3. NUMBER Spaltenpartitionsmethode Parallelverarbeitungsfall (DBMS_PARALLEL_EXECUTE)
Veröffentlicht
· Aktualisiert
Schauen wir uns einen Fall der Parallelverarbeitung der NUMBER-Spaltenpartitionierungsmethode mit Oracle DBMS_PARALLEL_EXECUTE an. Es umfasst die Erstellung von Aufgaben, die Aufteilung von Arbeitseinheiten, die Ausführung von Aufgaben, die Bestätigung des Abschlusses von Aufgaben und das Löschen.
Dies ist eine Fortsetzung des vorherigen Artikels.
3. NUMBER Column Split Methode Parallelverarbeitungsfall
Schauen wir uns ein Beispiel für die Divisionsmethode durch NUMBER Column an. Sie ähnelt fast der ROWID-Methode, die folgenden Elemente unterscheiden sich jedoch geringfügig.
Verwenden Sie beim Teilen von Arbeitseinheiten die Prozedur CREATE_CHUNKS_BY_NUMBER_COL.
Beim Ausführen einer Aufgabe wird die Spalte NUMBER in der WHERE-Klausel der SQL-Anweisung verwendet.
Es gibt keinen Unterschied darin, wie Sie eine Aufgabe erstellen.
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
-- 작업 생성 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_TASKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)';
3.2. Geteilte Arbeitseinheit
CREATE_CHUNKS_BY_NUMBER_COL( ,
,
,
, ), um die Arbeitseinheit zu teilen.
Führen Sie die folgenden Schritte aus, um einen Block zu erstellen, der basierend auf der Spalte „ID“ der Tabelle Z_DPE_TEST_TAB in 10.000 Fälle unterteilt ist.
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_NUMBER_COL (
TASK_NAME => 'DPE_TEST(BY NUMBER)',
TABLE_OWNER => USER,
TABLE_NAME => 'Z_DPE_TEST_TAB',
TABLE_COLUMN => 'ID',
CHUNK_SIZE => 10000);
END;
Lassen Sie uns den Teilungsstatus der Arbeitseinheit überprüfen.
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
ORDER BY START_ID;
Arbeitsteilungsstatus
Wie Sie den obigen Ergebnissen grob entnehmen können, wurde jeder Block in 10.000 Zeilen unterteilt. (Die Beispieltabelle wurde mit ID-Werten unter Verwendung fortlaufender Nummern von 1 bis 1 Million erstellt.)
Als Referenz: Beim Teilen einer ROWID (CREATE_CHUNKS_BY_ROWID-Prozedur) werden Werte in START_ROWID und END_ROWID erstellt, und beim Teilen einer NUMBER-Spalte (CREATE_CHUNKS_BY_NUMBER_COL) werden Werte in START_ID und END_ID erstellt.
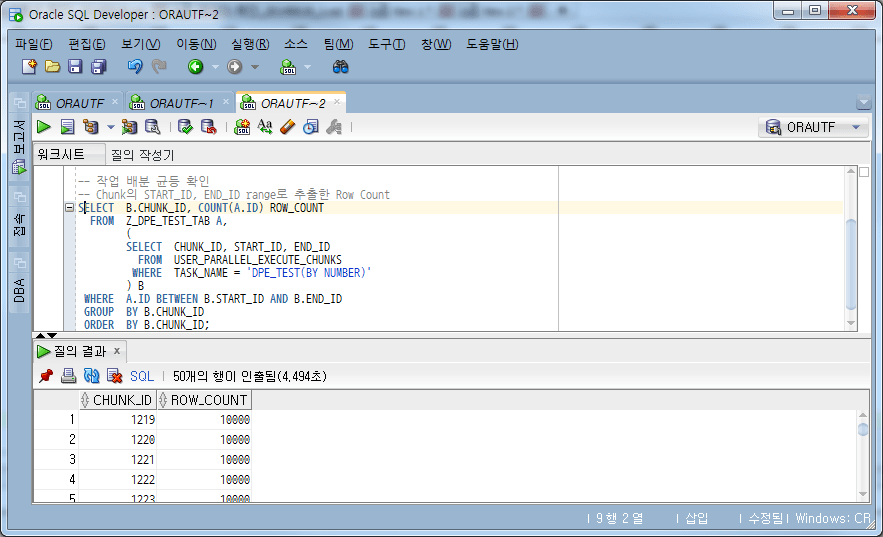
Überprüfen wir, ob die Arbeitseinheiten (Chunks) gleichmäßig verteilt sind.
-- 작업 분할 균등 확인
-- Chunk의 START_ID, END_ID range로 추출한 Row Count
SELECT B.CHUNK_ID, COUNT(A.ID) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID
ORDER BY B.CHUNK_ID;
Achten Sie auf eine gleichmäßige Arbeitsteilung
Wenn Sie die Anzahl der Fälle in der Tabelle anhand der START_ID und END_ID jedes Blocks überprüfen, ist sie gut in 10.000 Fälle unterteilt.
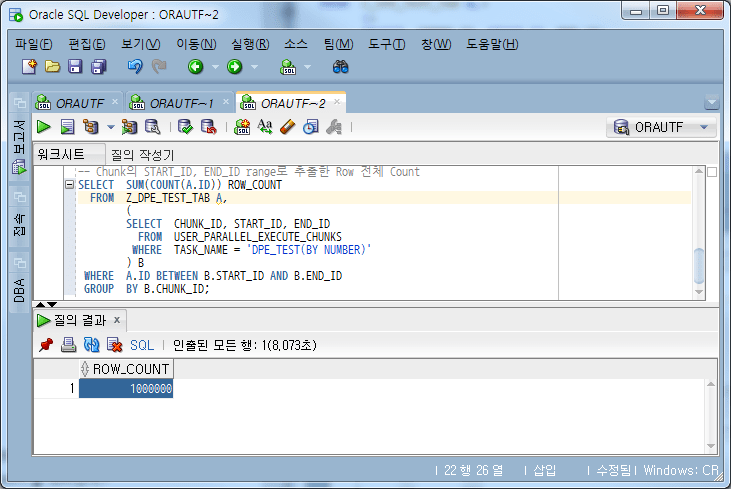
-- Chunk의 START_ID, END_ID range로 추출한 Row 전체 Count
SELECT SUM(COUNT(A.ID)) ROW_COUNT
FROM Z_DPE_TEST_TAB A,
(
SELECT CHUNK_ID, START_ID, END_ID
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
) B
WHERE A.ID BETWEEN B.START_ID AND B.END_ID
GROUP BY B.CHUNK_ID;
Überprüfen Sie die Summe der Blockzeilenanzahl
Die Gesamtzeilenanzahl aller Blöcke beträgt 1.000.000, was der Gesamtzahl der Daten entspricht.
3.3. Job ausgeführt
RUN_TASK( , , , ), um die Aufgabe auszuführen. Die Aufgabenausführungsmethode ist dieselbe wie die ROWID-Methode.
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'UPDATE Z_DPE_TEST_TAB
SET VAL = ROUND(DBMS_RANDOM.VALUE(1,10000))
,AUDSID = SYS_CONTEXT(''USERENV'',''SESSIONID'')
WHERE ID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 10);
END;
/
Das ausgeführte SQL ist fast das gleiche wie beim ROWID-Partitionsfall, der Unterschied besteht jedoch darin, dass die Bedingungsspalte in der WHERE-Klausel nicht „ROWID“, sondern „ID“ ist, was die festgelegte NUMBER-Spalte ist.
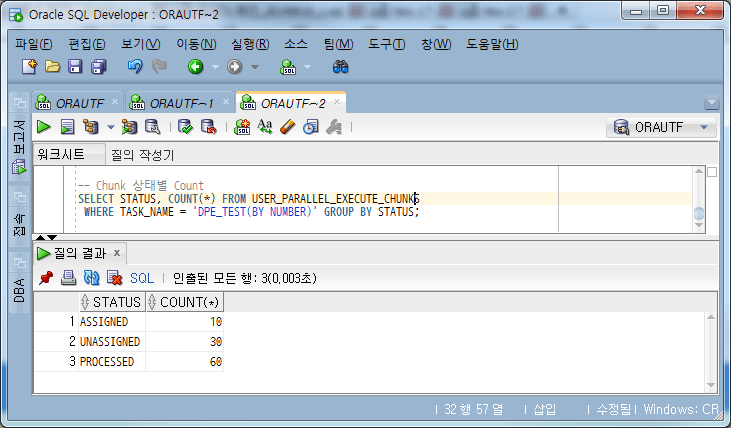
Schauen wir uns die Statusänderungen des Chunks während der Ausführung an.
-- Chunk 상태별 Count
SELECT STATUS, COUNT
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY NUMBER)'
GROUP BY STATUS;
Bei laufender Arbeit wird der Status des Chunks in „UNASSIGNED -> ASSIGNED -> PROCESSED“ geändert und wie folgt verarbeitet.
Überprüfen Sie den Chunk-Status, während die Aufgabe ausgeführt wird
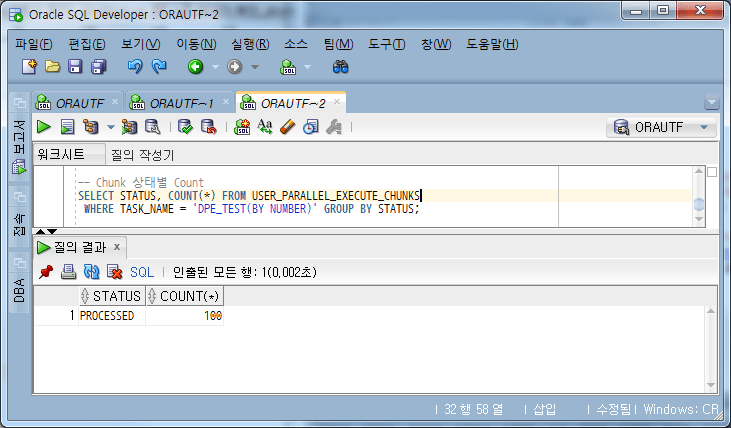
Wenn die Aufgabe abgeschlossen ist, wird der Status aller Chunks als BEARBEITET angezeigt.
Überprüfen Sie den Status des Aufgabenabschlussblocks
Nach Abschluss der Aufgabe können Sie überprüfen, wie viele Zeilen in welchen Sitzungen aktualisiert wurden, indem Sie die folgende SQL ausführen.
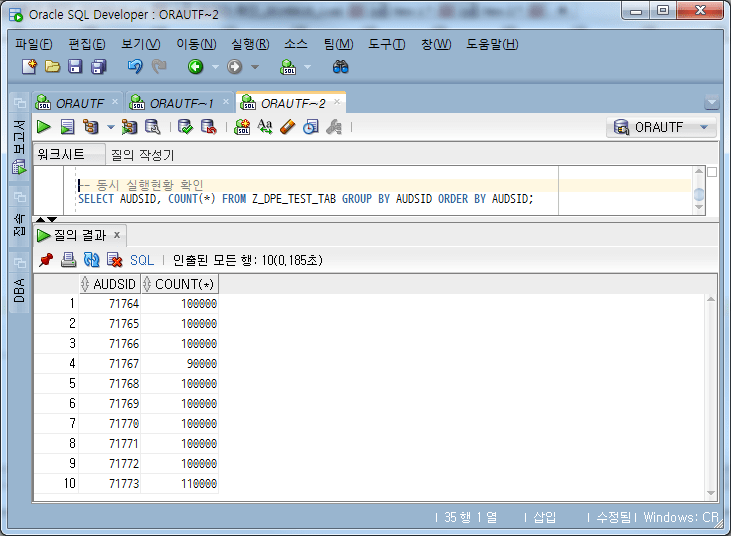
-- 동시 실행현황 확인
SELECT AUDSID, COUNT(*)
FROM Z_DPE_TEST_TAB
GROUP BY AUDSID
ORDER BY AUDSID;
Überprüfen Sie die Anzahl der pro Sitzung verarbeiteten Daten
Aus den obigen Inhalten können wir Folgendes erkennen:
Insgesamt wurden 10 Jobsitzungen durchgeführt.
Jeder Jobsitzung wurden 10.000 Chunks zugewiesen, meist jeweils 10.
AUDSID: 71767 Jobsitzung wurde mit 9 zugewiesenen Blöcken (90.000 Fälle) ausgeführt, und AUDSID: 71773 Jobsitzung wurde mit 11 Blöcken (110.000 Fälle) zugewiesen und ausgeführt.
Mit anderen Worten: Die Anzahl der RUN_TASK ist größer als die Gesamtanzahl der Chunks (hier 100). Wenn dieser klein ist, werden einem Job mehrere Blöcke zugewiesen und ausgeführt, und die Anzahl der Ausführungen kann variieren, selbst wenn der Grad der Aufteilung der Blöcke gleichmäßig ist.
3.4. Aufgabenabschluss bestätigen und löschen
DROP_TASK( ), um den Auftrag zu löschen.
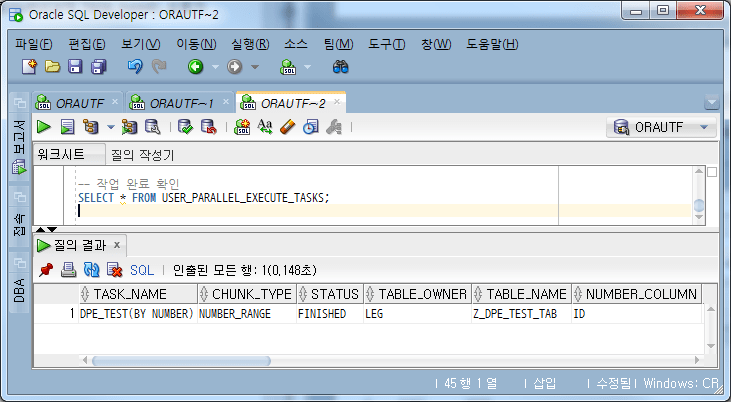
-- 4단계: 작업 완료 확인 및 작업 삭제
-- 작업 완료 확인
SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
-- 작업 삭제
BEGIN
DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY NUMBER)');
END;
/
Bestätigen Sie den Abschluss der Aufgabe
Bisher haben wir uns Beispiele für die Parallelverarbeitung mit der NUMBER-Spaltendivisionsmethode angesehen. Als nächstes schauen wir uns ein Beispiel einer Partitionierung auf Basis von benutzerdefiniertem SQL an.