DML en enlace de base de datos
- Procesamiento paralelo de DML en unidades PL/SQL en lugar de unidades SQL o unidades de procedimiento implementadas en procedimientos complejos
- DML que no está implementado en PL/SQL y se ejecuta en un lenguaje como Java
Los pasos para ejecutar Program Parallel DML serán ligeramente diferentes según la situación, pero en general son los siguientes.
- Selección de objetivo de trabajo.
- Selección de paralelismo y división de unidades de trabajo (Partición, fecha, número, ROWID, etc.) -> Creación de archivos .sql por unidades de trabajo
- Ejecución y supervisión de tareas -> Ejecutar cada archivo .sql en una sesión individual (SQL*Plus, etc.)
- Confirmar la finalización de la tarea -> Verificación de la comparación de recuento de filas, comparación de sumas, etc.
Cuando los requisitos o las situaciones cambian y es necesario cambiar el grado de paralelismo (DOP) o se requiere volver a trabajar, los pasos 2 y 3 se realizan repetidamente, y la gestión y la confirmación no son simples. Es un inconveniente tener que repetir tareas similares manualmente una y otra vez cada vez que se requiere un cambio.
1.2. Concepto DBMS_PARALLEL_EXECUTE
Al usar el método Program Parallel, el uso de DBMS_PARALLEL_EXECUTE puede ejecutar y administrar esta tarea de manera más conveniente.
* Documento de referencia de Oracle: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS233
(Para referencia, DBMS_PARALLEL_EXECUTE usa JOB internamente, por lo que la autoridad CREATE JOB debe otorgarse al usuario que lo ejecuta).
DBMS_PARALLEL_EXECUTE es un paquete introducido como una nueva función en Oracle 11g R2. La lista de los principales subprogramas se muestra en la siguiente tabla, y la lista completa y la explicación se pueden encontrar en el documento de Oracle.
| subprograma | Explicación |
| Procedimiento CREATE_TASK | crear una tarea |
| Procedimiento CREATE_CHUNKS_BY_NUMBER_COL | Crear fragmento por NÚMERO columna |
| Procedimiento CREATE_CHUNKS_BY_ROWID | Crear fragmentos con ROWID |
| Procedimiento CREATE_CHUNKS_BY_SQL | Crear fragmentos con SQL personalizado |
| Procedimiento DROP_TASK | Quitar tarea |
| Procedimiento DROP_CHUNKS | Eliminar trozos |
| Procedimientos RESUME_TASK | Volver a ejecutar una tarea detenida |
| Procedimiento RUN_TASK | ejecutar la tarea |
| Procedimiento STOP_TASK | detener la tarea |
| Procedimiento TASK_STATUS | Devolver el estado actual de la tarea |
Los pasos para aplicar DBMS_PARALLEL_EXECUTE son casi similares a los pasos para ejecutar Program Parallel DML de la siguiente manera.
- Crear tarea (CREATE_TASK)
- División de la unidad de trabajo (fragmento) (se proporcionan tres métodos de ROWID, NUMBER y SQL)
- CREATE_CHUNKS_BY_ROWID
- CREATE_CHUNKS_BY_NUMBER_COL
- CREATE_CHUNKS_BY_SQL
- Ejecutar tarea (RUN_TASK)
- Eliminar después de completar la tarea (DROP_TASK)
1.3. Crear tablas y datos para la prueba DBMS_PARALLEL_EXECUTE
Cree tablas y datos para probar con el siguiente script.
-- 테스트 테이블과 데이터 생성
DROP TABLE Z_DPE_TEST_TAB PURGE;
CREATE TABLE Z_DPE_TEST_TAB (
ID NUMBER(10)
,MSG VARCHAR2(100)
,VAL NUMBER
,AUDSID NUMBER
) NOLOGGING;
-- 100만건 테스트 데이터 생성
INSERT /*+ APPEND */ INTO Z_DPE_TEST_TAB (ID, MSG)
SELECT LEVEL AS ID
,'Test Data ID: ' || TO_CHAR(LEVEL)
FROM DUAL
CONNECT BY LEVEL <= 1000000;
COMMIT;
Hay 4 columnas para usar en la prueba, y cada propósito es el siguiente.
| nombre de la columna | propósito |
| IDENTIFICACIÓN | Un valor para identificar cada fila en la tabla |
| GMS | un valor que proporciona una descripción |
| valor | Valor aleatorio actualizado en ejecución de prueba |
| AUDID | Un valor para comprobar en cuántas sesiones se ejecuta la prueba. Se actualiza con SYS_CONTEXT('USERENV','SESSIONID'). |
Como referencia, el entorno en el que se realizó esta prueba es el siguiente.
- DBMS: Oracle 11g R2 Enterprise 11.2.0.1.0 de 32 bits (en Windows 7 x64)
- H/W: CPU i5-5200U 2,20 GHz, memoria 8 GB, SSD 250 GB
A continuación, veamos un caso mediante la división de cada unidad de trabajo (trozo).
Artículos relacionados:
 Descripción de la conversión del conjunto de caracteres de Oracle Tabla de contenido completa
Descripción de la conversión del conjunto de caracteres de Oracle Tabla de contenido completa
 Conversión de juegos de caracteres de Oracle (4): 4.Configuración del entorno de prueba
Conversión de juegos de caracteres de Oracle (4): 4.Configuración del entorno de prueba
 Conversión de juego de caracteres de Oracle (3): 3. Configuración del entorno del cliente (2)
Conversión de juego de caracteres de Oracle (3): 3. Configuración del entorno del cliente (2)
 DBMS_PARALLEL_EXECUTE Descripción Tabla de contenido
DBMS_PARALLEL_EXECUTE Descripción Tabla de contenido
 4. Caso de procesamiento paralelo del método de partición SQL definido por el usuario (DBMS_PARALLEL_EXECUTE)
4. Caso de procesamiento paralelo del método de partición SQL definido por el usuario (DBMS_PARALLEL_EXECUTE)
 3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
3. NÚMERO Caso de procesamiento paralelo del método de división de columnas (DBMS_PARALLEL_EXECUTE)
 2.5. Comprobación detallada de la partición de la unidad de trabajo (DBMS_PARALLEL_EXECUTE)
2.5. Comprobación detallada de la partición de la unidad de trabajo (DBMS_PARALLEL_EXECUTE)
 2. Caso de procesamiento paralelo de partición ROWID (DBMS_PARALLEL_EXECUTE)
2. Caso de procesamiento paralelo de partición ROWID (DBMS_PARALLEL_EXECUTE)










¡Lo agradezco muchísimo!
¡Muchas gracias!