Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
Werfen wir einen Blick darauf, wie das Wortextraktionstool ausgeführt wird, und überprüfen Sie die Ergebnisse.
Dies ist eine Fortsetzung des vorherigen Artikels.
Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
3. Führen Sie das Wortextraktionstool aus
3.1. Laden Sie das Wortextraktionstool herunter
Das Wortextraktionstool wurde auf github hochgeladen.
https://github.com/DAToolset/ToolsForDataStandard/tree/main/WordExtractor
Quellcodes, Schriftarten, Tabellen-/Spaltenlistenbeispieldateien und Ausgabebeispieldateien, die für die Ausführung erforderlich sind, sind in einer komprimierten Datei zur Verteilung gebündelt, sodass Sie diese Datei herunterladen können.
https://github.com/DAToolset/ToolsForDataStandard/raw/main/WordExtractor/word_extractor.7z
Dieses Distributionsarchiv enthält die folgenden Dateien:
[font] - NanumBarunGothic.ttf - NanumSquareR.ttf [out] - extract_result_20210829111836.xlsx - wordcloud_20210829111836.png - table,column comments.xlsx - word_extractor.py
Die Beschreibung jedes Ordners und jeder Datei lautet wie folgt.
- [Schriftart]
- Ordner mit den Schriftarten, die beim Erstellen von WordCloud benötigt werden
- Bei Bedarf können durch Änderung des Quellcodes weitere Schriftarten hinzugefügt und verwendet werden.
- Zu ändernde Funktion im Quellcode: make_word_cloud
- [aus]
- Ordner mit Beispieldateien von Ergebnissen der Wortextraktion
- Den Inhalt dieser Datei finden Sie im folgenden Artikel.
1.3.3. Ausgabedaten des Wortextraktionswerkzeugs
- Tabelle, Spalte Kommentare.xlsx
- DB-Tabelle, Spaltenkommentar-Eingabebeispieldatei
- Den Inhalt dieser Datei finden Sie im folgenden Artikel.
1.3.1._word_extraction_tool_input_data
- word_extractor.py: Quellcode des Wortextraktors (Python)
- Hinweis: Diese Quellcodedatei kann sich ändern, überprüfen Sie also die Github-Datei auf die neueste Version, nicht das Distributionsarchiv.
3.2. So führen Sie das Wortextraktionstool aus
3.2.1. Entpacken Sie die heruntergeladene Datei und aktivieren Sie die virtuelle Python-Umgebung
Extrahieren Sie die oben heruntergeladene komprimierte Distributionsdatei in einen geeigneten Pfad. (z. B. „d:\Projekt\WordExtractor“)
Führen Sie die Miniconda-Eingabeaufforderung aus, wechseln Sie zum entpackten Pfad und aktivieren Sie die virtuelle Python-Umgebung.
Informationen zum Aktivieren der virtuellen Python-Umgebung finden Sie im folgenden Artikel.
2.3. Erstellen und Aktivieren einer virtuellen Umgebung
Fahren Sie im folgenden Zustand der Miniconda-Eingabeaufforderung fort.
(wordextr) d:\Project\WordExtractor>
3.2.2. Überprüfen Sie die Hilfe
Sie können die Hilfe überprüfen, indem Sie das Argument „–help“ angeben und ausführen.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
Die Ausgabe bei der Ausführung ist wie folgt.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
usage: word_extractor.py [-h] [--multi_process_count MULTI_PROCESS_COUNT] [--db_comment_file DB_COMMENT_FILE] [--in_path IN_PATH] --out_path OUT_PATH
--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment
optional arguments:
-h, --help show this help message and exit
--multi_process_count MULTI_PROCESS_COUNT
text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)
--db_comment_file DB_COMMENT_FILE
DB Table, Column comment 정보 파일명(예: comment.xlsx)
--in_path IN_PATH 입력파일(ppt, doc, txt) 경로명(예: .\in)
--out_path OUT_PATH 출력파일(xlsx, png) 경로명(예: .\out)
Es gibt drei Möglichkeiten, dies zu tun. (Siehe „* Ausführungsbeispiel“ in der obigen Hilfe)
- Wörter nur aus Dokumentdateien extrahieren
- Geben Sie den Ordner, in dem MS Word-, PowerPoint- und Textdateien gespeichert werden, als „–in_path“ und den Ordner für die Ausgabe der Ergebnisse als „–out_path“ an.
- Wörter nur aus DB-Tabelle, Spaltenkommentare extrahieren
- Geben Sie die im Kommentardateiformat gespeicherte Excel-Datei als „–db_comment_file“ und den Ordner zur Ausgabe der Ergebnisse als „–out_path“ an.
- Extrahieren Sie Wörter aus beiden Dokumentdateien, DB-Tabellen und Spaltenkommentaren (so extrahieren Sie sowohl 1 als auch 2 auf einmal)
- Geben Sie alle „–in_path“, „–db_comment_file“, „–out_path“ an
Das Argument „–multi_process_count“ ist die Anzahl der Prozesse, die parallel ausgeführt werden, wenn Text aus einer Datei extrahiert und Wörter aus dem Text extrahiert werden. Die Leistung kann verbessert werden, indem eine geeignete Zahl entsprechend der Ausführungsumgebung angegeben wird.
In diesem Artikel wird das Argument „-multi_process_count“ nicht angegeben und ausgeführt. In diesem Fall wird sie während des Codeausführungsprozesses auf die Anzahl der logischen CPUs in der Ausführungsumgebung gesetzt. (zB 8 für i5-8250U CPU)
3.2.3. Methode 1: Wörter nur aus Dokumentdateien extrahieren
Erstellen Sie zunächst einen Ordner zum Speichern der Dokumentdatei unter dem Pfad, in dem sich der Python-Quellcode befindet.
Erstellen Sie beispielsweise den Ordner „in“ unter „d:\Project\WordExtractor“ und erstellen Sie den Pfad „d:\Project\WordExtractor\in“.
Kopieren Sie dann Dateien im MS Word-, PowerPoint- und Textformat in den Ordner „in“. Auch wenn es mehrere Ordnerebenen unter dem „in“-Ordner gibt, können sie alle durchsucht und verarbeitet werden, daher wird empfohlen, Unterordner nach Geschäftseinheit usw. zu organisieren.
Zum Zeitpunkt der Erstellung dieses Artikels (24.10.2021) werden HWP- und PDF-Dateien noch nicht unterstützt.
Führen Sie es mit dem folgenden Befehl aus: (Geben Sie –in_path, –out_path an)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out
Ein Beispiel des Ausführungsergebnisses ist wie folgt.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:15:11.985581 ##### arguments ##### multi_process_count: 8 db_comment_file: None in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:15:11.985581] Start Get File List... [2021-10-24 12:15:11.985581] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:15:11.985581] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx text count: 25 line count: 34 [pid:17976] get_txt_text elapsed time: 0:00:00.135933 text count: 124 page count: 5 [pid:5412] get_ppt_text elapsed time: 0:00:03.370637 text count: 59 page count: 3 [pid:22052] get_doc_text elapsed time: 0:00:04.100849 [2021-10-24 12:15:18.094089] Finish Get File Text. [2021-10-24 12:15:18.094089] Start Get Word from File Text... [pid:25016] input text count:26, extracted word count: 31 [pid:25016] get_word_list finished. total: 26, elapsed time: 0:00:00.109351 [pid:17704] input text count:26, extracted word count: 54 [pid:17704] get_word_list finished. total: 26, elapsed time: 0:00:00.156214 [pid:18468] input text count:26, extracted word count: 52 [pid:18468] get_word_list finished. total: 26, elapsed time: 0:00:00.140596 [pid:3456] input text count:26, extracted word count: 38 [pid:3456] get_word_list finished. total: 26, elapsed time: 0:00:00.109350 [pid:15400] input text count:26, extracted word count: 50 [pid:15400] get_word_list finished. total: 26, elapsed time: 0:00:00.140594 [pid:25892] input text count:26, extracted word count: 65 [pid:25892] get_word_list finished. total: 26, elapsed time: 0:00:00.171835 [pid:3592] input text count:26, extracted word count: 147 [pid:3592] get_word_list finished. total: 26, elapsed time: 0:00:00.312458 [pid:9512] input text count:26, extracted word count: 180 [pid:9512] get_word_list finished. total: 26, elapsed time: 0:00:00.374976 [2021-10-24 12:15:20.320614] Finish Get Word from File Text. [2021-10-24 12:15:20.320614] Start Get Word Frequency... [2021-10-24 12:15:20.336234] Finish Get Word Frequency. [2021-10-24 12:15:20.336234] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:06.681665 [2021-10-24 12:15:27.017899] Finish Make Word Cloud. [2021-10-24 12:15:27.017899] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:15:27.643679] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:15:27.643679] Finished. overall elapsed time: 0:00:15.658098 ------------------------------------------------------------
3.2.4. Methode 2: Wörter nur aus DB-Tabelle, Spaltenkommentare extrahieren
Öffnen Sie zunächst die in der komprimierten Datei enthaltene Datei „Tabelle, Spaltenkommentare.xlsx“ in Excel, füllen Sie den Inhalt gemäß dem Format aus und speichern Sie.
Unten finden Sie Beispiele für Format und Inhalt.
1.3.1. Eingabematerial für das Wortextraktionstool
Führen Sie es mit dem folgenden Befehl aus: (Geben Sie –db_comment_file, –out_path an)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
Der Dateiname wurde in doppelte Anführungszeichen (“) eingeschlossen, da der Eingabedateiname Leerzeichen enthielt.
Wenn sich die Datei „table,column comments.xlsx“ vom Pfad der Python-Quellcodedatei unterscheidet, geben Sie sie einschließlich des Pfads an. Es wird hier davon ausgegangen, dass sie sich auf dem gleichen Weg befinden.
Ein Beispiel des Ausführungsergebnisses ist wie folgt.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:34:23.369210 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: None out_path: .\out ------------------------------------------------------------ [2021-10-24 12:34:23.370209] Start Get File Text... get_db_comment_text: table,column comments.xlsx table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:17088] get_db_comment_text elapsed time: 0:00:01.216618 text count: 1680 [2021-10-24 12:34:26.577237] Finish Get File Text. [2021-10-24 12:34:26.577237] Start Get Word from File Text... [pid:25240] current: 100, total: 210, progress: 47.62% [pid:21792] current: 100, total: 210, progress: 47.62% [pid:14788] current: 100, total: 210, progress: 47.62% [pid:10660] current: 100, total: 210, progress: 47.62% [pid:17208] current: 100, total: 210, progress: 47.62% [pid:13300] current: 100, total: 210, progress: 47.62% [pid:23764] current: 100, total: 210, progress: 47.62% [pid:25068] current: 100, total: 210, progress: 47.62% [pid:13300] current: 200, total: 210, progress: 95.24% [pid:14788] current: 200, total: 210, progress: 95.24% [pid:13300] input text count:210, extracted word count: 804 [pid:13300] get_word_list finished. total: 210, elapsed time: 0:00:02.900049 [pid:10660] current: 200, total: 210, progress: 95.24% [pid:14788] input text count:210, extracted word count: 850 [pid:14788] get_word_list finished. total: 210, elapsed time: 0:00:03.005057 [pid:10660] input text count:210, extracted word count: 819 [pid:10660] get_word_list finished. total: 210, elapsed time: 0:00:03.040949 [pid:17208] current: 200, total: 210, progress: 95.24% [pid:25240] current: 200, total: 210, progress: 95.24% [pid:17208] input text count:210, extracted word count: 929 [pid:17208] get_word_list finished. total: 210, elapsed time: 0:00:03.182333 [pid:25240] input text count:210, extracted word count: 871 [pid:25240] get_word_list finished. total: 210, elapsed time: 0:00:03.320128 [pid:23764] current: 200, total: 210, progress: 95.24% [pid:21792] current: 200, total: 210, progress: 95.24% [pid:23764] input text count:210, extracted word count: 1054 [pid:23764] get_word_list finished. total: 210, elapsed time: 0:00:03.362429 [pid:25068] current: 200, total: 210, progress: 95.24% [pid:21792] input text count:210, extracted word count: 1077 [pid:21792] get_word_list finished. total: 210, elapsed time: 0:00:03.651294 [pid:25068] input text count:210, extracted word count: 1163 [pid:25068] get_word_list finished. total: 210, elapsed time: 0:00:03.616955 [2021-10-24 12:34:32.287245] Finish Get Word from File Text. [2021-10-24 12:34:32.287245] Start Get Word Frequency... [2021-10-24 12:34:32.313363] Finish Get Word Frequency. [2021-10-24 12:34:32.313363] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.572230 [2021-10-24 12:34:42.886547] Finish Make Word Cloud. [2021-10-24 12:34:42.886547] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:34:48.636633] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:34:48.636633] Finished. overall elapsed time: 0:00:25.266424 ------------------------------------------------------------
3.2.5. Methode 3: Extrahieren von Wörtern aus beiden Dokumentdateien, DB-Tabellen und Spaltenkommentaren
Dies ist eine Methode, die Methode 1 und Methode 2 gleichzeitig ausführen kann.
Führen Sie es mit dem folgenden Befehl aus: (Geben Sie –db_comment_file, –in_path, –out_path an)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out
Ein Beispiel des Ausführungsergebnisses ist wie folgt.
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:43:31.847674 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:43:31.848673] Start Get File List... [2021-10-24 12:43:31.849672] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:43:31.849672] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx get_db_comment_text: table,column comments.xlsx text count: 25 line count: 34 [pid:11692] get_txt_text elapsed time: 0:00:00.135359 table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:21044] get_db_comment_text elapsed time: 0:00:01.580088 text count: 1680 text count: 124 page count: 5 [pid:23812] get_ppt_text elapsed time: 0:00:04.757793 text count: 59 page count: 3 [pid:23724] get_doc_text elapsed time: 0:00:06.661778 [2021-10-24 12:43:40.690639] Finish Get File Text. [2021-10-24 12:43:40.690639] Start Get Word from File Text... [pid:18392] current: 100, total: 236, progress: 42.37% [pid:8036] current: 100, total: 236, progress: 42.37% [pid:26864] current: 100, total: 236, progress: 42.37% [pid:23288] current: 100, total: 236, progress: 42.37% [pid:15596] current: 100, total: 236, progress: 42.37% [pid:8036] current: 200, total: 236, progress: 84.75% [pid:18208] current: 100, total: 236, progress: 42.37% [pid:17976] current: 100, total: 236, progress: 42.37% [pid:4324] current: 100, total: 236, progress: 42.37% [pid:18392] current: 200, total: 236, progress: 84.75% [pid:26864] current: 200, total: 236, progress: 84.75% [pid:8036] input text count:236, extracted word count: 739 [pid:8036] get_word_list finished. total: 236, elapsed time: 0:00:02.651907 [pid:18392] input text count:236, extracted word count: 780 [pid:18392] get_word_list finished. total: 236, elapsed time: 0:00:02.879298 [pid:15596] current: 200, total: 236, progress: 84.75% [pid:26864] input text count:236, extracted word count: 887 [pid:26864] get_word_list finished. total: 236, elapsed time: 0:00:03.161543 [pid:15596] input text count:236, extracted word count: 979 [pid:15596] get_word_list finished. total: 236, elapsed time: 0:00:03.443786 [pid:18208] current: 200, total: 236, progress: 84.75% [pid:23288] current: 200, total: 236, progress: 84.75% [pid:17976] current: 200, total: 236, progress: 84.75% [pid:18208] input text count:236, extracted word count: 1181 [pid:18208] get_word_list finished. total: 236, elapsed time: 0:00:03.831052 [pid:4324] current: 200, total: 236, progress: 84.75% [pid:23288] input text count:236, extracted word count: 1242 [pid:23288] get_word_list finished. total: 236, elapsed time: 0:00:04.139228 [pid:17976] input text count:236, extracted word count: 1294 [pid:17976] get_word_list finished. total: 236, elapsed time: 0:00:04.113296 [pid:4324] input text count:236, extracted word count: 1082 [pid:4324] get_word_list finished. total: 236, elapsed time: 0:00:04.334706 [2021-10-24 12:43:47.324098] Finish Get Word from File Text. [2021-10-24 12:43:47.325098] Start Get Word Frequency... [2021-10-24 12:43:47.353058] Finish Get Word Frequency. [2021-10-24 12:43:47.353058] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.604237 [2021-10-24 12:43:57.958289] Finish Make Word Cloud. [2021-10-24 12:43:57.958289] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:44:04.752046] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:44:04.752046] Finished. overall elapsed time: 0:00:32.903374 ------------------------------------------------------------
Ein Teil des obigen Ausführungsprozesses wird erfasst und als Bild eingefügt.
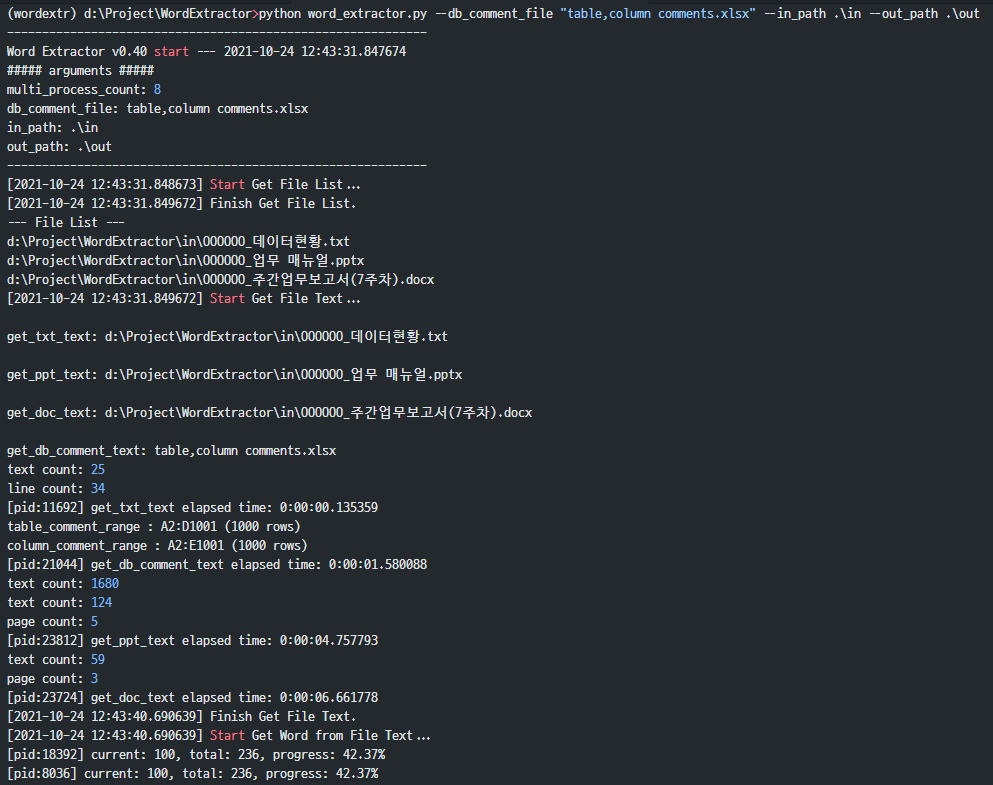
3.2.6. So überprüfen Sie Ausführungsergebnisse
Bei der Ausführung werden zwei Dateien (xlsx, png) in dem als Ausgabepfad festgelegten Ordner (\out) erstellt. Jahr, Monat, Stunde, Minute und Sekunde (YYYYMMDDHHMISS) werden automatisch dem Dateinamen zugeordnet, sodass Sie überprüfen können, wann er erstellt wurde.
Beispielsweise ist die im Ausgangsordner der komprimierten Verteilungsdatei enthaltene Ausführungsergebnisdatei wie folgt.
- extract_result_20210829111836.xlsx: Excel-Datei mit Ergebnis der Wortextraktion
- wordcloud_20210829111836.png: Bilddatei der Wortwolke, die mit dem Blatt „Worthäufigkeit“ der Excel-Datei des Ergebnisses der Wortextraktion erstellt wurde
Informationen zu Format und Inhalt der Ausführungsergebnisdatei finden Sie im folgenden Artikel.
1.3.3. Ausgabedaten des Wortextraktionswerkzeugs
3.2.7. Vorsichtsmaßnahmen/Hinweise zur Ausführung
- Wenn Sie MS-Word- oder PowerPoint-Anwendungen zuerst vor der Ausführung ausführen, wird die Ausführungsleistung geringfügig verbessert.
- Während der Ausführung wird die Datei in der MS-Word- oder PowerPoint-Anwendung geöffnet und nach der Verarbeitung geschlossen. Während der Wortextraktor ausgeführt wird, verwenden Sie nicht jede Anwendung und lassen Sie sie unverändert.
- Je mehr Dateien, je mehr Seiten in der Datei und je mehr Datenzeilen in der Excel-Kommentardatei vorhanden sind, desto länger ist die Ausführungszeit.
- Es empfiehlt sich zu testen, ob es gut funktioniert, indem Sie einen Teil der Eingabedatei und einen Teil der Daten der Kommentar-Excel-Datei separat speichern, bevor Sie das Ganze ausführen.
- Wenn man bedenkt, dass es lange dauern wird, das Ganze auszuführen, ist es besser, es während einer Mahlzeit oder Pause zu tun.
Dieser Artikel befasste sich mit der Verwendung des Wortextraktionstools. Bitte hinterlassen Sie einen Kommentar, wenn Sie Fragen zur Verwendung haben oder wenn Sie gute Funktionen hinzufügen möchten.
Der nächste Artikel wirft einen Blick auf den Quellcode.
<< Liste verwandter Artikel >>
- Wortextraktionstool(1): Überblick über das Wortextraktionstool
- Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
- Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
- Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
- Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
- Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
- Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
In Verbindung stehende Artikel:
 Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
 Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
 Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
 Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
 Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
 Wortextraktionstool(1): Überblick über das Wortextraktionstool
Wortextraktionstool(1): Überblick über das Wortextraktionstool
 Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_4.Attachment
Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_4.Attachment
 Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_3.Implementierung (2)
Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_3.Implementierung (2)










Hallo! Danke für den schönen Code
Ich habe eine Frage, wenn ich den Code mit einer pptx-Datei als Eingabe ausführe.
Ich habe das Extrahieren von Wörtern aus einer PPTX-Datei getestet.
Es gibt das Phänomen, dass ein leeres PPT-Fenster nicht geschlossen wird und schwebt, wenn der Code ausgeführt wird.
Bei Word, TXT und Excel gibt es kein ähnliches Phänomen.
Ich würde gerne nachfragen, ob es sich hierbei je nach Office-Version um ein vorübergehendes Phänomen handelt.
Umgebung ist
Ich verwende Windows 11, Office 365-Version.
Danke
Hallo, vielen Dank für Ihren Besuch und Ihre Kommentare.
Ich würde gerne mehr über die Situation von Kiyoung Kim erfahren.
Was ist der Fall?
1) Ein Phänomen, bei dem die PowerPoint-Anwendung „während der Codeausführung“ nicht reagiert und nicht mit der nächsten Datei fortfährt
2) Ein Phänomen, bei dem die PowerPoint-Anwendung geöffnet bleibt, ohne „nach“ der Codeausführung zu schließen
Wenn 1) der Fall ist,
– Wenn Sie PowerPoint im Task-Manager zwangsweise schließen, können Sie dann mit der nächsten Datei fortfahren?
– Es besteht die Möglichkeit, dass die aktuelle Datei nicht ordnungsgemäß verarbeitet wurde.
– Es wird empfohlen, die Aufgabe noch einmal von Anfang an auszuführen.
Wenn 2) der Fall ist,
– Es ist normal, dass die PowerPoint-Anwendung geöffnet bleibt, wenn Sie das Wortextraktionstool ausführen, nachdem Sie PowerPoint zuvor ausgeführt haben.
– Wenn Sie PowerPoint nicht ausgeführt haben, ist das ein seltsames Verhalten, aber wenn alle Dateien verarbeitet werden, brauchen Sie sich darüber keine Sorgen zu machen.
Als Referenz: Wenn Sie das Wortextraktionstool ausführen, ohne Anwendungen wie PowerPoint und Excel auszuführen, ist es normal, dass Anwendungen wie PowerPoint und Excel während des OLE-Automatisierungsprozesses ausgeführt und dann nach Abschluss der Verarbeitung beendet werden.
Ansonsten hinterlassen Sie bitte zusätzliche Kommentare.
Hallo, danke für die schnelle Antwort!
In meinem Fall 2) „nach“ der Codeausführung bleibt die PowerPoint-Anwendung geöffnet, ohne geschlossen zu werden.
Wie Sie sagten, scheint es sich um ein ungewöhnliches Verhalten zu handeln, da PowerPoint nicht im Voraus ausgeführt wurde.
Alle Dateien wurden ohne Auffälligkeiten verarbeitet.
Danke!
Vielen Dank, dass Sie uns über die Situation und die Ergebnisse informiert haben.
Bitte nutzen Sie es gut~ ^^
Hallo. Ich verwende dieses Tool derzeit, aber es funktioniert nicht. Ist es ein Problem mit Miniforge? Zuerst werde ich Miniconda in einer anderen Umgebung installieren und es erneut ausführen.
——————————————————————————————
(wordextr) C:\Benutzer\Benutzer\Downloads\word_extractor>python word_extractor.py –in_path .\in –out_path .\out
C:\Benutzer\Benutzer\Downloads\word_extractor\word_extractor.py:382: SyntaxWarning: ungültige Escape-Sequenz „\o“
use_description = „““ – Beschreibung –
C:\Benutzer\Benutzer\Downloads\word_extractor\word_extractor.py:406: SyntaxWarning: ungültige Escape-Sequenz „\i“
parser.add_argument('–in_path', erforderlich=False, help='Pfadname der Eingabedatei (ppt, doc, txt) (z. B. .\in) ')
C:\Benutzer\Benutzer\Downloads\word_extractor\word_extractor.py:407: SyntaxWarning: ungültige Escape-Sequenz „\o“
parser.add_argument('–out_path', erforderlich=True, help='Pfadname der Ausgabedatei (xlsx, png) (z. B. .\out)')
————————————————————
Start von Word Extractor v0.41 – 18.01.2024 17:36:57.283006
##### Argumente #####
multi_process_count: 16
db_comment_file: Keine
in_path: .\in
out_path: .\out
————————————————————
[18.01.2024 17:36:57.288351] Dateiliste abrufen starten…
[18.01.2024 17:36:57.289390] Dateiliste abrufen abschließen.
— Dateiliste —
[18.01.2024 17:36:57.290381] Dateitext abrufen starten…
Traceback (letzter Anruf zuletzt):
Datei „C:\Users\User\Downloads\word_extractor\word_extractor.py“, Zeile 559, in
hauptsächlich()
Datei „C:\Users\User\Downloads\word_extractor\word_extractor.py“, Zeile 461, im Hauptteil
df_text = pd.concat(mp_text_result,ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Datei „C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py“, Zeile 380, in concat
op = _Concatenator(
^^^^^^^^^^^^^^
Datei „C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py“, Zeile 443, in __init__
objs, Schlüssel = self._clean_keys_and_objs(objs, Schlüssel)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Datei „C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py“, Zeile 505, in _clean_keys_and_objs
raise ValueError („Keine Objekte zum Verketten“)
ValueError: Keine Objekte zum Verketten
Die Versionsinformationen lauten wie folgt
Python 3.12.1
Paketversion
————— ————
Konturpy 1.2.0
Cycler 0.12.1
Eunjeon 0.4.0
Fonttools 4.47.2
Jinja2 3.1.3
Kiwisolver 1.4.5
MarkupSafe 2.1.3
matplotlib 3.8.2
Numpy 1.26.3
Verpackung 23.2
Pandas 2.1.4
Kissen 10.2.0
Punkt 23.3.2
Pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
pywin32 306
setuptools69.0.3
sechs 1.16.0
tzdata 2023.4
Rad 0,42,0
Wordcloud 1.9.3
XlsxWriter 3.1.9
Dieser Fehler tritt auf, wenn im Eingabeverzeichnis keine Datei mit der unten angegebenen Erweiterung vorhanden ist.
– .ppt, .pptx
– .doc, .docx
- .txt
Ich habe es wie folgt getestet:
———————————————————————–
(.venv) D:\Temp\python_venv\wordextr_test>python –version
Python 3.11.1
(.venv) D:\Temp\python_venv\wordextr_test>python word_extractor.py –in_path .\in –out_path .\out
————————————————————
Start von Word Extractor v0.41 – 19.01.2024 08:55:44.842578
##### Argumente #####
multi_process_count: 8
db_comment_file: Keine
in_path: .\in
out_path: .\out
————————————————————
[19.01.2024 08:55:44.845602] Dateiliste abrufen starten…
[19.01.2024 08:55:44.845602] Dateiliste abrufen abschließen.
— Dateiliste —
[19.01.2024 08:55:44.845602] Dateitext abrufen starten…
Traceback (letzter Anruf zuletzt):
Datei „D:\Temp\python_venv\wordextr_test\word_extractor.py“, Zeile 164, in
hauptsächlich()
Datei „D:\Temp\python_venv\wordextr_test\word_extractor.py“, Zeile 152, in main
df_text = pd.concat(mp_text_result,ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Datei „D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py“, Zeile 380, in concat
op = _Concatenator(
^^^^^^^^^^^^^^
Datei „D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py“, Zeile 443, in __init__
objs, Schlüssel = self._clean_keys_and_objs(objs, Schlüssel)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Datei „D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py“, Zeile 505, in _clean_keys_and_objs
raise ValueError („Keine Objekte zum Verketten“)
ValueError: Keine Objekte zum Verketten
(.venv) D:\Temp\python_venv\wordextr_test>dir .\in
Volume auf Laufwerk D: Daten
Seriennummer des Bandes: D6EC-7CFE
D:\Temp\python_venv\wordextr_test\in Verzeichnis
18.01.2024 21:41 Uhr
18.01.2024 21:41 Uhr
0 Dateien 0 Bytes
2 Verzeichnisse, 34.305.060.864 Bytes übrig
Hallo. Ich verwende dieses Tool derzeit, erhalte jedoch ständig eine Fehlermeldung. Ich habe nachgeschaut und es scheint ein Problem mit der Pandas-Version zu sein. (Es scheint, dass die .appen-Funktion ab Pandas 2 nicht mehr bereitgestellt wird.) Oder handelt es sich um einen anderen Fehler?
(wordextr) C:\Benutzer\hyelm\Dokumente\word_extractor>python word_extractor.py. –db_comment_file „table_column_comments1.xlsx“ –out_path 'C:\Users\hyelm\Documents\word_extractor\out'
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:382: SyntaxWarning: ungültige Escape-Sequenz „\o“
use_description = „““ – Beschreibung –
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:406: SyntaxWarning: ungültige Escape-Sequenz „\i“
parser.add_argument('–in_path', erforderlich=False, help='Pfadname der Eingabedatei (ppt, doc, txt) (z. B. .\in) ')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:407: SyntaxWarning: ungültige Escape-Sequenz „\o“
parser.add_argument('–out_path', erforderlich=True, help='Pfadname der Ausgabedatei (xlsx, png) (z. B. .\out)')
————————————————————
Start von Word Extractor v0.41 – 29.04.2024 14:28:41.474667
##### Argumente #####
multi_process_count: 4
db_comment_file: table_column_comments1.xlsx
in_path: Keine
out_path: 'C:\Benutzer\hyelm\Dokumente\word_extractor\out'
————————————————————
[29.04.2024 14:28:41.479798] Dateitext abrufen starten…
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:382: SyntaxWarning: ungültige Escape-Sequenz „\o“
use_description = „““ – Beschreibung –
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:406: SyntaxWarning: ungültige Escape-Sequenz „\i“
parser.add_argument('–in_path', erforderlich=False, help='Pfadname der Eingabedatei (ppt, doc, txt) (z. B. .\in) ')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:407: SyntaxWarning: ungültige Escape-Sequenz „\o“
parser.add_argument('–out_path', erforderlich=True, help='Pfadname der Ausgabedatei (xlsx, png) (z. B. .\out)')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:382: SyntaxWarning: ungültige Escape-Sequenz „\o“
use_description = „““ – Beschreibung –
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:406: SyntaxWarning: ungültige Escape-Sequenz „\i“
parser.add_argument('–in_path', erforderlich=False, help='Pfadname der Eingabedatei (ppt, doc, txt) (z. B. .\in) ')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:407: SyntaxWarning: ungültige Escape-Sequenz „\o“
parser.add_argument('–out_path', erforderlich=True, help='Pfadname der Ausgabedatei (xlsx, png) (z. B. .\out)')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:382: SyntaxWarning: ungültige Escape-Sequenz „\o“
use_description = „““ – Beschreibung –
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:406: SyntaxWarning: ungültige Escape-Sequenz „\i“
parser.add_argument('–in_path', erforderlich=False, help='Pfadname der Eingabedatei (ppt, doc, txt) (z. B. .\in) ')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:407: SyntaxWarning: ungültige Escape-Sequenz „\o“
parser.add_argument('–out_path', erforderlich=True, help='Pfadname der Ausgabedatei (xlsx, png) (z. B. .\out)')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:382: SyntaxWarning: ungültige Escape-Sequenz „\o“
use_description = „““ – Beschreibung –
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:406: SyntaxWarning: ungültige Escape-Sequenz „\i“
parser.add_argument('–in_path', erforderlich=False, help='Pfadname der Eingabedatei (ppt, doc, txt) (z. B. .\in) ')
C:\Benutzer\hyelm\Dokumente\word_extractor\word_extractor.py:407: SyntaxWarning: ungültige Escape-Sequenz „\o“
parser.add_argument('–out_path', erforderlich=True, help='Pfadname der Ausgabedatei (xlsx, png) (z. B. .\out)')
get_db_comment_text: table_column_comments1.xlsx
table_comment_range: A2:D7112 (7111 Zeilen)
Column_comment_range: A2:E181935 (181934 Zeilen)
multiprocessing.pool.RemoteTraceback:
“”
Traceback (letzter Anruf zuletzt):
Datei „C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py“, Zeile 125, im Worker
result = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
Datei „C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py“, Zeile 48, in Mapstar
Rückgabeliste(map(*args))
^^^^^^^^^^^^^^^^
Datei „C:\Users\hyelm\Documents\word_extractor\word_extractor.py“, Zeile 369, in get_file_text
df_text = get_db_comment_text(file_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Datei „C:\Users\hyelm\Documents\word_extractor\word_extractor.py“, Zeile 343, in get_db_comment_text
df_text = df_column.append(df_table,ignore_index=True)
^^^^^^^^^^^^^^^^
Datei „C:\Users\hyelm\miniconda3\envs\wordextr\Lib\site-packages\pandas\core\generic.py“, Zeile 6296, in __getattr__
return object.__getattribute__(self, name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: Das „DataFrame“-Objekt hat kein Attribut „append“. Meinten Sie: '_append'?
“”
Die obige Ausnahme war die direkte Ursache für die folgende Ausnahme:
Traceback (letzter Anruf zuletzt):
Datei „C:\Users\hyelm\Documents\word_extractor\word_extractor.py“, Zeile 559, in
hauptsächlich()
Datei „C:\Users\hyelm\Documents\word_extractor\word_extractor.py“, Zeile 460, im Hauptteil
mp_text_result = pool.map(get_file_text, file_list)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Datei „C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py“, Zeile 367, in der Karte
return self._map_async(func, iterable, mapstar, chunksize).get()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Datei „C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py“, Zeile 774, in get
Selbstwert erhöhen
AttributeError: „DataFrame“-Objekt hat kein Attribut „append“
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: Das „DataFrame“-Objekt hat kein Attribut „append“. Meinten Sie: '_append'?
“”
Der Code im Kommentar oben wurde zu seltsam kopiert, daher belasse ich es wieder.
Tritt dieser Fehler aufgrund eines Problems mit der Pandas-Version auf?
Ab Pandas v2.0 wird append nicht mehr unterstützt, daher ist es richtig, zu concat zu wechseln.
Ich habe auf die beiden Dokumente unten verwiesen.
https://yunwoong.tistory.com/253
https://stackoverflow.com/questions/75956209/error-dataframe-object-has-no-attribute-append
Es fällt mir heutzutage schwer, Zeit zu finden, daher weiß ich nicht, wann ich den Quellcode ändern kann.
Möchten Sie bei der Installation von Pandas eine frühere Version angeben und installieren?
Ich hoffe, es geht gut~