分词工具(一):分词工具概述
对数据标准化工作很有用的单词提取工具的概述,尤其是对于创建标准候选单词。
一、分词工具概述
1.1.为什么我们开发词提取工具
在数据标准化的初始任务中,最困难的任务是收集尽可能多的候选词并迅速注册为标准词。数据标准检查工具(参见: 数据标准检查工具_1.概述) 可用于提取标准候选词,但存在以下困难。
- 如果数据库表、列注释数据中含有较多的特殊字符(#、$、%、.、\等符号、行分隔符等),去除或细化需要相当大的努力。
- 很难知道词的出现频率,因此很难确定是只注册单词,只注册复合词,还是同时注册单词和复合词。
- 如果在确定标准词后又识别出复合词,影响到已经登记的标准词的物理名称,则标准命名规则的例外情况会给管理带来困难。
单词提取工具的开发就是为了缓解其中的一些困难。特别是,我们希望它对以下情况有所帮助。
- 如果没有当前的数据标准词典或者即使标准词的数量很少
- 你的工作很独特,没有适合参考的数据标准字典。
- 当数据库表和列注释过大,手动抽取词耗费大量时间时
- 或者反过来,当数据库表和列注释内容较少时,不宜抽取标准词,宜从工作手册等文件中抽取。
- 另外,如果需要从文档中提取词和频率
1.2.词提取工具概念
词提取工具是接收各类文件作为输入,使用自然语言处理词素分析器提取词和复合词,输出频率和来源(文件名、表名、列名等)作为Excel文件。
Mecab 是一种韩语自然语言处理 (NLP) 词素分析器,在 Python v3.8 中使用和开发。 Kkma、Komoran、Hannanum、Okt(以前称为 Twitter)和 Mecab 是韩国自然语言处理词素分析器中的代表性库。其中,Mecab 因其性能最好而被选中。
自然语言处理语素分析器的性能比较可以在下面的链接中找到。
参考: https://konlpy.org/ko/latest/morph/#comparison-between-pos-tagging-classes
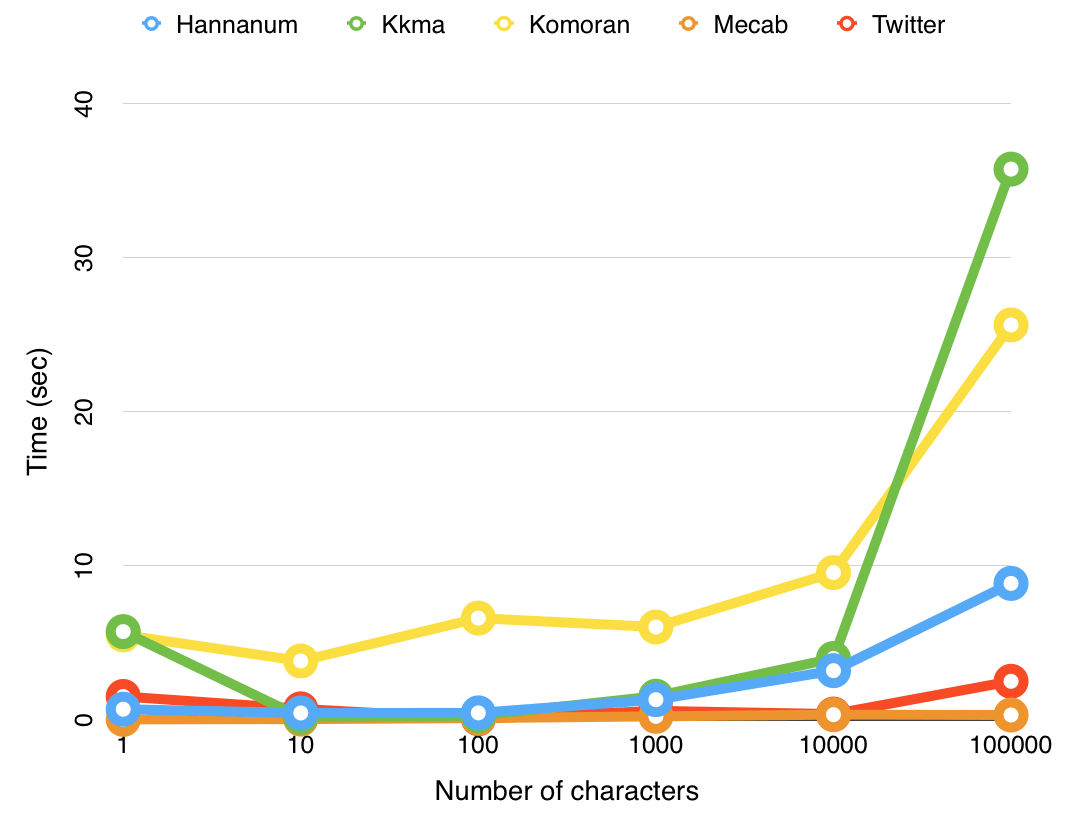
根据输入字符数的增加,执行时间可以总结如下。 (从左到右执行时间减少,性能提高)
Kkma > Komoran > Hannanum > Okt (推特) > Mecab
作为参考,上面的链接是 KoNLPy 包这是开发它的人的网站。 KoNLPy是一个基于 Python 的包,它将多个语素分析器捆绑在一起。
KoNLPy: https://konlpy.org/ko/latest/
1.3.单词提取器的工作原理
简要看一下输入数据、处理逻辑和输出数据。
1.3.1.词提取工具输入材料
可以通过以下两种方式之一或两种方式指定输入数据。
- 文档:MS Word、PowerPoint、文本文件
- 在撰写本文时(2021-08-29),尚不支持 HWP 和 PDF 格式。
- 数据库表,列注释来源:Excel 文件
- 表注释数据项:Database、Schema、Table Name、Table Comment
- 列注释数据项:Database, Schema, Table Name, Table Comment, Column Name, Column Comment
▼ 表格注释数据示例如下。
| 数据库 | 图式 | 表名 | 表注释 |
| DB1 | 所有者1 | 计算机管理代码 | 行政代码 |
| DB1 | 所有者1 | COMTCADMINIST代码接收日志 | 管理代码接收日志 |
| DB1 | 所有者1 | COMTCCMNCL代码 | 常用分类码 |
| DB1 | 所有者1 | COMTCCMN代码 | 公共代码 |
| DB1 | 所有者1 | COMTCCMN详细代码 | 常用明细代码 |
▼ 栏目评论数据示例如下。这是上表列表中COMTCADMINISTCODE(管理代码)的列列表。
| 数据库 | 图式 | 表名 | 列名 | 专栏评论 |
| DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_SE | 行政区划 |
| DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_CODE | 行政区划代码 |
| DB1 | 所有者1 | 计算机管理代码 | 使用_AT | 是否使用 |
| DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_NM | 行政区名 |
| DB1 | 所有者1 | 计算机管理代码 | UPPER_ADMINIST_ZONE_CODE | 上行政区代码 |
| DB1 | 所有者1 | 计算机管理代码 | 创建_DE | 创建日期 |
| DB1 | 所有者1 | 计算机管理代码 | ABL_DE | 废除日期 |
| DB1 | 所有者1 | 计算机管理代码 | FRST_REGIST_PNTTM | 首次注册 |
| DB1 | 所有者1 | 计算机管理代码 | FRST_REGISTER_ID | 初始注册人 ID |
| DB1 | 所有者1 | 计算机管理代码 | LAST_UPDT_PNTTM | 最后修改时间 |
| DB1 | 所有者1 | 计算机管理代码 | LAST_UPDUSR_ID | 最后修改 ID |
* 上面的示例数据是使用电子政务标准框架v3.8的“公共组件表配置信息”页面中的表和列注释脚本创建的。
(资源: https://www.egovframe.go.kr/wiki/doku.php?id=egovframework:com:v3.8:init_table)
1.3.2.分词工具处理逻辑
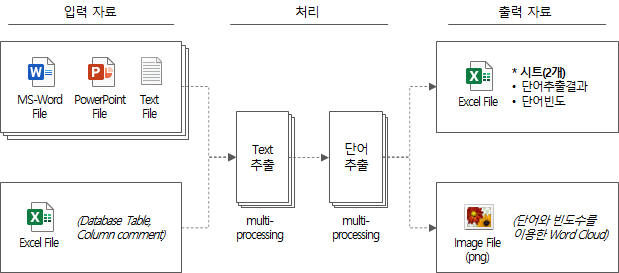
整个处理逻辑简单总结如下。
- 通过按顺序打开输入数据来提取文本(逐行、表格/列)
- 使用自然语言词素分析器包Mecab提取1个名词、n个名词、前缀+n个名词、n个名词+后缀、前缀+n个名词+后缀形式的候选词
- 查找从整个输入数据中提取的单词的频率,并将单词提取结果保存为输出文件
- 使用单词列表和频率创建单词云并将其保存为 png 文件
- 输出总所需时间并退出
上述过程的简化图如下。
1.3.3.词提取工具输出数据
输出数据是处理输入数据的结果,是一个 Excel 文件和一个词云形式的图像 (png) 文件。
Excel 文件由两张表组成。以下是以DB Table 和Column 注释数据作为输入的示例。
▼ “单词提取结果示例”表
| 不 | 单词 | 文件名 | 文件类型 | 页 | 文本 | D B | 图式 | 桌子 | 柱子 |
| 1 | 行政 | 表格,列评论.xlsx | 柱子 | 0 | 行政区划 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_SE |
| 2 | 区域 | 表格,列评论.xlsx | 柱子 | 0 | 行政区划 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_SE |
| 3 | 分配 | 表格,列评论.xlsx | 柱子 | 0 | 行政区划 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_SE |
| 4 | 行政区划[复合] | 表格,列评论.xlsx | 柱子 | 0 | 行政区划 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_SE |
| 5 | 行政 | 表格,列评论.xlsx | 柱子 | 0 | 行政区划代码 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_CODE |
| 6 | 区域 | 表格,列评论.xlsx | 柱子 | 0 | 行政区划代码 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_CODE |
| 7 | 代码 | 表格,列评论.xlsx | 柱子 | 0 | 行政区划代码 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_CODE |
| 8 | 行政区号[复合] | 表格,列评论.xlsx | 柱子 | 0 | 行政区划代码 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_CODE |
| 9 | 使用 | 表格,列评论.xlsx | 柱子 | 0 | 是否使用 | DB1 | 所有者1 | 计算机管理代码 | 使用_AT |
| 10 | 无论 | 表格,列评论.xlsx | 柱子 | 0 | 是否使用 | DB1 | 所有者1 | 计算机管理代码 | 使用_AT |
| 11 | 是否使用[复合词] | 表格,列评论.xlsx | 柱子 | 0 | 是否使用 | DB1 | 所有者1 | 计算机管理代码 | 使用_AT |
| 12 | 地区 | 表格,列评论.xlsx | 柱子 | 0 | 行政区名 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_NM |
| 13 | 站名 | 表格,列评论.xlsx | 柱子 | 0 | 行政区名 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_NM |
| 14 | 行政区名[复合] | 表格,列评论.xlsx | 柱子 | 0 | 行政区名 | DB1 | 所有者1 | 计算机管理代码 | ADMINIST_ZONE_NM |
- “文本”列:这是从输入数据中提取的原始值,在本例中对应表、列注释。
- “Word”列:使用 Mecab 从文本中提取的候选词。对于复合词,指定“[复合词]”作为后缀。
- 第12行“行政区”、第13行“站名”是从麦卡客的“行政名称”中提取出来的词。
- 可以看出准确率不是100%,因为提取的和实际使用的词不一样。
▼ “词频”表格示例
| 单词 | 频率 | 来源 |
| 代码 | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(行政区域代码) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(更改标识码) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(尝试代码) …… |
| 数字 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(作业流水号) DB1.OWNER1.COMTCZIP.ZIP(邮政编码) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(批准号) …… |
| 人数 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(地址簿名称) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(分类代号) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM(代号) …… |
| 天 | 85 | DB1.OWNER1.COMTCADMINISTCODE.CREAT_DE(创建日期) DB1.OWNER1.COMTCADMINISTCODE.ABL_DE(停用日期) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OCCRRNC_DE(发生日期) …… |
| 信息 | 77 | DB1.OWNER1.COMTHDBMNTRNGLOGINFO.LOG_INFO(日志信息) DB1.OWNER1.COMTNBAKUPRESULT.ERROR_INFO(错误信息) DB1.OWNER1.COMTNINDVDLINFOPOLICY.INDVDL_INFO_POLICY_ID(隐私政策 ID) …… |
| 无论 | 75 | DB1.OWNER1.COMTCADMINISTCODE.USE_AT(是否使用) DB1.OWNER1.COMTNANNVRSRYMANAGE.REPTIT_AT(是否重复) DB1.OWNER1.COMTNBANER.REFLCT_AT(是否反射) …… |
- “Word”列:这是从“Word Extraction Result”表的“Word”列中去除重复项得到的字符串值。该值是要注册为标准词的候选值。
- “Freq”列:这是频率计数,表示该词被使用了多少次。结果列表按从这些高频词到低频词的相反顺序排序。
- “出处”栏:表示词的出处。最多显示 10 个来源。
- 如果源是Table,则格式为:DB.Schema.TableName(Table comment)
- 如果源是Column,则格式为:DB.Schema.TableName.ColumnName(Column comment)
- 如果来源是文件格式:文件名:页码:文本
提取词频生成的词云图示例如下。高频词以大号显示。

分词工具是使用Python开发的工具,在执行前需要安装Python和必要的包等环境配置过程。接下来,我们来看一下环境配置过程。
<< 相关文章列表 >>

















