Oracle-Zeichensatzkonvertierung (3): 3. Konfiguration der Client-Umgebung (2)
Als Fortsetzung des vorherigen Artikels betrachten wir die Konfiguration der Clientumgebung für die Oracle-Zeichensatzkonvertierung. Oracle Server Character Set und Client NLS_LANG empfohlene vier Konfigurationen können überprüft werden.
3.2. Zusammenfassung der Ergebnisse der Testfallausführung
vorherigen Post Oracle-Zeichensatzkonvertierung (2): 3. Konfigurieren der Client-Umgebung (1)Die Ausführungsergebnisse jedes Testfalls werden wie folgt zusammengefasst.
| Fall # | Server Zeichensatz | Client NLS_LANG | Wert | Eingang | ENTSORGEN Wert | |
|---|---|---|---|---|---|---|
| 1 | US7ASCII | KO16KSC5601 | 'Koreanisch' | Erfolg | Fraktur | Typ=1 Länge=2 Zeichensatz=US7ASCII: 3f,3f |
| 'scharf' | Versagen | - | - | |||
| 2 | US7ASCII | KO16MSWIN949 | 'Koreanisch' | Erfolg | Fraktur | Typ=1 Länge=2 Zeichensatz=US7ASCII: 3f,3f |
| 'scharf' | Erfolg | Fraktur | Typ=1 Länge=1 Zeichensatz=US7ASCII: 3f | |||
| 3 | US7ASCII | US7ASCII | 'Koreanisch' | Erfolg | normal | Typ=1 Länge=4 Zeichensatz=US7ASCII: c7,d1,b1,db |
| 'scharf' | Erfolg | normal | Typ=1 Länge=2 Zeichensatz=US7ASCII: 98,de | |||
| 4 | KO16MSWIN949 | KO16KSC5601 | 'Koreanisch' | Erfolg | normal | Typ=1 Länge=4 Zeichensatz=KO16MSWIN949: c7,d1,b1,db |
| 'scharf' | Versagen | - | - | |||
| 5 | KO16MSWIN949 | KO16MSWIN949 | 'Koreanisch' | Erfolg | normal | Typ=1 Länge=4 Zeichensatz=KO16MSWIN949: c7,d1,b1,db |
| 'scharf' | Erfolg | normal | Typ=1 Länge=2 Zeichensatz=KO16MSWIN949: 98,de | |||
| 6 | KO16MSWIN949 | US7ASCII | 'Koreanisch' | Erfolg | Fraktur | Typ=1 Länge=4 Zeichensatz=KO16MSWIN949: 3f,3f,3f,3f |
| 'scharf' | Erfolg | Fraktur | Typ=1 Länge=2 Zeichensatz=KO16MSWIN949: 3f,3f | |||
| 7 | AL32UTF8 | KO16KSC5601 | 'Koreanisch' | Erfolg | normal | Typ=1 Len=6 Zeichensatz=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'scharf' | Versagen | - | - | |||
| 8 | AL32UTF8 | KO16MSWIN949 | 'Koreanisch' | Erfolg | normal | Typ=1 Len=6 Zeichensatz=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'scharf' | Erfolg | normal | Typ=1 Len=3 Zeichensatz=AL32UTF8: ec,83,be | |||
| 9-1 | AL32UTF8 | AL32UTF8 (Befehl) | 'Koreanisch' | Versagen | - | - |
| 'scharf' | Versagen | - | - | |||
| 9-2 | AL32UTF8 | AL32UTF8 (Power Shell) | 'Koreanisch' | Erfolg | normal | Typ=1 Len=6 Zeichensatz=AL32UTF8: ed,95,9c,ea,b8,80 |
| 'scharf' | Erfolg | normal | Typ=1 Len=3 Zeichensatz=AL32UTF8: ec,83,be |
3.3 Oracle Server Zeichensatz und Client NLS_LANG Empfohlene Konfiguration
Die Konfiguration der Oracle Server- und Client-Umgebung für die Hangul-Eingabe/Ausgabe ist in den folgenden vier Kombinationen möglich.
| Fall # | Server Zeichensatz | Klient NLS_LANG | Kommentar |
| 3 | US7ASCII | US7ASCII | benutze es niemals Nur verwenden, wenn Sie die bestehende Umgebung nicht ändern können!!! |
| 5 | KO16MSWIN949 | KO16MSWIN949 | Speichert und gibt nur koreanische Zeichen, englische Zeichen, Zahlen, Sonderzeichen, chinesische Zeichen usw. ein und ein und aus, die unter koreanischem Windows unterstützt werden (mehrsprachige Zeichen können nicht auf dem Server gespeichert werden) |
| 8 | AL32UTF8 | KO16MSWIN949 | Wird verwendet, wenn der Server eine mehrsprachige Umgebung ist und der Client nur Koreanisch ein- und ausgibt. Kann verwendet werden, wenn die Clientanwendung Unicode nicht verarbeiten kann |
| 9 | AL32UTF8 | AL32UTF8 | Der im Server gespeicherte Wert wird unverändert ohne Konvertierung an den Client übertragen. Das heißt, der Client muss UTF8-codierte Daten direkt verarbeiten. |
Fall #3 scheint kein Problem mit der Ein-/Ausgabe zu haben, aber wenn Sie sich den Dump-Wert ansehen, können Sie sehen, dass der Zeichensatz US7ASCII ist. Das bedeutet, dass die tatsächliche Eingabe/Ausgabe in Einheiten von 1 Byte von US7ASCII ausgeführt und falsch gespeichert wird.
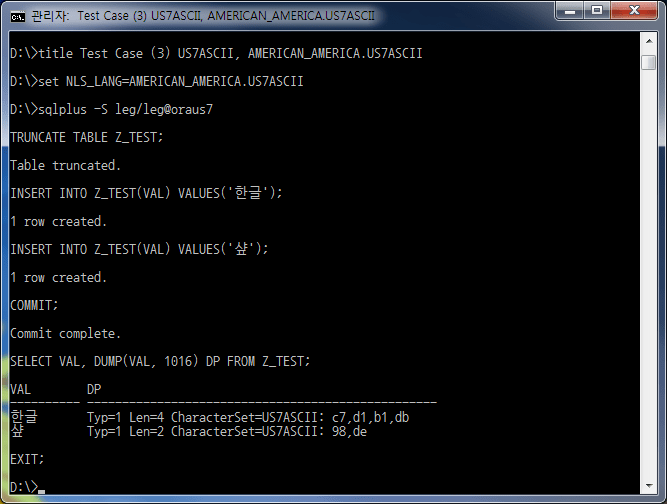
Wenn diese Daten über EAI, ETL, ESB usw. an ein externes System übertragen werden, werden Hangul-Zeichen unterbrochen, und es ist schwierig, Daten genau auszutauschen. Daher ist Fall #3 eine Einstellung, die unbedingt vermieden werden sollte.
Fall 9-1 ist ein Phänomen, das auftritt, weil Unicode-Eingabe/Ausgabe in cmd.exe, einer Windows-Eingabeaufforderung, nicht unterstützt wird, obwohl die ursprünglichen Eingabe- und Ausgabeeinstellungen keine Probleme aufweisen.
Wenn Sie Fall 9-2 in Windows PowerShell überprüfen, können Sie sehen, dass die Eingabe/Ausgabe normal ist.
Um zusätzlich zu Koreanisch mehrsprachige Zeichen wie chinesische Zeichen, japanische Zeichen, thailändische Zeichen und westeuropäische Zeichen zu speichern, sind die folgenden zwei Kombinationen möglich.
| Fall # | Server Zeichensatz | Klient NLS_LANG | Kommentar |
| 8 | AL32UTF8 | Je nach Sprachzeichen einstellen | Client-NLS_LANG-Einstellung – Bei Koreanisch: KO16MSWIN949 – Chinesische Schriftzeichen: ZHS16GBK oder ZHT16MSWIN950 oder ZHT16HKSCS – Japanische Zeichen: JA16SJIS – Thailändische Schriftzeichen: TH8TISASCII usw. Siehe Tabelle unten |
| 9 | AL32UTF8 | AL32UTF8 | Der im Server gespeicherte Wert wird unverändert ohne Konvertierung an den Client übertragen. Das heißt, der Client muss UTF8-codierte Daten direkt verarbeiten. |
Die Liste der oben erwähnten Client-NLS_LANG-Werte <je nach Sprachzeichen festgelegt> lautet wie folgt.
| Gebietsschema des Betriebssystems | NLS_LANG-Wert |
| Arabisch (VAE) | ARABIC_UNITED ARAB EMIRATES.AR8MSWIN1256 |
| bulgarisch | BULGARIAN_BULKARIA.CL8MSWIN1251 |
| katalanisch | CATALAN_CATALONIA.WE8MSWIN1252 |
| Chinesisch (VR China) | VEREINFACHTES CHINESISCH_CHINA.ZHS16GBK |
| Chinesisch (Taiwan) | TRADITIONELLES CHINESISCH_TAIWAN.ZHT16MSWIN950 |
| Chinesisch (Hongkong HKCS) | TRADITIONELLES CHINESISCH_HONGKONG.ZHT16HKSCS |
| Chinesisch (Hongkong HKCS2001) | TRADITIONELLES CHINESISCH_HONGKONG.ZHT16HKSCS2001 (neu in 10gR1) |
| kroatisch | CROATIAN_CROATIA.EE8MSWIN1250 |
| Tschechisch | CZECH_CZECH REPUBLIC.EE8MSWIN1250 |
| dänisch | DÄNISCH_DÄNEMARK.WE8MSWIN1252 |
| Niederländisch (Niederlande) | DUTCH_DIE NIEDERLANDE.WE8MSWIN1252 |
| Niederländisch (Belgien) | DUTCH_BELGIUM.WE8MSWIN1252 |
| Englisches Vereinigtes Königreich) | ENGLISH_UNITED KINGDOM.WE8MSWIN1252 |
| Englisch (USA) | AMERIKAnisch_AMERIKA.WE8MSWIN1252 |
| estnisch | ESTONIAN_ESTLAND.BLT8MSWIN1257 |
| finnisch | FINNISCH_FINNLAND.WE8MSWIN1252 |
| Französisch (Kanada) | KANADISCHES FRANZÖSISCH_KANADA.WE8MSWIN1252 |
| Französisch Frankreich) | FRANZÖSISCH_FRANKREICH.WE8MSWIN1252 |
| Deutsches Deutschland) | GERMAN_GERMANY.WE8MSWIN1252 |
| griechisch | GREEK_GREECE.EL8MSWIN1253 |
| hebräisch | HEBRÄI_ISRAEL.IW8MSWIN1255 |
| ungarisch | UNGARN_UNGARN.EE8MSWIN1250 |
| isländisch | ICELANDIC_ICELAND.WE8MSWIN1252 |
| Indonesisch | INDONESIAN_INDONESIA.WE8MSWIN1252 |
| Italienisch (Italien) | ITALIENISCH_ITALIEN.WE8MSWIN1252 |
| japanisch | JAPANESE_JAPAN.JA16SJIS |
| Koreanisch | KOREAN_KOREA.KO16MSWIN949 |
| lettisch | LATVIAN_LATVIA.BLT8MSWIN1257 |
| litauisch | LITAUEN_LITAUEN.BLT8MSWIN1257 |
| norwegisch | NORWEGIAN_NORWEGEN.WE8MSWIN1252 |
| Polieren | POLISH_POLEN.EE8MSWIN1250 |
| Portugiesisch (Brasilien) | BRASILIANISCHES PORTUGIESISCH_BRASILIEN.WE8MSWIN1252 |
| Portugiesisch (Portugal) | PORTUGIESISCH_PORTUGAL.WE8MSWIN1252 |
| rumänisch | ROMANIAN_RUMÄNIEN.EE8MSWIN1250 |
| Russisch | RUSSIAN_CIS.CL8MSWIN1251 |
| slowakisch | SLOWAKEI_SLOWAKEI.EE8MSWIN1250 |
| Spanisch (Spanien) | SPANISH_SPAIN.WE8MSWIN1252 |
| Schwedisch | SWEDISH_SWEDEN.WE8MSWIN1252 |
| Thailändisch | THAI_THAILAND.TH8TISASCII |
| Spanisch (Mexiko) | MEXIKANISCHES SPANISCH_MEXIKO.WE8MSWIN1252 |
| Spanisch (Venezuela) | LATEINAMERIKANISCHES SPANISCH_VENEZUELA.WE8MSWIN1252 |
| Türkisch | TÜRKISCHE_TÜRKEI.TR8MSWIN1254 |
| ukrainisch | UKRAINIAN_UKRAINE.CL8MSWIN1251 |
| Vietnamesisch | VIETNAMESE_VIETNAM.VN8MSWIN1258 |
*Quelle: Häufig gestellte Fragen zu NLS_LANG (oracle.com) des Dokuments Detail
Hier kann eine Frage aufkommen.
Der Zeichensatz des Servers ist als AL32UTF8 bezeichnet, ein Unicode-System, aber warum sollte der Client NLS_LANG KO16MSWIN949 angeben, ein 2-Byte-System?
Dies liegt daran, dass das Windows-Betriebssystem die grundlegende Methode zum Kodieren/Dekodieren von Hangul ist. (Zur Referenz: Es ist üblich, KO16KSC5601 zu verwenden, wenn koreanische Zeichen unter UNIX ein- und ausgegeben werden.) Um es noch einmal zu erwähnen, der Server-Zeichensatz ist eine Einstellung zum „Speichern“ von Zeichenkettendaten und der Client NLS_LANG „zeigt“ Zeichenkettendaten an. , Es ist eine Einstellung für „Übertragung“.
Der Server-Zeichensatz spezifiziert AL32UTF8, ein Unicode-System, um Zeichen aus verschiedenen Ländern zu „speichern“, und das von Windows für jede Sprache unterstützte grundlegende Kodierungs-/Dekodierungssystem wird in der Client-Umgebung (hauptsächlich Windows) verschiedener Länder verwendet, die sich damit verbinden server.anzugeben In Nicht-Unicode eingegebene Daten werden in Unicode konvertiert und gespeichert, während sie über den Oracle-Client und SQL*Net an den Server übertragen werden.
Wenn der Zeichensatz des Servers AL32UTF8 ist und das Client-NLS_LANG auf AL32UTF8 eingestellt ist, wird der im Server gespeicherte Unicode-Wert ohne Konvertierungsvorgang an den Client übertragen. Mit anderen Worten, wenn der Client NLS_LANG auf AL32UTF8 gesetzt werden soll, muss der Client in der Lage sein, Unicode zu codieren/decodieren.
Als Referenz ist unter den kostenlos bereitgestellten Tools ORACLE SQL Developer ein repräsentatives Tool, das Unicode gut unterstützt. DBeaver unterstützt auch gut Unicode basierend auf jdbc.
Wenn Sie der Meinung sind, dass die Auswahl des Zeichensatzes schwierig ist, weil die bisherigen Inhalte kompliziert sind, müssen Sie sich nur die folgenden Inhalte merken.
- Server-Zeichensatz auf AL32UTF8 eingestellt
- Client NLS_LANG
- Wenn der Client Unicode nicht verarbeiten kann oder auf eine bestimmte Sprache beschränkt ist, legen Sie den der Sprache entsprechenden Wert fest
- AL32UTF8, wenn der Client Unicode verarbeiten kann
Bisher haben wir uns die Client-Umgebungskonfiguration in Bezug auf den Oracle-Zeichensatz angesehen.
Im nächsten Artikel sehen wir uns an, wie der Zeichensatz in einer ungültigen Umgebung konvertiert wird, in der der Server-Zeichensatz US7ASCII ist und Hangul gespeichert ist.
In Verbindung stehende Artikel:
 Oracle-Zeichensatzkonvertierung (9): 6. So konvertieren Sie vom Benutzer implementierte Zeichensätze (2)
Oracle-Zeichensatzkonvertierung (9): 6. So konvertieren Sie vom Benutzer implementierte Zeichensätze (2)
 Oracle-Zeichensatzkonvertierung(8): 6. So konvertieren Sie einen vom Benutzer implementierten Zeichensatz (1)
Oracle-Zeichensatzkonvertierung(8): 6. So konvertieren Sie einen vom Benutzer implementierten Zeichensatz (1)
 Konvertierung von Oracle-Zeichensätzen (7): 5.4. KO16MSWIN949 CSSCAN-Ausführungsergebnis der Umgebung
Konvertierung von Oracle-Zeichensätzen (7): 5.4. KO16MSWIN949 CSSCAN-Ausführungsergebnis der Umgebung
 Konvertierung von Oracle-Zeichensätzen (6): 5.3. CSSCAN-Ausführungsergebnis der US7ASCII-Umgebung
Konvertierung von Oracle-Zeichensätzen (6): 5.3. CSSCAN-Ausführungsergebnis der US7ASCII-Umgebung
 Oracle-Zeichensatzkonvertierung (5): 5. Von Oracle empfohlene Vorgehensweise
Oracle-Zeichensatzkonvertierung (5): 5. Von Oracle empfohlene Vorgehensweise
 Oracle-Zeichensatzkonvertierung (4): 4.Konfigurieren der Testumgebung
Oracle-Zeichensatzkonvertierung (4): 4.Konfigurieren der Testumgebung
 Oracle-Zeichensatzkonvertierung (2): 3. Konfigurieren der Client-Umgebung (1)
Oracle-Zeichensatzkonvertierung (2): 3. Konfigurieren der Client-Umgebung (1)
 Oracle-Zeichensatzkonvertierung(1): 1. Notwendigkeit, korrekter Oracle-Zeichensatz-Setup-Leitfaden
Oracle-Zeichensatzkonvertierung(1): 1. Notwendigkeit, korrekter Oracle-Zeichensatz-Setup-Leitfaden









