分词工具(三):如何运行分词工具并查看结果
让我们来看看如何运行单词提取工具并检查结果。
这是上一篇文章的延续。
3.运行分词工具
3.1.下载分词工具
分词工具已经上传到github。
https://github.com/DAToolset/ToolsForDataStandard/tree/main/WordExtractor
执行所需的源代码、字体、表/列列表示例文件和输出示例文件被捆绑到一个压缩文件中进行分发,因此您可以下载该文件。
https://github.com/DAToolset/ToolsForDataStandard/raw/main/WordExtractor/word_extractor.7z
此分发存档包含以下文件:
[font] - NanumBarunGothic.ttf - NanumSquareR.ttf [out] - extract_result_20210829111836.xlsx - wordcloud_20210829111836.png - table,column comments.xlsx - word_extractor.py
每个文件夹和文件的描述如下。
- [字体]
- 包含创建 WordCloud 时所需字体的文件夹
- 如有必要,可以通过更改源代码来添加和使用其他字体。
- 源码中改函数:make_word_cloud
- [出去]
- 包含单词提取结果示例文件的文件夹
- 该文件的内容可以在下面的文章中找到。
1.3.3.词提取工具输出数据
- 表、列注释.xlsx
- DB表、列注释输入示例文件
- 该文件的内容可以在下面的文章中找到。
1.3.1._word_extraction_tool_input_data
- word_extractor.py:词提取器源代码(Python)
- 注意:此源代码文件可能会更改,因此请检查 github 文件以获取最新版本,而不是分发存档。
3.2.如何运行词提取工具
3.2.1.解压下载的文件并激活Python虚拟环境
将上面下载的分发压缩文件解压到合适的路径。 (例如“d:\Project\WordExtractor”)
执行Miniconda Prompt,移动到解压路径,激活Python虚拟环境。
要激活 Python 虚拟环境,请参考以下文章。
在以下 Miniconda 提示状态下继续。
(wordextr) d:\Project\WordExtractor>
3.2.2.检查帮助
您可以通过指定“–help”参数并执行它来查看帮助。
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
执行时的输出如下。
(wordextr) d:\Project\WordExtractor>python word_extractor.py --help
usage: word_extractor.py [-h] [--multi_process_count MULTI_PROCESS_COUNT] [--db_comment_file DB_COMMENT_FILE] [--in_path IN_PATH] --out_path OUT_PATH
--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment
optional arguments:
-h, --help show this help message and exit
--multi_process_count MULTI_PROCESS_COUNT
text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)
--db_comment_file DB_COMMENT_FILE
DB Table, Column comment 정보 파일명(예: comment.xlsx)
--in_path IN_PATH 입력파일(ppt, doc, txt) 경로명(예: .\in)
--out_path OUT_PATH 출력파일(xlsx, png) 경로명(예: .\out)
有三种方法可以做到这一点。 (参考上面帮助中的“*执行示例”)
- 仅从文档文件中提取单词
- 指定保存MS Word、PowerPoint、Text文件的文件夹为“–in_path”,指定输出结果的文件夹为“–out_path”
- 仅从数据库表中提取单词,列注释
- 将以注释文件格式保存的Excel文件指定为“–db_comment_file”,指定输出结果的文件夹为“–out_path”
- 从文档文件、数据库表和列注释中提取单词(如何同时提取 1 和 2)
- 指定所有“–in_path”、“–db_comment_file”、“–out_path”
“–multi_process_count”参数是从文件中提取文本和从文本中提取单词时要并行运行的进程数。根据执行环境指定适当的数量可以提高性能。
在本文中,没有指定和执行“-multi_process_count”参数。在这种情况下,它被设置为代码执行过程中执行环境中逻辑cpu的数量。 (例如 i5-8250U CPU 为 8)
3.2.3.方法一:仅从文档文件中提取单词
首先在Python源码所在路径下创建一个文件夹用来存放文档文件。
例如,在“d:\Project\WordExtractor”下创建“in”文件夹,创建“d:\Project\WordExtractor\in”路径。
然后,将 MS Word、PowerPoint 和文本格式的文件复制到“in”文件夹中。即使“in”文件夹下有多级文件夹,也都可以进行探索和处理,所以建议按事业单位等组织子文件夹。
作为参考,在撰写本文时 (2021-10-24),尚不支持 HWP 和 PDF 文件。
使用以下命令运行它: (指定 –in_path、–out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out
执行结果的例子如下。
(wordextr) d:\Project\WordExtractor>python word_extractor.py --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:15:11.985581 ##### arguments ##### multi_process_count: 8 db_comment_file: None in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:15:11.985581] Start Get File List... [2021-10-24 12:15:11.985581] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:15:11.985581] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx text count: 25 line count: 34 [pid:17976] get_txt_text elapsed time: 0:00:00.135933 text count: 124 page count: 5 [pid:5412] get_ppt_text elapsed time: 0:00:03.370637 text count: 59 page count: 3 [pid:22052] get_doc_text elapsed time: 0:00:04.100849 [2021-10-24 12:15:18.094089] Finish Get File Text. [2021-10-24 12:15:18.094089] Start Get Word from File Text... [pid:25016] input text count:26, extracted word count: 31 [pid:25016] get_word_list finished. total: 26, elapsed time: 0:00:00.109351 [pid:17704] input text count:26, extracted word count: 54 [pid:17704] get_word_list finished. total: 26, elapsed time: 0:00:00.156214 [pid:18468] input text count:26, extracted word count: 52 [pid:18468] get_word_list finished. total: 26, elapsed time: 0:00:00.140596 [pid:3456] input text count:26, extracted word count: 38 [pid:3456] get_word_list finished. total: 26, elapsed time: 0:00:00.109350 [pid:15400] input text count:26, extracted word count: 50 [pid:15400] get_word_list finished. total: 26, elapsed time: 0:00:00.140594 [pid:25892] input text count:26, extracted word count: 65 [pid:25892] get_word_list finished. total: 26, elapsed time: 0:00:00.171835 [pid:3592] input text count:26, extracted word count: 147 [pid:3592] get_word_list finished. total: 26, elapsed time: 0:00:00.312458 [pid:9512] input text count:26, extracted word count: 180 [pid:9512] get_word_list finished. total: 26, elapsed time: 0:00:00.374976 [2021-10-24 12:15:20.320614] Finish Get Word from File Text. [2021-10-24 12:15:20.320614] Start Get Word Frequency... [2021-10-24 12:15:20.336234] Finish Get Word Frequency. [2021-10-24 12:15:20.336234] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:06.681665 [2021-10-24 12:15:27.017899] Finish Make Word Cloud. [2021-10-24 12:15:27.017899] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:15:27.643679] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:15:27.643679] Finished. overall elapsed time: 0:00:15.658098 ------------------------------------------------------------
3.2.4.方法二:只从DB Table, Column comments中抽取词
首先,用Excel打开压缩文件中包含的“表格、列注释.xlsx”文件,按照格式填写内容,保存。
有关格式和内容的示例,请参见下文。
使用以下命令运行它: (指定 –db_comment_file、–out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
文件名用双引号(“)括起来,因为输入的文件名包含空白字符。
如果“table,column comments.xlsx”文件与Python源代码文件的路径不同,指定它包括路径。这里假设它们在同一条路径上。
执行结果的例子如下。
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:34:23.369210 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: None out_path: .\out ------------------------------------------------------------ [2021-10-24 12:34:23.370209] Start Get File Text... get_db_comment_text: table,column comments.xlsx table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:17088] get_db_comment_text elapsed time: 0:00:01.216618 text count: 1680 [2021-10-24 12:34:26.577237] Finish Get File Text. [2021-10-24 12:34:26.577237] Start Get Word from File Text... [pid:25240] current: 100, total: 210, progress: 47.62% [pid:21792] current: 100, total: 210, progress: 47.62% [pid:14788] current: 100, total: 210, progress: 47.62% [pid:10660] current: 100, total: 210, progress: 47.62% [pid:17208] current: 100, total: 210, progress: 47.62% [pid:13300] current: 100, total: 210, progress: 47.62% [pid:23764] current: 100, total: 210, progress: 47.62% [pid:25068] current: 100, total: 210, progress: 47.62% [pid:13300] current: 200, total: 210, progress: 95.24% [pid:14788] current: 200, total: 210, progress: 95.24% [pid:13300] input text count:210, extracted word count: 804 [pid:13300] get_word_list finished. total: 210, elapsed time: 0:00:02.900049 [pid:10660] current: 200, total: 210, progress: 95.24% [pid:14788] input text count:210, extracted word count: 850 [pid:14788] get_word_list finished. total: 210, elapsed time: 0:00:03.005057 [pid:10660] input text count:210, extracted word count: 819 [pid:10660] get_word_list finished. total: 210, elapsed time: 0:00:03.040949 [pid:17208] current: 200, total: 210, progress: 95.24% [pid:25240] current: 200, total: 210, progress: 95.24% [pid:17208] input text count:210, extracted word count: 929 [pid:17208] get_word_list finished. total: 210, elapsed time: 0:00:03.182333 [pid:25240] input text count:210, extracted word count: 871 [pid:25240] get_word_list finished. total: 210, elapsed time: 0:00:03.320128 [pid:23764] current: 200, total: 210, progress: 95.24% [pid:21792] current: 200, total: 210, progress: 95.24% [pid:23764] input text count:210, extracted word count: 1054 [pid:23764] get_word_list finished. total: 210, elapsed time: 0:00:03.362429 [pid:25068] current: 200, total: 210, progress: 95.24% [pid:21792] input text count:210, extracted word count: 1077 [pid:21792] get_word_list finished. total: 210, elapsed time: 0:00:03.651294 [pid:25068] input text count:210, extracted word count: 1163 [pid:25068] get_word_list finished. total: 210, elapsed time: 0:00:03.616955 [2021-10-24 12:34:32.287245] Finish Get Word from File Text. [2021-10-24 12:34:32.287245] Start Get Word Frequency... [2021-10-24 12:34:32.313363] Finish Get Word Frequency. [2021-10-24 12:34:32.313363] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.572230 [2021-10-24 12:34:42.886547] Finish Make Word Cloud. [2021-10-24 12:34:42.886547] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:34:48.636633] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:34:48.636633] Finished. overall elapsed time: 0:00:25.266424 ------------------------------------------------------------
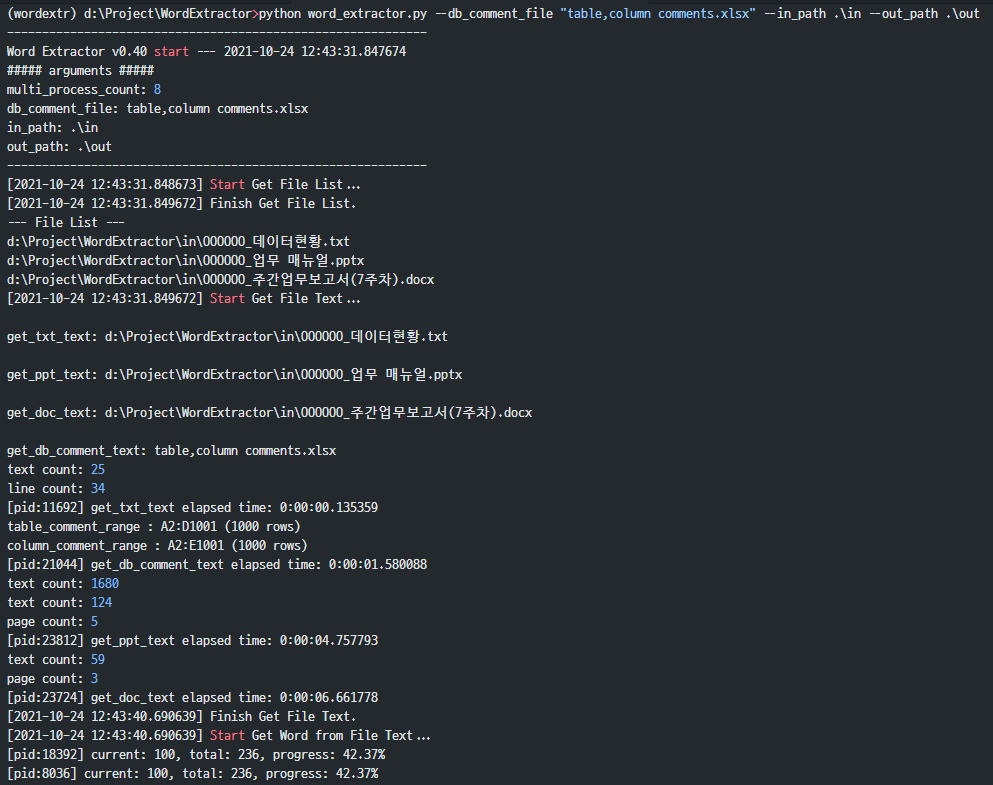
3.2.5.方法 3:从文档文件、数据库表和列注释中提取单词
这是一个可以同时执行方法1和方法2的方法。
使用以下命令运行它: (指定 –db_comment_file、–in_path、–out_path)
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out
执行结果的例子如下。
(wordextr) d:\Project\WordExtractor>python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\in --out_path .\out ------------------------------------------------------------ Word Extractor v0.40 start --- 2021-10-24 12:43:31.847674 ##### arguments ##### multi_process_count: 8 db_comment_file: table,column comments.xlsx in_path: .\in out_path: .\out ------------------------------------------------------------ [2021-10-24 12:43:31.848673] Start Get File List... [2021-10-24 12:43:31.849672] Finish Get File List. --- File List --- d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx [2021-10-24 12:43:31.849672] Start Get File Text... get_txt_text: d:\Project\WordExtractor\in\OOOOOO_데이터현황.txt get_ppt_text: d:\Project\WordExtractor\in\OOOOOO_업무 매뉴얼.pptx get_doc_text: d:\Project\WordExtractor\in\OOOOOO_주간업무보고서(7주차).docx get_db_comment_text: table,column comments.xlsx text count: 25 line count: 34 [pid:11692] get_txt_text elapsed time: 0:00:00.135359 table_comment_range : A2:D1001 (1000 rows) column_comment_range : A2:E1001 (1000 rows) [pid:21044] get_db_comment_text elapsed time: 0:00:01.580088 text count: 1680 text count: 124 page count: 5 [pid:23812] get_ppt_text elapsed time: 0:00:04.757793 text count: 59 page count: 3 [pid:23724] get_doc_text elapsed time: 0:00:06.661778 [2021-10-24 12:43:40.690639] Finish Get File Text. [2021-10-24 12:43:40.690639] Start Get Word from File Text... [pid:18392] current: 100, total: 236, progress: 42.37% [pid:8036] current: 100, total: 236, progress: 42.37% [pid:26864] current: 100, total: 236, progress: 42.37% [pid:23288] current: 100, total: 236, progress: 42.37% [pid:15596] current: 100, total: 236, progress: 42.37% [pid:8036] current: 200, total: 236, progress: 84.75% [pid:18208] current: 100, total: 236, progress: 42.37% [pid:17976] current: 100, total: 236, progress: 42.37% [pid:4324] current: 100, total: 236, progress: 42.37% [pid:18392] current: 200, total: 236, progress: 84.75% [pid:26864] current: 200, total: 236, progress: 84.75% [pid:8036] input text count:236, extracted word count: 739 [pid:8036] get_word_list finished. total: 236, elapsed time: 0:00:02.651907 [pid:18392] input text count:236, extracted word count: 780 [pid:18392] get_word_list finished. total: 236, elapsed time: 0:00:02.879298 [pid:15596] current: 200, total: 236, progress: 84.75% [pid:26864] input text count:236, extracted word count: 887 [pid:26864] get_word_list finished. total: 236, elapsed time: 0:00:03.161543 [pid:15596] input text count:236, extracted word count: 979 [pid:15596] get_word_list finished. total: 236, elapsed time: 0:00:03.443786 [pid:18208] current: 200, total: 236, progress: 84.75% [pid:23288] current: 200, total: 236, progress: 84.75% [pid:17976] current: 200, total: 236, progress: 84.75% [pid:18208] input text count:236, extracted word count: 1181 [pid:18208] get_word_list finished. total: 236, elapsed time: 0:00:03.831052 [pid:4324] current: 200, total: 236, progress: 84.75% [pid:23288] input text count:236, extracted word count: 1242 [pid:23288] get_word_list finished. total: 236, elapsed time: 0:00:04.139228 [pid:17976] input text count:236, extracted word count: 1294 [pid:17976] get_word_list finished. total: 236, elapsed time: 0:00:04.113296 [pid:4324] input text count:236, extracted word count: 1082 [pid:4324] get_word_list finished. total: 236, elapsed time: 0:00:04.334706 [2021-10-24 12:43:47.324098] Finish Get Word from File Text. [2021-10-24 12:43:47.325098] Start Get Word Frequency... [2021-10-24 12:43:47.353058] Finish Get Word Frequency. [2021-10-24 12:43:47.353058] Start Make Word Cloud... start make_word_cloud... make_word_cloud elapsed time: 0:00:10.604237 [2021-10-24 12:43:57.958289] Finish Make Word Cloud. [2021-10-24 12:43:57.958289] Start Save the Extract result to Excel File... start writing excel file... [2021-10-24 12:44:04.752046] Finish Save the Extract result to Excel File... ------------------------------------------------------------ [2021-10-24 12:44:04.752046] Finished. overall elapsed time: 0:00:32.903374 ------------------------------------------------------------
上面的执行过程的一部分被捕获并粘贴为图像。
3.2.6.如何查看执行结果
执行时,将在指定为输出路径的文件夹 (\out) 中创建两个文件(xlsx、png)。年、月、时、分、秒 (YYYYMMDDHHMISS) 自动分配给文件名,因此您可以检查它的创建时间。
例如,分发压缩文件的out文件夹中包含的执行结果文件如下。
- extract_result_20210829111836.xlsx:取词结果excel文件
- wordcloud_20210829111836.png:用词提取结果excel文件的“词频”表制作的词云图文件
执行结果文件的格式和内容可以参考下面的文章。
3.2.7.执行注意事项/注意事项
- 如果您在执行前先运行 MS-Word 或 PowerPoint 应用程序,执行性能会略有提高。
- 在执行过程中,文件在 MS-Word 或 PowerPoint 应用程序中打开,并在处理后关闭。当单词提取器运行时,不要使用每个应用程序并保持原样。
- 文件越多,文件页数越多,评论Excel文件中的数据行越多,执行时间越长。
- 建议在执行之前先将输入文件的一部分和评论excel文件的一部分数据分别保存下来,测试是否正常。
- 考虑到整个运行起来需要很长时间,最好在吃饭或休息时进行。
本文介绍了如何使用单词提取工具。如果您对使用有任何疑问,或者您有任何好的功能要添加,请发表评论。
下一篇文章将看看源代码。
<< 相关文章列表 >>


















你好!谢谢你的代码
使用 pptx 文件作为输入运行代码时,我有一个问题。
我测试了从 .pptx 文件中提取单词。
有一个空的ppt窗口在执行代码的时候没有关闭,飘起来的现象。
word、txt、excel没有类似现象。
想问一下这是否是临时现象,具体取决于Office版本。
环境是
我使用的是 windows 11,office 365 版本。
谢谢
您好,感谢您的光临和评论。
我想多了解一下Kiyoung Kim的情况。
以下哪项是这种情况?
1) PowerPoint 应用程序在“代码执行期间”没有响应并且没有进行到下一个文件的现象
2) 代码执行“后”PowerPoint 应用程序保持打开状态而没有关闭的现象
如果 1) 是这种情况,
– 如果在任务管理器中强行关闭 PowerPoint,是否可以继续处理下一个文件?
– 当前文件可能未正确处理。
– 建议从头重新运行任务。
如果 2) 是这种情况,
– 提前运行PowerPoint后再运行取词工具,PowerPoint应用程序一直处于打开状态是正常的。
– 如果您没有运行 PowerPoint,这是一种奇怪的行为,但如果所有文件都已处理,则您无需担心。
供参考,如果在没有运行PowerPoint、Excel等应用程序的情况下运行取词工具,在OLE自动化过程中执行PowerPoint、Excel等应用程序,处理完成后终止是正常的。
否则,请留下其他评论。
您好,感谢您的快速回复!
在我的例子中,2) 在代码执行“之后”,powerpoint 应用程序保持打开状态而不关闭。
正如你所说,这似乎是一种异常行为,因为 PowerPoint 没有提前运行。
所有文件处理无异常。
谢谢你!
感谢您告知我们情况和结果。
请好好利用~^^
你好。我目前正在使用该工具,但它不起作用。是不是miniforge的问题呢? 首先,我将miniconda安装在不同的环境中,然后再次运行。
——————————————————————————————
(wordextr) C:\Users\User\Downloads\word_extractor>python word_extractor.py –in_path .\in –out_path .\out
C:\Users\User\Downloads\word_extractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
C:\Users\User\Downloads\word_extractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
C:\Users\User\Downloads\word_extractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
————————————————————
单词提取器 v0.41 开始 — 2024-01-18 17:36:57.283006
##### 参数 #####
多进程计数:16
db_comment_file:无
in_path: .\in
输出路径:.\输出
————————————————————
[2024-01-18 17:36:57.288351] 开始获取文件列表...
[2024-01-18 17:36:57.289390] 完成获取文件列表。
— 文件列表 —
[2024-01-18 17:36:57.290381] 开始获取文件文本...
回溯(最近一次调用最后一次):
文件“C:\Users\User\Downloads\word_extractor\word_extractor.py”,第 559 行,位于
主要的()
文件“C:\Users\User\Downloads\word_extractor\word_extractor.py”,第 461 行,在 main 中
df_text = pd.concat(mp_text_result,ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”,第 380 行,连续
op = _连接器(
^^^^^^^^^^^^^^
文件“C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”,第 443 行,在 __init__ 中
objs, 键 = self._clean_keys_and_objs(objs, 键)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“C:\ProgramData\miniforge3\envs\wordextr\Lib\site-packages\pandas\core\reshape\concat.py”,第 505 行,在 _clean_keys_and_objs 中
引发 ValueError(“没有要连接的对象”)
ValueError:没有要连接的对象
版本信息如下
Python 3.12.1
套餐版本
————— ————
轮廓1.2.0
循环仪0.12.1
恩田0.4.0
字体工具 4.47.2
金贾2 3.1.3
奇异解算器 1.4.5
标记安全 2.1.3
matplotlib 3.8.2
numpy 1.26.3
包装 23.2
熊猫2.1.4
枕头10.2.0
点 23.3.2
pyparsing 3.1.1
python-dateutil 2.8.2
pytz 2023.3.post1
pywin32 306
安装工具69.0.3
六 1.16.0
时区数据2023.4
轮子0.42.0
词云1.9.3
XlsxWriter 3.1.9
如果输入目录中没有具有以下扩展名的文件,则会出现此错误。
– .ppt、.pptx
– .doc、.docx
- 。TXT
我测试如下:
—————————————————————————–
(.venv) D:\Temp\python_venv\wordextr_test>python –版本
Python 3.11.1
(.venv) D:\Temp\python_venv\wordextr_test>python word_extractor.py –in_path .\in –out_path .\out
————————————————————
单词提取器 v0.41 开始 — 2024-01-19 08:55:44.842578
##### 参数 #####
多进程计数:8
db_comment_file:无
in_path: .\in
输出路径:.\输出
————————————————————
[2024-01-19 08:55:44.845602] 开始获取文件列表...
[2024-01-19 08:55:44.845602] 完成获取文件列表。
— 文件列表 —
[2024-01-19 08:55:44.845602] 开始获取文件文本...
回溯(最近一次调用最后一次):
文件“D:\Temp\python_venv\wordextr_test\word_extractor.py”,第 164 行,位于
主要的()
文件“D:\Temp\python_venv\wordextr_test\word_extractor.py”,第 152 行,在 main 中
df_text = pd.concat(mp_text_result,ignore_index=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”,第 380 行,连续
op = _连接器(
^^^^^^^^^^^^^^
文件“D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”,第 443 行,位于 __init__ 中
objs, 键 = self._clean_keys_and_objs(objs, 键)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“D:\Temp\python_venv\wordextr_test\.venv\Lib\site-packages\pandas\core\reshape\concat.py”,第 505 行,在 _clean_keys_and_objs 中
引发 ValueError(“没有要连接的对象”)
ValueError:没有要连接的对象
(.venv) D:\Temp\python_venv\wordextr_test>dir .\in
驱动器 D 上的卷:数据
卷序列号:D6EC-7CFE
D:\Temp\python_venv\wordextr_test\ 目录中
2024-01-18 09:41 下午
2024-01-18 09:41 下午
0 个文件 0 字节
2 个目录剩余 34,305,060,864 字节
你好。我目前正在使用该工具,但我不断收到错误。我查了一下,好像是Pandas版本的问题。 (似乎从 Pandas 2 开始不提供 .appen 函数。)还是另一个错误?
(wordextr) C:\Users\hyelm\Documents\word_extractor>python word_extractor.py。 –db_comment_file “table_column_comments1.xlsx” –out_path 'C:\Users\hyelm\Documents\word_extractor\out'
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
————————————————————
单词提取器 v0.41 开始 — 2024-04-29 14:28:41.474667
##### 参数 #####
多进程计数:4
db_comment_file:表_column_comments1.xlsx
in_path:无
out_path: 'C:\Users\hyelm\Documents\word_extractor\out'
————————————————————
[2024-04-29 14:28:41.479798] 开始获取文件文本...
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
C:\Users\hyelm\Documents\word_extractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
get_db_comment_text:table_column_comments1.xlsx
表注释范围:A2:D7112(7111行)
列注释范围:A2:E181935(181934 行)
multiprocessing.pool.RemoteTraceback:
“””
回溯(最近一次调用最后一次):
文件“C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 125 行,在worker中
结果 = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
文件“C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 48 行,在 mapstar 中
返回列表(地图(*args))
^^^^^^^^^^^^^^^^
文件“C:\Users\hyelm\Documents\word_extractor\word_extractor.py”,第 369 行,在 get_file_text 中
df_text = get_db_comment_text(文件名)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“C:\Users\hyelm\Documents\word_extractor\word_extractor.py”,第 343 行,在 get_db_comment_text 中
df_text = df_column.append(df_table,ignore_index=True)
^^^^^^^^^^^^^^^^
文件“C:\Users\hyelm\miniconda3\envs\wordextr\Lib\site-packages\pandas\core\generic.py”,第 6296 行,在 __getattr__ 中
返回对象.__getattribute__(self, name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError:“DataFrame”对象没有属性“append”。您的意思是:“_append”吗?
“””
上述异常是导致以下异常的直接原因:
回溯(最近一次调用最后一次):
文件“C:\Users\hyelm\Documents\word_extractor\word_extractor.py”,第 559 行,位于
主要的()
文件“C:\Users\hyelm\Documents\word_extractor\word_extractor.py”,第 460 行,在 main 中
mp_text_result = pool.map(get_file_text, file_list)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 367 行,在地图中
返回 self._map_async(func, iterable, mapstar, chunksize).get()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“C:\Users\hyelm\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 774 行,在 get 中
提高自我价值
AttributeError:“DataFrame”对象没有属性“append”
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError:“DataFrame”对象没有属性“append”。您的意思是:“_append”吗?
“””
上面评论里的代码复制得太奇怪了,所以我又把它留下了。
这个错误是由于 Pandas 版本问题造成的吗?
从Pandas v2.0开始,不再支持append,所以改成concat是正确的。
我参考了下面两个文件。
https://yunwoong.tistory.com/253
https://stackoverflow.com/questions/75956209/error-dataframe-object-has-no-attribute-append
这几天很难抽出时间,不知道什么时候才能改源码。
安装 Pandas 时,您想指定并安装以前的版本吗?
希望一切顺利~