Work distribution optimization tool using one-dimensional bin packing algorithm Full Contents, Download

The entire contents of the explanatory text on the task distribution optimization tool using the one-dimensional bin packing algorithm have been separately organized. I have put a link in the entire table of contents so that you can find the content of this article by index.
- 2. One-dimensional Bin Packing Algorithm
- 2.1. One-dimensional Bin Packing Algorithm Type
- 2.2. Next Fit Algorithm
- 2.3. First Fit Algorithm
- 2.4. Worst Fit Algorithm
- 2.5. Best Fit Algorithm
- 2.6. Apply descending sort by Item size
- 2.7. Next Fit with descending sort
- 2.8. First Fit with Descending Sort
- 2.9. Worst Fit with Descending Sort
- 2.10. Best Fit with Descending Sort
- 2.11. Comparison of algorithm application results
- 3. Bin Packing Algorithm Implementation
- 4. Future development direction and reference materials
- 5. Attachment5.1. Excel VBA based tool source code5.1.1. Run sheet source code
One-dimensional Bin Packing Tool Recent Changes (as of March 21, 2021)
- 1. Summary of Changes
- 2. Details of changes
- 2.1 Change Item Size from Integer (Long) to Real (Double) (Change variable name prefix)
- 2.2 BinItem name case sensitive (Changed from Collection to Dictionary)
- 2.3 Order Sort by Odd and Even Groups of Distribution Results
- 2.4. BinItem loading code improvement
- 2.5. If there are duplicates in the Bin Item Name, a duplicate list message box is displayed and the execution is aborted.
The work distribution optimization tool using the one-dimensional bin packing algorithm can be found in the GitHub repository below.
https://github.com/DAToolset/1D-bin-packing
Alternatively, you can download directly from this URL.
https://github.com/DAToolset/1D-bin-packing/blob/main/1D Bin Packing_20210321_1.xlsb?raw=true
One-dimensional bin packing tools can be used for data migration (migration, conversion, migration), data quality diagnosis, data profiling, etc. The work group can be allocated by the number of data cases, table size, etc., or by the average execution time of the last 3 to 5 times.
It can be used universally when you want to execute many tasks of hundreds or thousands at the same time in parallel, so please use it appropriately where you need it.
Related articles:
 Excel VBA Course (2): Excel VBA Basics
Excel VBA Course (2): Excel VBA Basics
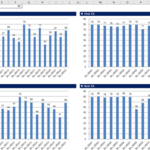 One-dimensional Bin Packing Tool Recent Changes (as of March 21, 2021)
One-dimensional Bin Packing Tool Recent Changes (as of March 21, 2021)
 Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
Optimization of work distribution using one-dimensional bin packing algorithm_4.Attachment
 Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)
Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (2)
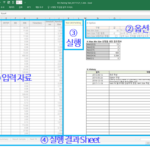 Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (1)
Optimization of work distribution using one-dimensional bin packing algorithm_3.Implementation (1)
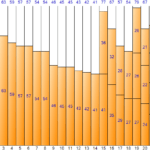 Optimization of work distribution using one-dimensional bin packing algorithm_2.Algorithm(2)
Optimization of work distribution using one-dimensional bin packing algorithm_2.Algorithm(2)
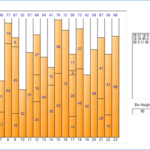 Optimization of work distribution using one-dimensional bin packing algorithm_2.Algorithm (1)
Optimization of work distribution using one-dimensional bin packing algorithm_2.Algorithm (1)
 Optimization of work distribution using one-dimensional bin packing algorithm_1.Overview
Optimization of work distribution using one-dimensional bin packing algorithm_1.Overview









