Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
Untersuchen Sie den Quellcode eines in Python implementierten Wortextraktionstools.
Dies ist eine Fortsetzung des vorherigen Artikels.
Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
4. Quellcode des Wortextraktionstools
4.1. Gliederung
4.1.1. den Quellcode einfügen
Der Quellcode dieses Wortextraktionstools ist fast der erste Code, den ich unter den nützlichen Tools geschrieben habe, die in Python erstellt wurden. Da es sich nur auf die Implementierung notwendiger Funktionen konzentriert, wenn es noch nicht vertraut ist, ist es weit entfernt von der Prägnanz, die der Vorteil von Python ist. Es ähnelt eher dem C-Stil als dem Python-Stil.
Ich dachte daran, Textextraktionsergebnisse und Wortextraktionsergebnisse in separate Klassen zu schreiben, aber ich habe versucht, den DataFrame von Pandas als Test zu verwenden, und es funktionierte besser als ich dachte, also habe ich einfach DataFrame verwendet. Als Bonus wurde die Implementierungszeit durch die Verwendung der von DataFrame bereitgestellten Funktionen groupby und to_excel erheblich verkürzt.
“2.1.2. Wählen Sie einen Stemmer: MecabWie in „erwähnt, wurde Mecab für die Wortextraktion in natürlicher Sprache verwendet. Um andere Morphem-Analysatoren zu verwenden, ändern Sie bitte die get_word_list-Funktion.
Die Zeilennummer des in den Text eingefügten Codes ist gleich der Zeilennummer des auf github hochgeladenen Quellcodes, und alle Kommentare sind enthalten, ohne Kommentare so weit wie möglich auszuschließen.
4.1.2 Funktionsaufrufbeziehung des Wortextraktionswerkzeugs
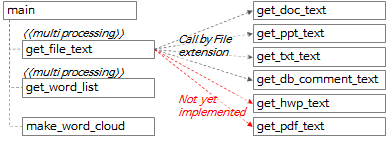
Die gesamte Aufrufbeziehung von Funktionen kann als obiges Diagramm und nachstehender Inhalt zusammengefasst werden.
- In der Hauptfunktion wird die Funktion get_file_text aufgerufen, um Text in Zeileneinheiten und Absatzeinheiten aus jeder Datei zu extrahieren.
- Rufen Sie innerhalb der Funktion get_file_text die Funktionen get_doc_text, get_ppt_text, get_txt_text und get_db_comment_text entsprechend der Dateierweiterung auf.
- Die Funktionen get_hwp_text und get_pdf_text wurden noch nicht implementiert und werden bei Bedarf später implementiert. (Wenn Sie Erfahrung mit der Implementierung haben oder den implementierten Code kennen, hinterlassen Sie bitte einen Kommentar.)
- Das Ausführungsergebnis der get_file_text-Funktion wird an die get_word_list-Funktion übertragen, um Wortkandidaten zu extrahieren.
- Die Funktionen get_file_text und get_word_list sind Multiprocessing.
- Rufen Sie die Funktion make_word_cloud auf, um ein Wortwolkenbild zu erstellen.
4.2. Hauptfunktion
4.2.1. Argumentanalyse
def main():
"""
지정한 경로 하위 폴더의 File들에서 Text를 추출하고 각 Text의 명사를 추출하여 엑셀파일로 저장
:return: 없음
"""
# region Args Parse & Usage set-up -------------------------------------------------------------
# parser = argparse.ArgumentParser(usage='usage test', description='description test')
usage_description = """--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment"""
# ToDo: 옵션추가: 복합어 추출할지 여부, 영문자 추출할지 여부, 영문자 길이 1자리 제외여부, ...
parser = argparse.ArgumentParser(description=usage_description, formatter_class=argparse.RawTextHelpFormatter)
# name argument 추가
parser.add_argument('--multi_process_count', required=False, type=int,
help='text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)')
parser.add_argument('--db_comment_file', required=False,
help='DB Table, Column comment 정보 파일명(예: comment.xlsx)')
parser.add_argument('--in_path', required=False, help='입력파일(ppt, doc, txt) 경로명(예: .\in) ')
parser.add_argument('--out_path', required=True, help='출력파일(xlsx, png) 경로명(예: .\out)')
args = parser.parse_args()
if args.multi_process_count:
multi_process_count = int(args.multi_process_count)
else:
multi_process_count = multiprocessing.cpu_count()
db_comment_file = args.db_comment_file
if db_comment_file is not None and not os.path.isfile(db_comment_file):
print('db_comment_file not found: %s' % db_comment_file)
exit(-1)
in_path = args.in_path
out_path = args.out_path
print('------------------------------------------------------------')
print('Word Extractor v%s start --- %s' % (_version_, get_current_datetime()))
print('##### arguments #####')
print('multi_process_count: %d' % multi_process_count)
print('db_comment_file: %s' % db_comment_file)
print('in_path: %s' % in_path)
print('out_path: %s' % out_path)
print('------------------------------------------------------------')
- Zeile 395: Erstellen Sie ein ArgumentParser-Objekt aus dem argparse-Paket.
- Zeilen 397 bis 404: Fügen Sie die erforderlichen Argumente hinzu und analysieren Sie die zur Ausführungszeit angegebenen Argumente.
- Zeilen 406~425: Argumente werden als interne Variablen gesetzt und die gesetzten Werte ausgegeben.
4.2.2. Liste der zu verarbeitenden Dateien extrahieren
file_list = []
if in_path is not None and in_path.strip() != '':
print('[%s] Start Get File List...' % get_current_datetime())
in_abspath = os.path.abspath(in_path) # os.path.abspath('.') + '\\test_files'
file_types = ('.ppt', '.pptx', '.doc', '.docx', '.txt')
for root, dir, files in os.walk(in_abspath):
for file in sorted(files):
# 제외할 파일
if file.startswith('~'):
continue
# 포함할 파일
if file.endswith(file_types):
file_list.append(root + '\\' + file)
print('[%s] Finish Get File List.' % get_current_datetime())
print('--- File List ---')
print('\n'.join(file_list))
if db_comment_file is not None:
file_list.append(db_comment_file)
- Zeile 436: Definieren Sie die Liste der Dateierweiterungen, die den zu verarbeitenden Dateien entsprechen.
- Zeilen 437~444: Durchsuchen Sie rekursiv alle Ordner unter in_path unter den zur Ausführungszeit angegebenen Argumenten, bestimmen Sie, ob jede Datei eine Zieldatei ist, und fügen Sie sie, falls ja, zu file_list hinzu.
- Zeilen 451~452: Wenn db_comment_file unter den bei der Ausführung angegebenen Argumenten vorhanden ist, fügen Sie es zu file_list hinzu.
4.2.3. Führen Sie get_file_text mit Mehrfachverarbeitung aus
print('[%s] Start Get File Text...' % get_current_datetime())
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_text_result = pool.map(get_file_text, file_list)
df_text = pd.concat(mp_text_result, ignore_index=True)
print('[%s] Finish Get File Text.' % get_current_datetime())
# 여기까지 text 추출완료. 아래에 단어 추출 시작
- Zeilen 455 bis 456: Führen Sie die get_file_text-Funktion mit file_lsit als Eingabe in jedem Prozess aus, indem Sie zur Ausführungszeit so viele Prozesse wie die angegebene multi_process_count ausführen und das Ergebnis in mp_text_result einfügen.
- Zeile 457: Konkatiere jedes Listenelement von mp_text_result, das in Form einer Liste von DataFrames vorliegt, um df_text zu erstellen, das ein DataFrame ist.
4.2.4. Führen Sie get_word_list mit Mehrfachverarbeitung aus
# ---------- 병렬 실행 ----------
print('[%s] Start Get Word from File Text...' % get_current_datetime())
df_text_split = np.array_split(df_text, multi_process_count)
# mp_result = []
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_result = pool.map(get_word_list, df_text_split)
df_result = pd.concat(mp_result, ignore_index=True)
if 'DB' not in df_result.columns:
df_result['DB'] = ''
df_result['Schema'] = ''
df_result['Table'] = ''
df_result['Column'] = ''
print('[%s] Finish Get Word from File Text.' % get_current_datetime())
# ------------------------------
- Zeile 463: Teilen Sie die Zeilen von df_text durch multi_process_count und fügen Sie jeden geteilten DataFrame in df_text_split (Listentyp) ein.
- Wenn beispielsweise df_text 1000 Zeilen hat und multi_process_count 4 ist, werden 4 DataFrames mit jeweils 250 Zeilen erstellt und df_text_split-Variablen mit diesen 4 DataFrames als Elemente werden erstellt.
- Zeilen 465~466: Führen Sie die get_word_list-Funktion mit df_text_split als Eingabe in jedem Prozess aus, indem Sie zur Ausführungszeit so viele Prozesse wie die angegebene multi_process_count ausführen und das Ergebnis in mp_result einfügen.
- Zeile 468: Verknüpfen Sie jedes Listenelement von mp_result, das in Form einer Liste von DataFrames vorliegt, um einen DataFrame, df_result, zu erstellen.
- Zeilen 469-473: 'DB', 'Schema', 'Table', 'Column', um die nachfolgende Verarbeitungslogik zu vereinfachen und Fehler zu vermeiden, wenn 'DB' nicht in df_result.columns vorhanden ist, dh wenn db_comment_file nicht angegeben ist eine Spalte mit dem Namen ' als leeren Wert.
4.2.5. Holen Sie sich Worthäufigkeiten und führen Sie make_word_cloud aus
print('[%s] Start Get Word Frequency...' % get_current_datetime())
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
df_group = df_group.sort_values(by='Freq', ascending=False)
print('[%s] Finish Get Word Frequency.' % get_current_datetime())
# df_group['Len'] = df_group['Word'].str.len()
# df_group['Len'] = df_group['Word'].apply(lambda x: len(x))
print('[%s] Start Make Word Cloud...' % get_current_datetime())
now_dt = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
make_word_cloud(df_group, now_dt, out_path)
print('[%s] Finish Make Word Cloud.' % get_current_datetime())
- Zeile 480: Erstellen Sie einen df_result_subset DataFrame, indem Sie nur die Spalten „Wort“ und „Quelle“ aus „df_result“ auswählen.
- Zeile 482: Holen Sie sich die Anzahl, indem Sie df_result_subset mit der Spalte „Wort“ gruppieren, extrahieren Sie die ersten 10 Werte aus „Quelle“ und verbinden Sie sie mit einem Zeilentrennzeichen, um einen df_group DataFrame zu erstellen.
- Zeilen 483~484: Geben Sie den Indexnamen von df_group DataFrame als „Word“ und die Spaltennamen als „Freq“ bzw. „Source“ an.
- Zeile 485: Umgekehrte Sortierung von df_group nach 'Freq' (Worthäufigkeit).
- Zeile 491: Übergeben Sie df_group an die Funktion make_word_cloud, um das Wortwolkenbild zu erstellen und zu speichern.
4.2.6. Speichern Sie die extrahierte Wortliste und Worthäufigkeit als Excel-Datei, drucken Sie die Ausführungszeit und beenden Sie
print('[%s] Start Save the Extract result to Excel File...' % get_current_datetime())
df_result.index += 1
excel_style = {
'font-size': '10pt'
}
df_result = df_result.style.set_properties(**excel_style)
df_group = df_group.style.set_properties(**excel_style)
out_file_name = '%s\\extract_result_%s.xlsx' % (out_path, now_dt) # 'out\\extract_result_%s.xlsx' % now_dt
print('start writing excel file...')
with pd.ExcelWriter(path=out_file_name, engine='xlsxwriter') as writer:
df_result.to_excel(writer,
header=True,
sheet_name='단어추출결과',
index=True,
index_label='No',
freeze_panes=(1, 0),
columns=['Word', 'FileName', 'FileType', 'Page', 'Text', 'DB', 'Schema', 'Table', 'Column'])
df_group.to_excel(writer,
header=True,
sheet_name='단어빈도',
index=True,
index_label='단어',
freeze_panes=(1, 0))
workbook = writer.book
worksheet = writer.sheets['단어빈도']
wrap_format = workbook.add_format({'text_wrap': True})
worksheet.set_column("C:C", None, wrap_format)
# print('finished writing excel file')
print('[%s] Finish Save the Extract result to Excel File...' % get_current_datetime())
end_time = time.time()
# elapsed_time = end_time - start_time
elapsed_time = str(datetime.timedelta(seconds=end_time - start_time))
print('------------------------------------------------------------')
print('[%s] Finished.' % get_current_datetime())
print('overall elapsed time: %s' % elapsed_time)
print('------------------------------------------------------------')
- Zeilen 495 bis 501: Stellen Sie die Excel-Schriftgröße auf 10 Punkt und den Pfad und Dateinamen der zu speichernden Excel-Datei ein.
- Zeilen 504 bis 521: Speichern Sie df_result und df_group DataFrame als Excel-Datei mit pandas ExcelWriter.
- Zeilen 526 bis 532: Berechnen Sie die Zeit, die für die Ausführung benötigt wird, geben Sie sie aus und beenden Sie sie.
Dieser Artikel ist lang, also veröffentliche ich ihn in zwei Teilen. Fortsetzung im nächsten Artikel.
<< Liste verwandter Artikel >>
- Wortextraktionstool(1): Überblick über das Wortextraktionstool
- Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
- Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
- Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
- Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
- Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
- Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
In Verbindung stehende Artikel:
 Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
 Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
 Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
 Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
 Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
 Wortextraktionstool(1): Überblick über das Wortextraktionstool
Wortextraktionstool(1): Überblick über das Wortextraktionstool
 Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_4.Attachment
Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_4.Attachment
 Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_3.Implementierung (2)
Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_3.Implementierung (2)










Hallo
Ich habe eine get_pdf_text-Funktion mit dem Wortextraktionstool Word Code und „pdfplumber“ erstellt, das Sie gepostet haben.
Kann ich es Ihnen in einem Kommentar oder einer E-Mail zeigen?
Hallo!
Ich habe die Funktion get_pdf_text mithilfe des von Ihnen geposteten Wortextraktor-Quellcodes implementiert.
Es wurde bestätigt, dass es funktioniert, wenn pdf zum dateierweiterungsbezogenen Teil des vorhandenen Codes hinzugefügt und die Funktion get_pdf_tex hinzugefügt wird.
Lassen Sie mich wissen, was korrigiert werden muss, und ich kümmere mich darum.
Sie benötigen pip install pdfplumber.
pdfplumber importieren
def get_pdf_text(file_name) -> DataFrame:
start_time = time.time()
print('\r\nget_txt_text: ' + Dateiname)
df_text = pd.DataFrame()
pdf_file = pdfplumber.open(file_name)
Seite = 0
für pg in pdf_file.pages:
texts = pg. extract_text()
Seite += 1
für Text in Texten. split():
if text.strip() != ”:
sr_text = Series([file_name, 'pdf', page, text, f'{file_name}:{page}:{text}'],
index=['FileName', 'FileType', 'Page', 'Text', 'Source'])
df_text = df_text.append(sr_text,ignore_index=True)
print('text count: %s' % str(df_text. shape[0]))
print('Seitenanzahl: %d' % Seite)
pdf_file.close()
end_time = time.time()
elapsed_time = str(datetime.timedelta(seconds=end_time – start_time))
print('[pid:%d] get_pdf_text verstrichene Zeit: %s' % (os.getpid(), elapsed_time))
gib df_text zurück
Vielen Dank für die Weitergabe des Quellcodes der Funktion get_pdf_text.
Der von Ihnen geschriebene Quellcode ist eingerückt, aber das ist etwas unpraktisch zu erkennen, da die Einrückung in WordPress-Kommentaren nicht angezeigt wird.
Stellen wir die Einrückung so ein, dass sie sichtbar ist.
Wenn Sie die Einrückung so einstellen, dass sie sichtbar ist und Sie den eingerückten Originalquellcode benötigen, lade ich ihn erneut hoch.