Release Word Extraction Tool v0.41: DBSchema-Vorkommenshäufigkeit von Wörtern hinzugefügt
* Bitte beachten Sie auch die neu veröffentlichte v0.42, indem Sie Fehler beheben.
Release Word Extractor v0.42: Fehlerbehebung – Produktivitäts-Skill (prodskill.com)
Verteilen Sie nach der Ergänzung die Funktion zum Hinzufügen und Extrahieren von DBSchema-Vorkommenshäufigkeitselementen von Wörtern aus dem zuvor verteilten Wortextraktionstool (v0.40). Das Element DBSchema_Freq informiert, über wie viele DB-Schemas die Quelle des Wortes verteilt ist.
Bezug: Wortextraktionstool(1): Überblick über das Wortextraktionstool

Quelle: https://stocksnap.io/photo/dictionary-page-ELRF6CYOHI
1. Das Ergebnis des Wortextraktionstools ändert sich
Ein Beispiel für das Wortextraktionsergebnis des zuvor vertriebenen Tools ist wie folgt.
▼ Beispielblatt „Worthäufigkeit“ vor der Änderung (v0.40)
| Wort | Freq | Quelle |
| Code | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (administrativer Zonencode) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (Identifikationscode ändern) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE (Versuchscode) … |
| Anzahl | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(Auftragsseriennummer) DB1.OWNER1.COMTCZIP.ZIP (Postleitzahl) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (Genehmigungsnummer) … |
| Anzahl der Personen | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (Adressbuchname) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (Klassifizierungscodename) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (Codename) … |
DBSchema_Freq-Elemente werden wie folgt zu den aus v0.41 extrahierten Ergebnissen hinzugefügt.
▼ Beispielblatt „Worthäufigkeit“ nach Änderung (v0.41)
| Wort | Freq | Quelle | DBSchema_Freq |
| Code | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (administrativer Zonencode) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (Identifikationscode ändern) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE (Versuchscode) … | 10 |
| Anzahl | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(Auftragsseriennummer) DB1.OWNER1.COMTCZIP.ZIP (Postleitzahl) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (Genehmigungsnummer) … | 9 |
| Anzahl der Personen | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (Adressbuchname) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (Klassifizierungscodename) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (Codename) … | 5 |
Das Element DBSchema_Freq informiert, über wie viele DB-Schemas die Quelle des Wortes verteilt ist. Informationen, die zum Auswählen von Standardwortkandidaten erforderlich sind, können etwas ausführlicher bereitgestellt werden.
- Wenn die Frequenz (Freq) hoch ist, aber die DBSchema-Frequenz (DBSchema_Freq) niedrig ist
- Das Wort kommt intensiv nur in einem bestimmten DB-Schema vor
- Wenn sowohl die Frequenz (Freq) als auch die DBSchema-Frequenz (DBSchema_Freq) hoch sind
- Das Wort wird gleichmäßig über das gesamte DB-Schema verteilt
- Wenn die Frequenz (Freq) niedrig ist, aber die DBSchema-Frequenz (DBSchema_Freq) relativ hoch ist
- Das Wort wird eher auf Aufnahme als auf Ausschluss in den kanonischen Wortkandidaten überprüft
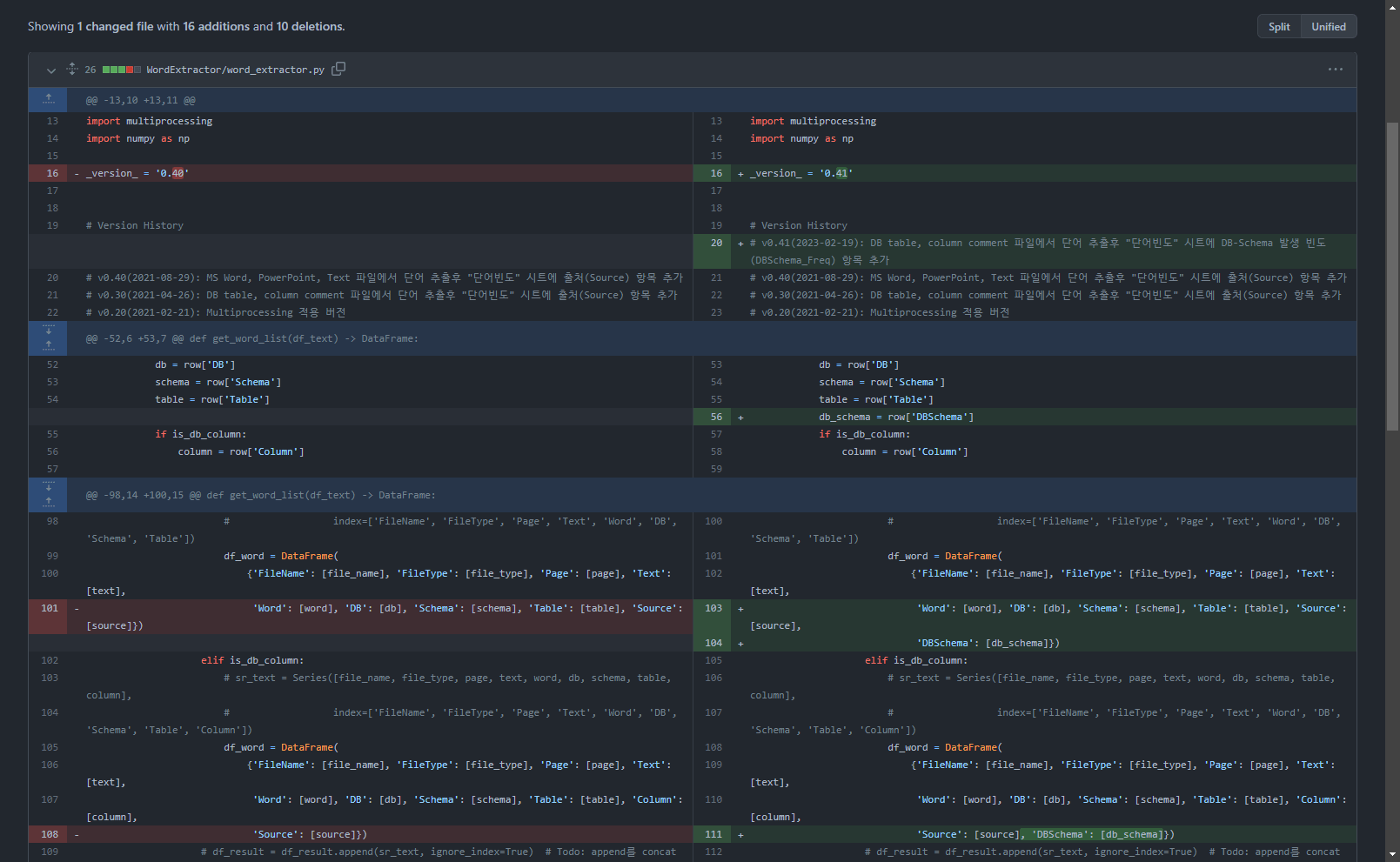
2. Quellcodeänderungen
Es gibt Änderungen an drei Funktionen.
2.1. Funktion get_db_comment_text geändert
Zeile 343 hinzufügen: Erstellen Sie eine DBSchema-Spalte in der Datenrahmenvariablen df_text, die das Ergebnis der Textextraktion enthält, und erstellen Sie einen Wert.
df_text['DBSchema'] = df_text['DB'] + '.' + df_text['Schema'] # DB.Schema 값 생성(2023-02-19)
2.2. Ändern Sie die get_word_list-Funktion
Zeile 104, 111 hinzufügen: DBSchema-Wert zum Datenrahmen des Ergebnisses der Wortextraktion hinzufügen
if len(words) >= 1:
# print(nouns, text)
for word in words:
# print(noun, '\t', text)
if not is_db:
# sr_text = Series([file_name, file_type, page, text, word],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'Source': [source]})
elif is_db_table:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Source': [source],
'DBSchema': [db_schema]})
elif is_db_column:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table, column],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table', 'Column'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Column': [column],
'Source': [source], 'DBSchema': [db_schema]})
2.3. Ändern Sie die Hauptfunktion
2.3.1. Hauptfunktionsinhalt vor Änderung
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
2.3.2. Hauptfunktionsinhalt nach Änderung
df_group = df_result.groupby('Word').agg({
'Word': 'count',
'Source': lambda x: '\n'.join(list(x)[:10]),
'DBSchema': 'nunique'
}).rename(columns={
'Word': 'Freq',
'Source': 'Source',
'DBSchema': 'DBSchema_Freq'
})
Dieser Code gruppiert Wort (word) in df_result, das eine Datenrahmenvariable als Ergebnis der Wortextraktion ist (groupby), erhält die Anzahl (nunique) von DBSchema-Werten mit entfernten Duplikaten und benennt das Element als DBSchema_Freq.
Als Referenz ist dieser Code der Testcode, den ich geschrieben habe. ChatGPTDies ist der Kodex, der zur Vereinfachung gegeben und angefordert wurde. Vor der Vereinfachung war es ein komplexer Code, der in zwei Datenrahmen aufgeteilt wurde, Lambda und Nunique auf jeden anwendete und sie dann zu einem zusammenführte. in letzter Zeit ChatGPT Bewunderung der Fähigkeit
2.4. Vollständige Details des Quellcodes in v0.41 geändert
Sie können die Details der Änderungen im Github-Link unten überprüfen.
3. Word Extraction Tool (v0.41) herunterladen und ausführen
Sie können die geänderte Datei word_extractor.py im folgenden Link überprüfen.
ToolsForDataStandard/word_extractor.py unter DAToolset/ToolsForDataStandard (github.com)
Die Ausführungsmethode ist die gleiche wie bei v0.40. Bitte beachten Sie die unten stehenden Informationen.
Das Wortextraktionstool v0.41 ist nicht gut getestet und kann Fehler oder Bugs einführen. Bitte hinterlassen Sie Fehler, Bugs, Anfragen usw. in den Kommentaren.
In Verbindung stehende Artikel:
 Version des Word Extraction Tool v0.42: Fehlerbehebung
Version des Word Extraction Tool v0.42: Fehlerbehebung
 Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
 Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
 Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
 Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
 Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
 Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
 Wortextraktionstool(1): Überblick über das Wortextraktionstool
Wortextraktionstool(1): Überblick über das Wortextraktionstool










Hallo!
Bei Verwendung der Methode zum Extrahieren von Wörtern aus einer Datei ohne DB-Kommentar, die eine der drei Ausführungsmethoden ist
(python word_extractor.py –in_path .\in –out_path .\out)
txt, Wort, ppt alle
miniconda3\envs\wordextr\lib\site-packages\pandas\core\apply.py“, Zeile 601, in normalize_dictlike_arg raise KeyError(f“Column(s) {cols_sorted} do not exist“)
KeyError: „Spalte(n) ['DBSchema'] existieren nicht“
Es wird mit einem Fehler beendet.
Die Ausführungsmethoden 2 und 3, bei denen die DB-Kommentardatei eingetragen wird, funktionieren fehlerfrei.
Ich habe 'DBSchema': [db_schema] in Zeile 97 eingefügt, aber dieses Mal
In get_grouper raise KeyError(gpr) KeyError: „Wort“-Fehler wird angezeigt.
Danke
Danke, dass Sie den Fehler gemeldet haben.
Sie haben bereitgestellt, ohne den Fall des Extrahierens von Wörtern nur aus der Datei zu testen.
Wir werden in Kürze eine getestete und fehlerbereinigte Version erneut veröffentlichen.
Neuveröffentlichung von v0.42 mit Fehlerbehebungen.
https://prodskill.com/ko/word-extractor-v0-42-bug-fix-for-dbschema/
Danke