Wortextraktionstool(1): Überblick über das Wortextraktionstool
Eine Übersicht über Wortextraktionswerkzeuge, die für die Datenstandardisierungsarbeit nützlich sein können, insbesondere für die Erstellung von Standardwortkandidaten.
1. Überblick über das Wortextraktionstool
1.1. Warum wir das Wortextraktionstool entwickelt haben
Unter den anfänglichen Aufgaben der Datenstandardisierung besteht die schwierigste Aufgabe darin, so viele Kandidaten wie möglich zu sammeln und schnell als Standardwörter zu registrieren. Tool zur Überprüfung von Datenstandards (siehe: Data Standard Check Tool_1.Übersicht) kann verwendet werden, um Standardwortkandidaten zu extrahieren, hat aber die folgenden Schwierigkeiten.
- Wenn die Datenbanktabelle, die Spaltenkommentardaten viele Sonderzeichen enthalten (Symbole wie #, $, %, ., \ usw. und Zeilentrennzeichen usw.), ist ein erheblicher Aufwand erforderlich, um sie zu entfernen oder zu verfeinern.
- Es ist schwierig, die Häufigkeit von Wörtern zu kennen, daher ist es schwierig zu bestimmen, ob nur einzelne Wörter, nur zusammengesetzte Wörter oder sowohl einzelne Wörter als auch zusammengesetzte Wörter registriert werden sollen.
- Wenn ein zusammengesetztes Wort später identifiziert wird, nachdem ein Standardwort bestätigt wurde, und sich auf den physikalischen Namen eines bereits registrierten Standardbegriffs auswirkt, können Ausnahmen von der Standardbenennungsregel die Verwaltung erschweren.
Das Wortextraktionstool wurde entwickelt, um einige dieser Schwierigkeiten zu lindern. Insbesondere hoffen wir, dass es in den folgenden Fällen hilfreich sein wird.
- Wenn es kein aktuelles Datenstandard-Wörterbuch gibt oder auch wenn die Anzahl der Standardwörter gering ist
- Ihr Job ist so einzigartig, dass es kein Datenstandard-Wörterbuch gibt, das als Referenz geeignet ist.
- Wenn die Datenbanktabelle und die Spaltenkommentare zu groß sind und das manuelle Extrahieren von Wörtern viel Zeit in Anspruch nimmt
- Oder umgekehrt, wenn Datenbanktabellen und Spaltenkommentare wenig Inhalt haben, ist es unangemessen, Standardwörter zu extrahieren, und es ist angebracht, sie aus Dokumenten wie Arbeitshandbüchern zu extrahieren.
- Außerdem, wenn Wörter und Häufigkeiten aus Dokumenten extrahiert werden müssen
1.2. Wortextraktionstool-Konzept
Das Wortextraktionstool ist ein Tool, das verschiedene Arten von Dateien als Eingabe empfängt, Wörter und zusammengesetzte Wörter mithilfe eines Morphemanalysators zur Verarbeitung natürlicher Sprache extrahiert und die Häufigkeit und Quelle (Dateiname, Tabellenname, Spaltenname usw.) als ausgibt Excel-Datei.
Mecab, ein koreanischer Morphemanalysator für die Verarbeitung natürlicher Sprache (NLP), wurde in Python v3.8 verwendet und entwickelt. Kkma, Komoran, Hannanum, Okt (früher bekannt als Twitter) und Mecab sind repräsentative Bibliotheken unter den koreanischen Morphem-Analysatoren für die Verarbeitung natürlicher Sprache. Unter ihnen wurde Mecab ausgewählt, weil es die beste Leistung hat.
Den Leistungsvergleich von Morphem-Analysatoren für die Verarbeitung natürlicher Sprache finden Sie unter dem folgenden Link.
Bezug: https://konlpy.org/ko/latest/morph/#comparison-between-pos-tagging-classes
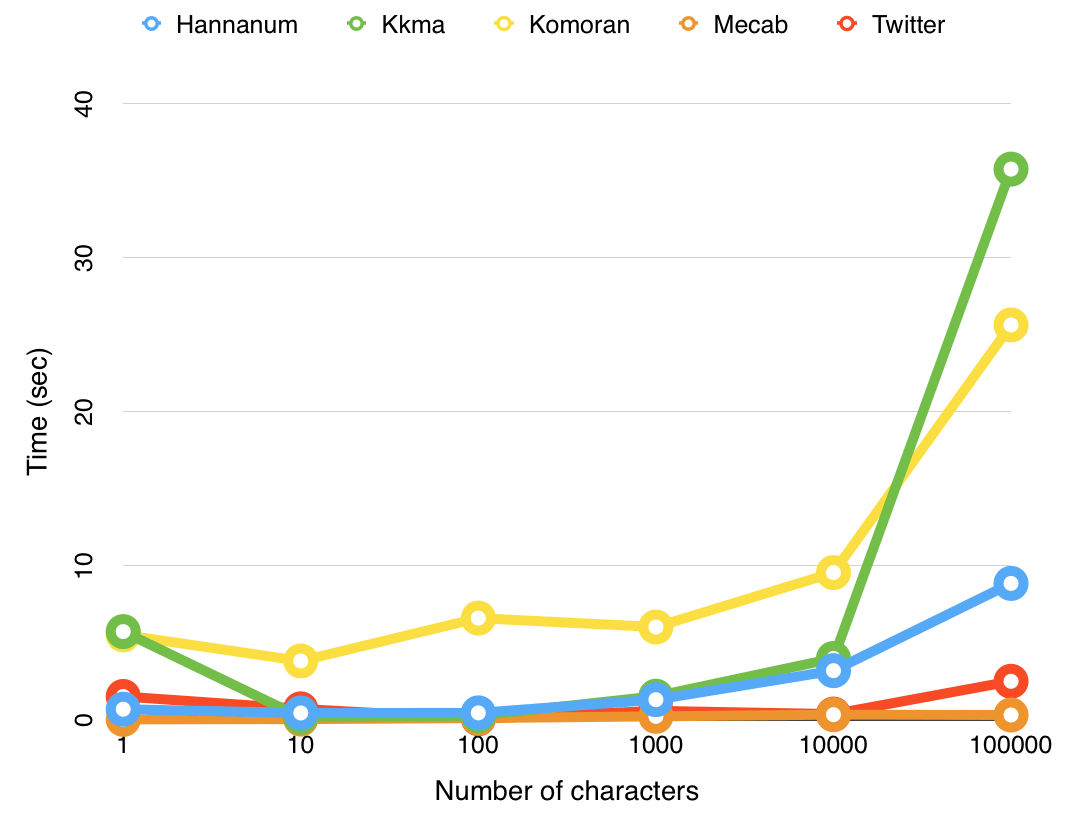
Die Ausführungszeit gemäß der Erhöhung der Anzahl eingegebener Zeichen kann wie folgt zusammengefasst werden. (Die Ausführungszeit verringert sich und die Leistung verbessert sich, wenn Sie von links nach rechts gehen.)
Kkma > Komoran > Hannanum > Okt (Twitter) > Mecab
Als Referenz dient der obige Link KoNLPy-PaketDies ist die Website der Person, die sie entwickelt hat. KoNLPyist ein Python-basiertes Paket, das mehrere Morphem-Analysatoren in einem bündelt.
KoNLPy: https://konlpy.org/ko/latest/
1.3. Wie der Wortextraktor funktioniert
Sehen Sie sich kurz Eingangsdaten, Verarbeitungslogik und Ausgangsdaten an.
1.3.1. Eingabematerial für das Wortextraktionstool
Eingabedaten können auf eine oder beide der folgenden beiden Arten angegeben werden.
- Dokumente: MS Word, PowerPoint, Textdateien
- Zum Zeitpunkt der Erstellung dieses Artikels (29.08.2021) werden HWP- und PDF-Formate noch nicht unterstützt.
- DB-Tabelle, Spaltenkommentar Quelle: Excel-Datei
- Datenelemente für Tabellenkommentare: Datenbank, Schema, Tabellenname, Tabellenkommentar
- Spaltenkommentar-Datenelemente: Datenbank, Schema, Tabellenname, Tabellenkommentar, Spaltenname, Spaltenkommentar
▼ Ein Beispiel für Tabellenkommentardaten ist wie folgt.
| Datenbank | Schema | Tabellenname | Tabellenkommentar |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | Verwaltungscode |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODERECPTNLOG | Protokoll des Empfangs des Verwaltungscodes |
| DB1 | EIGENTÜMER1 | COMTCCMNCLCODE | Gemeinsamer Klassifizierungscode |
| DB1 | EIGENTÜMER1 | COMTCCMNCODE | gemeinsamen Code |
| DB1 | EIGENTÜMER1 | COMTCCMNDETAILCODE | Gemeinsamer Detailcode |
▼ Beispiele für Spaltenkommentardaten sind wie folgt. Dies ist die Spaltenliste von COMTCADMINISTCODE (Verwaltungscode) in der obigen Tabellenliste.
| Datenbank | Schema | Tabellenname | Spaltenname | Spalte Kommentar |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE | Einteilung des Verwaltungsbezirks |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE | Verwaltungsbezirkscode |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | USE_AT | Ob zu verwenden oder nicht |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM | Name des Landkreises |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | UPPER_ADMINIST_ZONE_CODE | Kodex des oberen Verwaltungsbezirks |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | CREAT_DE | Erstellungsdatum |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ABL_DE | Abschaffungsdatum |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | FRST_REGIST_PNTTM | Erstanmeldung |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | FRST_REGISTER_ID | ID des ursprünglichen Registranten |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | LAST_UPDT_PNTTM | Zeit der letzten Änderung |
| DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | LAST_UPDUSR_ID | Zuletzt geänderte ID |
* Die obigen Beispieldaten wurden unter Verwendung der Tabellen- und Spaltenkommentarskripte auf der Seite „Gemeinsame Komponententabellen-Konfigurationsinformationen“ des E-Government-Standardrahmens v3.8 erstellt.
(Quelle: https://www.egovframe.go.kr/wiki/doku.php?id=egovframework:com:v3.8:init_table)
1.3.2. Verarbeitungslogik des Wortextraktionstools
Eine kurze Zusammenfassung der gesamten Verarbeitungslogik ist wie folgt.
- Extrahieren Sie Text (zeilenweise, Tabelle/Spalte), indem Sie Eingabedaten sequentiell öffnen
- Extraktion von Wortkandidaten in Form von 1 Substantiv, n Substantiven, Präfix + n Substantiven, n Substantiven + Suffixen, Präfix + n Substantiven + Suffixen mit Mecab, einem Morphemanalysepaket für natürliche Sprache
- Ermitteln Sie die Häufigkeit von Wörtern, die aus den gesamten Eingabedaten extrahiert wurden, und speichern Sie das Ergebnis der Wortextraktion als Ausgabedatei
- Erstellen und speichern Sie eine Wortwolke als PNG-Datei mit Wortliste und Häufigkeit
- Gibt die erforderliche Gesamtzeit aus und beendet sich
Ein vereinfachtes Diagramm des obigen Prozesses ist wie folgt.
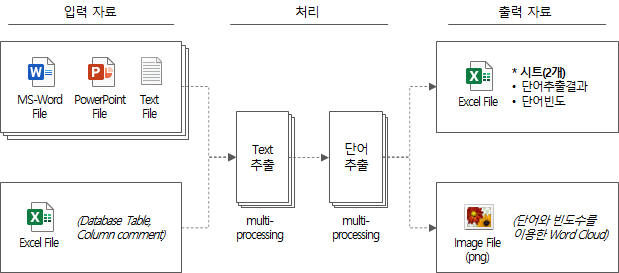
1.3.3. Ausgabedaten des Wortextraktionswerkzeugs
Die Ausgabedaten, die das Ergebnis der Verarbeitung der Eingabedaten sind, sind eine Excel-Datei und eine Bilddatei (png) in Form einer Wortwolke.
Die Excel-Datei besteht aus zwei Blättern. Das Folgende ist ein Beispiel für DB-Tabellen- und Spaltenkommentardaten als Eingabe.
▼ Blatt „Beispiel für das Ergebnis der Wortextraktion“.
| Nein | Wort | Dateiname | Dateityp | Buchseite | Text | DB | Schema | Tisch | Spalte |
| 1 | Verwaltung | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Einteilung des Verwaltungsbezirks | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 2 | Bereich | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Einteilung des Verwaltungsbezirks | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 3 | Einteilung | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Einteilung des Verwaltungsbezirks | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 4 | Administrative Teilung [Zusammensetzung] | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Einteilung des Verwaltungsbezirks | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 5 | Verwaltung | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Verwaltungsbezirkscode | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 6 | Bereich | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Verwaltungsbezirkscode | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 7 | Code | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Verwaltungsbezirkscode | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 8 | Landkreiskennzahl [Kompositum] | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Verwaltungsbezirkscode | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 9 | verwenden | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Ob zu verwenden oder nicht | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | USE_AT |
| 10 | Ob | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Ob zu verwenden oder nicht | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | USE_AT |
| 11 | Ob [zusammengesetztes Wort] verwendet werden soll | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Ob zu verwenden oder nicht | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | USE_AT |
| 12 | Region | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Name des Landkreises | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 13 | Stationsname | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Name des Landkreises | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 14 | Landkreisname [Kompositum] | Tabelle, Spalte Kommentare.xlsx | Säule | 0 | Name des Landkreises | DB1 | EIGENTÜMER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
- Spalte „Text“: Dies ist der ursprüngliche Wert, der aus den Eingabedaten extrahiert wurde, und entspricht in diesem Beispiel der Tabelle, dem Spaltenkommentar.
- Spalte „Wort“: Wortkandidaten, die mit Mecab aus Text extrahiert wurden. Geben Sie für zusammengesetzte Wörter „[zusammengesetztes Wort]“ als Suffix an.
- Zeile 12 „Verwaltungsbezirk“, Zeile 13 „Stationsname“ sind Wörter, die aus „Verwaltungsname“ in Mecab extrahiert wurden.
- Es ist ersichtlich, dass die Genauigkeit nicht 100% ist, weil sie anders als das tatsächlich verwendete Wort extrahiert wird.
▼ Beispielblatt „Worthäufigkeit“.
| Wort | Freq | Quelle |
| Code | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE (administrativer Zonencode) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE (Identifikationscode ändern) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE (Versuchscode) … |
| Anzahl | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(Auftragsseriennummer) DB1.OWNER1.COMTCZIP.ZIP (Postleitzahl) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO (Genehmigungsnummer) … |
| Anzahl der Personen | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM (Adressbuchname) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM (Klassifizierungscodename) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM (Codename) … |
| Arbeit | 85 | DB1.OWNER1.COMTCADMINISTCODE.CREAT_DE(Erstellungsdatum) DB1.OWNER1.COMTCADMINISTCODE.ABL_DE (Austrittsdatum) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OCCRRNC_DE(Auftrittsdatum) … |
| Information | 77 | DB1.OWNER1.COMTHDBMNTRNGLOGINFO.LOG_INFO (Protokollinformationen) DB1.OWNER1.COMTNBACKUPRESULT.ERROR_INFO (Fehlerinformationen) DB1.OWNER1.COMTNINDVDLINFOPOLICY.INDVDL_INFO_POLICY_ID (Datenschutzrichtlinien-ID) … |
| Ob | 75 | DB1.OWNER1.COMTCADMINISTCODE.USE_AT (ob zu verwenden) DB1.OWNER1.COMTNANNVRSRYMANAGE.REPTIT_AT (ob zu wiederholen) DB1.OWNER1.COMTNBANNER.REFLCT_AT (ob reflektiert werden soll) … |
- Spalte „Wort“: Dies ist ein Zeichenfolgenwert, der durch Entfernen von Duplikaten aus der Spalte „Wort“ des Blatts „Ergebnis der Wortextraktion“ erhalten wird. Dieser Wert ist ein Kandidat, der als Standardwort registriert werden soll.
- Spalte „Häufigkeit“: Dies ist die Häufigkeitszählung, die angibt, wie oft das Wort verwendet wurde. Die resultierende Liste wird in umgekehrter Reihenfolge von diesen hochfrequenten Wörtern zu den niederfrequenten Wörtern sortiert.
- Spalte „Quelle“: Zeigt die Quelle des Wortes an. Zeigt bis zu 10 Quellen an.
- Wenn die Quelle eine Tabelle ist, lautet das Format: DB.Schema.TableName(Tabellenkommentar)
- Wenn die Quelle Spalte ist, lautet das Format: DB.Schema.TableName.ColumnName(Spaltenkommentar)
- Wenn die Quelle Dateiformat ist: Dateiname:Seitennummer:Text
Ein Beispiel für ein Wortwolkenbild, das durch die Häufigkeit von extrahierten Wörtern erzeugt wird, ist wie folgt. Wörter mit hoher Häufigkeit werden groß angezeigt.

Das Wortextraktionstool ist ein in Python entwickeltes Tool, und vor der Ausführung ist ein Umgebungskonfigurationsprozess wie das Installieren von Python und den erforderlichen Paketen erforderlich. Als Nächstes sehen wir uns den Umgebungskonfigurationsprozess an.
<< Liste verwandter Artikel >>
- Wortextraktionstool(1): Überblick über das Wortextraktionstool
- Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
- Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
- Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
- Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
- Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
- Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
In Verbindung stehende Artikel:
 Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
Vollständiger Inhalt der Beschreibung des Word Extraction Tools, Download
 Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
Wortextraktionstool (6): Zusätzliche Beschreibung des Wortextraktionstools
 Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
Wortextraktionstool(5): Beschreibung des Quellcodes des Wortextraktionstools(2)
 Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
Wortextraktionstool(4): Beschreibung des Quellcodes des Wortextraktionstools(1)
 Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
Wortextraktionstool (3): So führen Sie das Wortextraktionstool aus und überprüfen die Ergebnisse
 Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
Word-Extraktionstool (2): Konfigurieren Sie die Ausführungsumgebung des Word-Extraktionstools
 Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_4.Attachment
Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_4.Attachment
 Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_3.Implementierung (2)
Optimierung der Arbeitsverteilung durch eindimensionalen Bin-Packing-Algorithmus_3.Implementierung (2)









