Oracle Character Set Conversion(1): 1. Necessity, Correct Oracle Character Set Setup Guide
Review the need for Oracle Character Set conversion and a guide to setting up the correct character set.
In many next-generation projects, one of the thorny issues related to Data Migration (data migration, data migration, data migration) is Oracle's character set conversion.
Most often it is a request to convert from an incorrect character set (eg US7ASCII) to a correct character set (eg KO16MSWIN949, AL32UTF8, etc.). In particular, the most problematic case is that the character set of the current DB is US7ASCII.
Because data that is not stored normally is shown as normal data, many trials and errors are encountered in conversion.
In the next few articles, I would like to share some tips and methods worth reviewing.
1. Oracle Character Set Conversion Needs
If you want to convert Oracle Character Set, it is because the following requirements exist.
- Incorrectly specified Character Set (US7ASCII)
- Globalization of the initially built system limited to domestic (conversion from Korean character set to Unicode character set)
1.1. Incorrectly specified Character Set (US7ASCII)
One of several important factors that determines when installing Oracle is the character set. After Oracle is installed, it is important to set it up well in the beginning because it is not easy to change it after the data is accumulated as the system is built and used.
Among the response files required when installing Oracle in silent mode, the character set default value is set to “US7ASCII” in the dbca.rsp file. It is commented out, and when installing, this setting must be accurately changed and entered. However, in the case of installation with just uncommenting due to mistake or negligence, the Character Set is designated as “US7ASCII”.
The following shows the default character set settings in the dbca.rsp file.
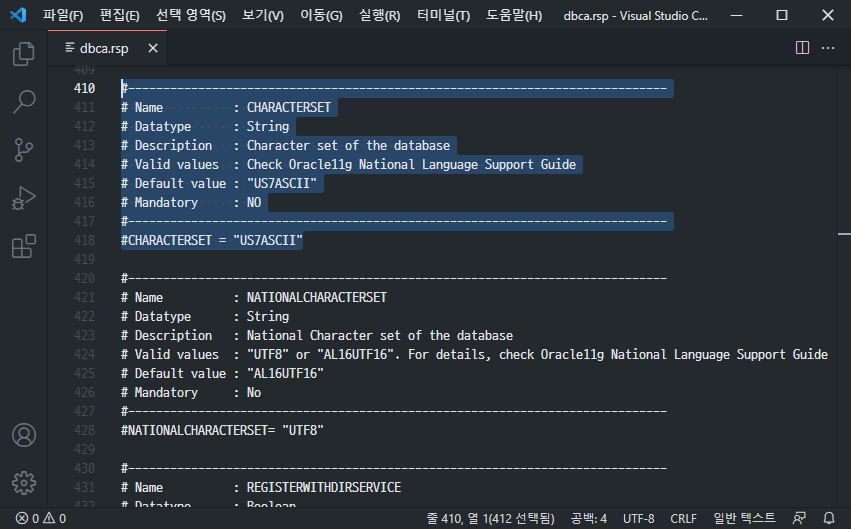
The situation that causes confusion here is that “US7ASCII” also supports Korean input and output. It behaves as if it were to be spoken correctly. Even if Korean data is input, but it is not normally stored, it is possible to output Korean as if it were normal.
However, since this is incomplete, unnecessary efforts such as Hangul conversion and processing logic in the application source code are required, and thus there is a possibility of causing an unintended error.
For “US7ASCII”, it is recommended to consider converting to “KO16MSWIN949” of Non-Unicode system or “UTF8” or “AL32UTF8” of Unicode system according to the purpose of the system.
1.2. Globalization of the system that was initially limited to domestic
If globalization is promoted through a next-generation project for a system in use with a character set of “KO16KSC5601” or “KO16MSWIN949”, conversion from Korean character set to Unicode character set is required.
Since “KO16KSC5601” or “KO16MSWIN949” cannot store all multilingual characters, it must be converted to Unicode series “UTF8” or “AL32UTF8”.
Since many domestic business environments are oriented toward globalization and the need to store multilingual characters cannot be completely excluded in the future, it is desirable to use Unicode-based character sets as much as possible.
If the application is not built after installation or if the stored data can be discarded, it is recommended to reinstall from the beginning. It takes much less effort to reinstall than the effort required to change a character set, is faster, and safer.
2. Guide to Setting Up the Correct Oracle Character Set
The Oracle Character Set is divided into Non-Unicode series and Unicode series, and organized according to the relation of inclusion as follows.
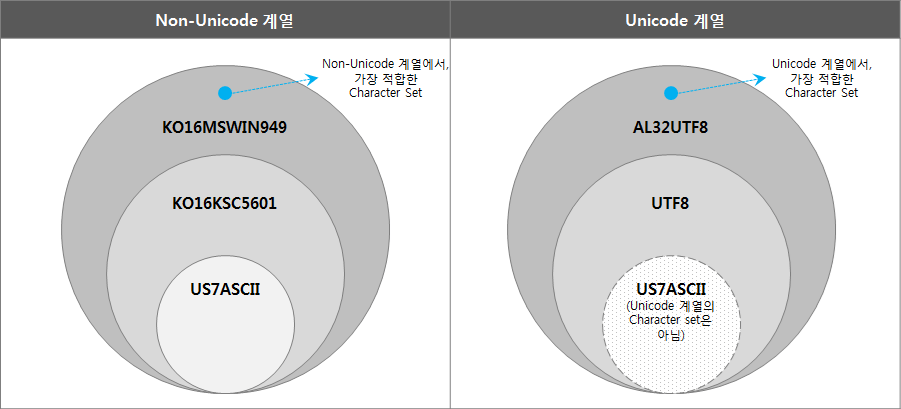
(“US7ASCII” is not a Unicode family, but is included and expressed as a subset of UTF8.)
To set up the Oracle Character Set correctly, simply choose one of the following two options:
| system type | Recommended Character Set | Explanation |
| System used only in Korea | KO16MSWIN949 | – All characters that can be input through the Korean IME in Korean Windows can be supported (Korean, Chinese characters, English, numbers, etc.) – Hangul and Chinese characters are stored as 2 bytes, and English and numbers are stored as 1 byte. |
| Systems that need to store multilingual characters | AL32UTF8 | – AL32UTF8 can support all characters added in the latest Unicode (Chinese characters, Western European characters, Southeast Asian characters, etc.) – English letters and numbers are stored in 1 byte, and most of the other characters are stored in 3 bytes. (Some characters are stored as 4 bytes, but they are rarely used.) |
Compared to “KO16MSWIN949”, “AL32UTF8” requires a maximum of 1.5 times the storage space for character types (when only Korean characters are included), but there are data (code, ID, number, sequence number, etc.) that only use English/numbers, and Korean and English characters. /Since there are many cases where the numbers are mixed, it is not accurate, but generally it can be seen that the storage space increases by 1.3 times.
For details on each character set, please refer to the following.
*Source: Looking into the perfect compatibility between Oracle and NLS (Ryu Jung-woo │ Oracle Korea WPTG Team) (OTN’s original original link has been removed)
| KO16KSC5601 | KO16MSWIN949 | UTF8 | AL32UTF8 | |
| Korean support status | Korean 2350 characters | KO16KSC5601 + extension 8822 characters (total 11172 characters) | Hangul 11172 characters | Hangul 11172 characters |
| Character set/encoding version | Korean complete form | complete code included Extended 8822 characters aligned according to MS Windows Codepage 949 | Prior to 8.1.6: Unicode 2.1 Since 8.1.7: Unicode 3.0 | 9i Rel1: Unicode 3.0 9i Rel2: Unicode 3.1 10g Rel1: Unicode 3.2 10g Rel2: Unicode 4.0 |
| Hangul Byte | 2 bytes | 2 bytes | 3 bytes | 3 bytes |
| Supported version | 7.x | 8.0.6 or later | 8.0 onwards | 9i Release 1 and higher |
| Database Character setCan be set to | possible | possible | possible | possible |
| National Character setCan be set to | impossible | impossible | possible | impossible |
| Hangul Sort (NLS_SORT Set) | Can be implemented with simple binary sort | Requires special options such as KOREAN_M or UNICODE_BINARY (Refer to the description of Korean sorting) | Hangul sorting is possible with simple binary sorting. Sorting Chinese characters requires the KOREAN_M option | – Hangul support is the same as UTF8 |
| Advantages | – No special advantages. High performance when it is certain to input and output only complete code | – All Korean characters can be stored/input/output with 2 bytes. All Korean characters can be input and output while space consumption is small. | – 11,172 modern Korean characters are arranged in the correct order, so alignment is effective – If other languages (Chinese, Thai, etc.) also need to be stored in the same database instance, there is no alternative other than Unicode character sets such as UTF8. | |
| disadvantage | – There is a fatal disadvantage that only 2350 Korean characters are supported, so the use of character sets should be avoided in the future. | – In an attempt to be compatible with the finished type, the letter arrangement and sorting order are different. A simple “ORDER BY” clause cannot properly sort Hangul. | One Korean character consumes 3 bytes, so space consumption is relatively large (1.5 times compared to 2 bytes), and performance must be consumed for Unicode encoding/decoding. |
* “UTF8” supports only up to Unicode 3.0, and “AL32UTF8” supports the latest version of Unicode and the version to be released in the future.
Oracle documentation also recommends “AL32UTF8”.
source: http://docs.oracle.com/cd/E11882_01/server.112/e10729/ch2charset.htm#NLSPG002
Some excerpts are pasted below.
Database Character Set Statement of Direction
A list of character sets has been compiled in Table A-4, “Recommended ASCII Database Character Sets” and Table A-5, “Recommended EBCDIC Database Character Sets” that Oracle strongly recommends for usage as the database character set. Other Oracle-supported character sets that do not appear on this list can continue to be used in Oracle Database 11g Release 2, but may be desupported in a future release. Starting with Oracle Database 11g Release 1, the choice for the database character set is limited to this list of recommended character sets in common installation paths of Oracle Universal Installer and Oracle Database Configuration Assistant. Customers are still able to create new databases using custom installation paths and migrate their existing databases even if the character set is not on the recommended list. However, Oracle suggests that customers migrate to a recommended character set as soon as possible. At the top of the list of character sets that Oracle recommends for all new system deployment, is the Unicode character set AL32UTF8.Choosing Unicode as a Database Character Set
Oracle recommends using Unicode for all new system deployments. Migrating legacy systems to Unicode is also recommended. Deploying your systems today in Unicode offers many advantages in usability, compatibility, and extensibility. Oracle Database enables you to deploy high-performing systems faster and more easily while utilizing the advantages of Unicode. Even if you do not need to support multilingual data today, nor have any requirement for Unicode, it is still likely to be the best choice for a new system in the long run and will ultimately save you time and money as well as give you competitive advantages in the long term. See Chapter 6, “Supporting Multilingual Databases with Unicode” for more information about Unicode.
Please refer to the underlined section above.
Up to this point, we have looked at the need for Oracle Character Set conversion and a guide for setting the correct Oracle Character Set. Next, we will look at the configuration of the client environment related to Oracle Character Set.
Related articles:
 Oracle Character Set Conversion Description Full Table of Contents
Oracle Character Set Conversion Description Full Table of Contents
 Oracle Character Set Conversion (10): 6.3. How to convert CLOB type to Korean
Oracle Character Set Conversion (10): 6.3. How to convert CLOB type to Korean
 Oracle Character Set Conversion (9): 6. How to Convert User Implemented Character Sets (2)
Oracle Character Set Conversion (9): 6. How to Convert User Implemented Character Sets (2)
 Oracle Character Set Conversion(8): 6. How to Convert User Implemented Character Set (1)
Oracle Character Set Conversion(8): 6. How to Convert User Implemented Character Set (1)
 Oracle Character Set Conversion (7): 5.4. KO16MSWIN949 Environment CSSCAN Execution Result
Oracle Character Set Conversion (7): 5.4. KO16MSWIN949 Environment CSSCAN Execution Result
 Oracle Character Set Conversion (4): 4.Configuring the Test Environment
Oracle Character Set Conversion (4): 4.Configuring the Test Environment
 Oracle Character Set Conversion (3): 3. Client Environment Configuration (2)
Oracle Character Set Conversion (3): 3. Client Environment Configuration (2)
 Oracle Character Set Conversion (2): 3. Configuring the Client Environment (1)
Oracle Character Set Conversion (2): 3. Configuring the Client Environment (1)









