Oracle-Zeichensatzkonvertierung(1): 1. Notwendigkeit, korrekter Oracle-Zeichensatz-Setup-Leitfaden
Erfahren Sie mehr über die Notwendigkeit der Oracle-Zeichensatzkonvertierung und eine Anleitung zum Einrichten des richtigen Zeichensatzes.
Eines der Probleme im Zusammenhang mit der Datenmigration (Datenkonvertierung, Datenmigration, Datenmigration) in vielen Projekten der nächsten Generation ist die Zeichensatzkonvertierung von Oracle.
Meistens handelt es sich um eine Aufforderung zur Konvertierung von einem ungültigen Zeichensatz (z. B. US7ASCII) in einen gültigen Zeichensatz (z. B. KO16MSWIN949, AL32UTF8 usw.). Insbesondere der Fall, wo der Zeichensatz der aktuellen DB US7ASCII ist, ist am problematischsten.
Da die Daten, die normalerweise nicht gespeichert werden, als normale Daten angezeigt werden, ist viel Versuch und Irrtum für die Konvertierung erforderlich.
In den nächsten Artikeln möchte ich einige Methoden und Referenzpunkte zur Überprüfung vorstellen.
1. Konvertierungsanforderungen für Oracle-Zeichensätze
Wenn Sie den Oracle-Zeichensatz konvertieren möchten, liegen die folgenden Anforderungen vor.
- Falsch angegebener Zeichensatz (US7ASCII)
- Globalisierung des ursprünglich nur in Korea gebauten Systems (Konvertierung vom koreanischen Zeichensatz zum Unicode-Zeichensatz)
1.1. Falsch angegebener Zeichensatz (US7ASCII)
Einer der wenigen wichtigen Faktoren, die bei der Installation von Oracle festgelegt werden, ist der Zeichensatz. Nach der Installation von Oracle ist es wichtig, es zunächst gut einzurichten, da es nicht einfach ist, es zu ändern, sobald sich Daten angesammelt haben, während das System erstellt und verwendet wird.
Unter den Antwortdateien, die bei der Installation von Oracle im unbeaufsichtigten Modus erforderlich sind, ist der Standardwert für den Zeichensatz in der Datei dbca.rsp auf „US7ASCII“ gesetzt. Es ist auskommentiert, und bei der Installation muss diese Einstellung genau geändert und eingegeben werden. Im Falle einer Installation, bei der aufgrund eines Fehlers oder einer Nachlässigkeit nur das Auskommentieren entfernt wurde, wird der Zeichensatz als „US7ASCII“ bezeichnet.
Im Folgenden sind die Standardeinstellungen für den Zeichensatz in der Datei dbca.rsp dargestellt.
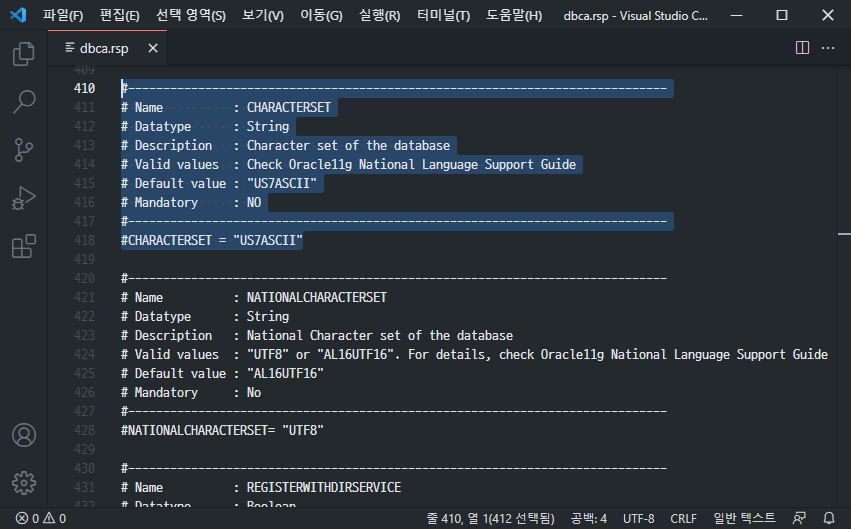
Die Situation, die hier für Verwirrung sorgt, ist, dass „US7ASCII“ auch die koreanische Ein- und Ausgabe unterstützt. Es verhält sich so, als würde es richtig gesprochen werden. Selbst wenn koreanische Daten eingegeben, aber normalerweise nicht gespeichert werden, ist es möglich, Koreanisch so auszugeben, als ob es normal wäre.
Da dies jedoch ein unvollständiger Zustand ist, ist unnötiger Aufwand erforderlich, wie z. B. das Eingeben von koreanischer Sprachkonvertierung und Verarbeitungslogik in den Anwendungsquellcode, und birgt somit die Möglichkeit, unbeabsichtigte Fehler zu verursachen.
Für „US7ASCII“ wird empfohlen, je nach Zweck des Systems in „KO16MSWIN949“ des Nicht-Unicode-Systems oder „UTF8“ oder „AL32UTF8“ des Unicode-Systems zu konvertieren.
1.2. Globalisierung des zunächst auf das Inland beschränkten Systems
Wenn die Globalisierung durch ein Projekt der nächsten Generation für ein System gefördert wird, das mit einem Zeichensatz von „KO16KSC5601“ oder „KO16MSWIN949“ verwendet wird, ist eine Konvertierung vom koreanischen Zeichensatz in den Unicode-Zeichensatz erforderlich.
Da „KO16KSC5601“ oder „KO16MSWIN949“ nicht alle mehrsprachigen Zeichen speichern kann, muss es in die Unicode-Reihe „UTF8“ oder „AL32UTF8“ konvertiert werden.
Da viele heimische Geschäftsumgebungen auf Globalisierung ausgerichtet sind und die Notwendigkeit, mehrsprachige Zeichen in Zukunft zu speichern, nicht vollständig ausgeschlossen werden kann, ist es wünschenswert, wenn immer möglich Unicode-basierte Zeichensätze zu verwenden.
Wenn die Anwendung nach der Installation nicht erstellt wird oder die gespeicherten Daten verworfen werden können, wird empfohlen, von Anfang an neu zu installieren. Die Neuinstallation erfordert viel weniger Aufwand als das Ändern eines Zeichensatzes, ist schneller und sicherer.
2. Anleitung zum Einrichten des richtigen Oracle-Zeichensatzes
Der Oracle-Zeichensatz ist in Nicht-Unicode-Serien und Unicode-Serien unterteilt und wie folgt gemäß der Einbeziehungsbeziehung organisiert.
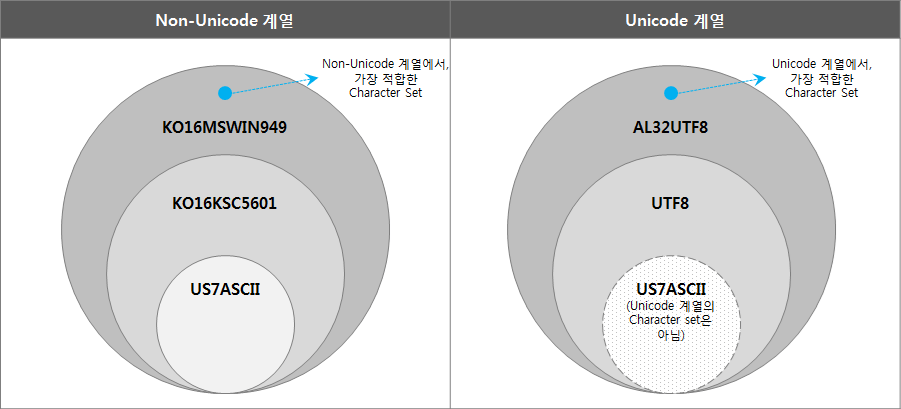
(„US7ASCII“ ist keine Unicode-Familie, ist aber enthalten und wird als Teilmenge von UTF8 ausgedrückt.)
Um den Oracle-Zeichensatz korrekt einzurichten, wählen Sie einfach eine der beiden folgenden Optionen:
| Systemtyp | Empfohlener Zeichensatz | Erläuterung |
| Nur in Korea verwendetes System | KO16MSWIN949 | – Alle Zeichen, die über den koreanischen IME in koreanisches Windows eingegeben werden können, werden unterstützt (koreanische, chinesische Zeichen, Englisch, Zahlen usw.) – Hangul und chinesische Schriftzeichen werden als 2 Byte gespeichert, und englische und Zahlen werden als 1 Byte gespeichert. |
| Systeme, die mehrsprachige Zeichen speichern müssen | AL32UTF8 | – AL32UTF8 kann alle Zeichen unterstützen, die im neuesten Unicode hinzugefügt wurden (chinesische Zeichen, westeuropäische Zeichen, südostasiatische Zeichen usw.) – Englische Buchstaben und Zahlen werden in 1 Byte gespeichert, und die meisten anderen Zeichen werden in 3 Bytes gespeichert. (Einige Zeichen werden als 4 Bytes gespeichert, aber selten verwendet.) |
Im Vergleich zu „KO16MSWIN949“ benötigt „AL32UTF8“ maximal den 1,5-fachen Speicherplatz für Zeichentypen (wenn nur koreanische Zeichen enthalten sind), aber es gibt Daten (Code, ID, Nummer, Sequenznummer usw.), die nur verwendet werden Englisch/Zahlen und koreanische und englische Zeichen. /Da es viele Fälle gibt, in denen die Zahlen gemischt sind, ist es nicht genau, aber im Allgemeinen kann man sehen, dass der Speicherplatz um das 1,3-fache zunimmt.
Einzelheiten zu jedem Zeichensatz finden Sie im Folgenden.
*Quelle: Untersuchung der perfekten Kompatibilität zwischen Oracle und NLS (Ryu Jung-woo │ Oracle Korea WPTG Team) (OTNs ursprünglicher Original-Link wurde entfernt)
| KO16KSC5601 | KO16MSWIN949 | UTF8 | AL32UTF8 | |
| Status der koreanischen Sprachunterstützung | Koreanisch 2350 Zeichen | KO16KSC5601 + Erweiterung 8822 Zeichen (insgesamt 11172 Zeichen) | Hangeul 11172 Zeichen | Hangeul 11172 Zeichen |
| Zeichensatz/Kodierungsversion | Hangul-Vervollständigungstyp | Inklusive vollständigem Code Erweiterte 8822 Zeichen, ausgerichtet nach MS Windows Codepage 949 | Vor 8.1.6: Unicode 2.1 Ab 8.1.7: Unicode 3.0 | 9i Rel1: Unicode 3.0 9i Rel2: Unicode 3.1 10g Rel1: Unicode 3.2 10g Rel2: Unicode 4.0 |
| Koreanische Bytes | 2 Byte | 2 Byte | 3 Byte | 3 Byte |
| Support-Version | 7.x | 8.0.6 oder höher | 8.0 aufwärts | 9i Version 1 und höher |
| Datenbank-ZeichensatzKann eingestellt werden | möglich | möglich | möglich | möglich |
| Nationaler ZeichensatzKann eingestellt werden | unmöglich | unmöglich | möglich | unmöglich |
| Hangul-Sortierung (NLS_SORT Satz) | Kann als einfache binäre Sortierung implementiert werden | Erfordert spezielle Optionen wie KOREAN_M oder UNICODE_BINARY (Siehe Beschreibung der koreanischen Ausrichtung) | Hangul-Sortierung ist mit einfacher binärer Sortierung möglich. Das Sortieren chinesischer Zeichen erfordert die Option KOREAN_M | – Hangul-Unterstützung ist die gleiche wie UTF8 |
| Vorteile | – Keine besonderen Vorteile. Hohe Performance, wenn sichergestellt ist, dass nur vollständiger Code ein- und ausgegeben wird | – Alle koreanischen Zeichen können mit 2 Bytes gespeichert/eingegeben/ausgegeben werden. Alle koreanischen Zeichen können bei geringem Platzverbrauch ein- und ausgegeben werden. | – 11.172 moderne koreanische Zeichen sind in der richtigen Reihenfolge angeordnet, sodass die Ausrichtung effektiv ist – Sollen auch andere Sprachen (Chinesisch, Thai etc.) in der gleichen Datenbankinstanz hinterlegt werden, gibt es keine Alternative zu Unicode-Zeichensätzen wie UTF8. | |
| Nachteile | – Fataler Nachteil ist, dass nur 2350 koreanische Zeichen unterstützt werden, daher sollte die Verwendung von Zeichensätzen zukünftig vermieden werden. | – Um mit dem fertigen Typ kompatibel zu sein, sind Buchstabenanordnung und Sortierreihenfolge anders. Eine einfache „ORDER BY“-Klausel kann Hangul nicht richtig sortieren. | Ein koreanisches Zeichen verbraucht 3 Bytes, daher ist der Speicherplatzverbrauch relativ hoch (1,5 Mal im Vergleich zu 2 Bytes), und die Leistung muss für die Unicode-Codierung/Decodierung verbraucht werden. |
* „UTF8“ unterstützt nur bis zu Unicode 3.0 und „AL32UTF8“ unterstützt die neueste Version von Unicode und die Version, die in Zukunft veröffentlicht wird.
Die Oracle-Dokumentation empfiehlt auch „AL32UTF8“.
Quelle: http://docs.oracle.com/cd/E11882_01/server.112/e10729/ch2charset.htm#NLSPG002
Einige Auszüge sind unten eingefügt.
Datenbank-Zeichensatz-Anweisung
In Tabelle A-4, „Empfohlene Zeichensätze für ASCII-Datenbanken“ und Tabelle A-5, „Empfohlene Zeichensätze für EBCDIC-Datenbanken“, wurde eine Liste von Zeichensätzen zusammengestellt, die Oracle dringend zur Verwendung als Datenbankzeichensatz empfiehlt. Andere von Oracle unterstützte Zeichensätze, die nicht in dieser Liste aufgeführt sind, können weiterhin in Oracle Database 11g Release 2 verwendet werden, werden aber möglicherweise in einer zukünftigen Version nicht mehr unterstützt. Ab Oracle Database 11g Release 1 ist die Auswahl für den Datenbankzeichensatz auf diese Liste empfohlener Zeichensätze in allgemeinen Installationspfaden von Oracle Universal Installer und Oracle Database Configuration Assistant beschränkt. Kunden können weiterhin neue Datenbanken mit benutzerdefinierten Installationspfaden erstellen und ihre vorhandenen Datenbanken migrieren, selbst wenn der Zeichensatz nicht auf der empfohlenen Liste steht. Oracle schlägt jedoch vor, dass Kunden so bald wie möglich zu einem empfohlenen Zeichensatz migrieren. Ganz oben auf der Liste der Zeichensätze, die Oracle für alle neuen Systemimplementierungen empfiehlt, steht der Unicode-Zeichensatz AL32UTF8.Auswahl von Unicode als Datenbankzeichensatz
Oracle empfiehlt die Verwendung von Unicode für alle neuen Systembereitstellungen. Auch die Migration von Legacy-Systemen auf Unicode wird empfohlen. Die Bereitstellung Ihrer Systeme heute in Unicode bietet viele Vorteile in Bezug auf Benutzerfreundlichkeit, Kompatibilität und Erweiterbarkeit. Mit Oracle Database können Sie leistungsstarke Systeme schneller und einfacher bereitstellen und gleichzeitig die Vorteile von Unicode nutzen. Auch wenn Sie heute weder mehrsprachige Daten unterstützen müssen noch Unicode benötigen, ist es auf lange Sicht wahrscheinlich die beste Wahl für ein neues System und wird Ihnen letztendlich Zeit und Geld sparen und Sie wettbewerbsfähig machen Vorteile auf lange Sicht. Weitere Informationen zu Unicode finden Sie in Kapitel 6, „Unterstützung mehrsprachiger Datenbanken mit Unicode“.
Bitte beachten Sie den unterstrichenen Teil oben.
Bisher haben wir uns mit der Notwendigkeit der Oracle-Zeichensatzkonvertierung und einer Anleitung zum Einrichten des richtigen Oracle-Zeichensatzes befasst. Als Nächstes werfen wir einen Blick auf die Client-Umgebungskonfiguration in Bezug auf den Oracle-Zeichensatz.
In Verbindung stehende Artikel:
 Beschreibung der Oracle-Zeichensatzkonvertierung Vollständiges Inhaltsverzeichnis
Beschreibung der Oracle-Zeichensatzkonvertierung Vollständiges Inhaltsverzeichnis
 Konvertierung von Oracle-Zeichensätzen (10): 6.3. So konvertieren Sie den CLOB-Typ in Koreanisch
Konvertierung von Oracle-Zeichensätzen (10): 6.3. So konvertieren Sie den CLOB-Typ in Koreanisch
 Oracle-Zeichensatzkonvertierung (9): 6. So konvertieren Sie vom Benutzer implementierte Zeichensätze (2)
Oracle-Zeichensatzkonvertierung (9): 6. So konvertieren Sie vom Benutzer implementierte Zeichensätze (2)
 Oracle-Zeichensatzkonvertierung(8): 6. So konvertieren Sie einen vom Benutzer implementierten Zeichensatz (1)
Oracle-Zeichensatzkonvertierung(8): 6. So konvertieren Sie einen vom Benutzer implementierten Zeichensatz (1)
 Konvertierung von Oracle-Zeichensätzen (7): 5.4. KO16MSWIN949 CSSCAN-Ausführungsergebnis der Umgebung
Konvertierung von Oracle-Zeichensätzen (7): 5.4. KO16MSWIN949 CSSCAN-Ausführungsergebnis der Umgebung
 Oracle-Zeichensatzkonvertierung (4): 4.Konfigurieren der Testumgebung
Oracle-Zeichensatzkonvertierung (4): 4.Konfigurieren der Testumgebung
 Oracle-Zeichensatzkonvertierung (3): 3. Konfiguration der Client-Umgebung (2)
Oracle-Zeichensatzkonvertierung (3): 3. Konfiguration der Client-Umgebung (2)
 Oracle-Zeichensatzkonvertierung (2): 3. Konfigurieren der Client-Umgebung (1)
Oracle-Zeichensatzkonvertierung (2): 3. Konfigurieren der Client-Umgebung (1)









