分词工具(二):配置分词工具的执行环境
分词工具是用Python开发的工具,在执行前需要安装Python和必要的包等环境配置过程。下面我们来看一下分词工具的执行环境的配置。
这是上一篇文章的延续。
2. 分词工具执行环境的配置
2.1.环境配置概览
2.1.1.建议
建议安装 Miniconda 而不是 Anaconda。 Anaconda 在默认环境中安装了太多的包,这使得它变得很大。我们推荐使用 Miniconda,因为它小巧轻便。
如果没有安装 Miniconda,建议安装 virtualenv。如果将包安装在与基础环境隔离的单独环境中,则可以避免包版本冲突等问题。
如果判断没有问题或者只是使用了分词器,那么使用默认环境就可以了。本文介绍如何在 Windows 10 64 位上使用 Miniconda。
2.1.2.选择词干分析器:Mecab
选择 Mecab 是因为它是开放式自然语言词素分析器中执行速度最快的,并且最适合单词提取的目的。要使用 Mecab 以外的语素分析器,您可以重写 get_word_list() 函数。
2.1.3.环境配置的总体顺序
- 安装 Miniconda
- 创建和激活虚拟环境
- 在虚拟环境中安装 Python
- 安装虚拟环境所需的包(如果不使用虚拟环境则在基础环境安装)
2.2.安装 Miniconda
https://conda.io/en/latest/miniconda.html#windows-installers 从 中选择并下载 Python 版本。分词工具是在Python 3.8开发的,在3.9中运行良好。这里我们将下载并安装3.9。
执行下载的文件 (Miniconda3-py39_4.10.3-Windows-x86_64.exe) 以继续安装。单击下一步按钮几次以完成安装。

后续任务从 Miniconda 提示执行。您可以从以下路径运行它。
开始菜单 > Anaconda3(64 位)> Anaconda Prompt (miniconda3)
2.3.创建和激活虚拟环境
当你第一次运行 Miniconda Prompt 时,基础环境(base)被激活。 (见上图)
为单词提取工具创建一个单独的虚拟环境。
(base) C:\Users\ymlee>conda create -n wordextr
使用以下命令激活创建的虚拟环境。如果执行命令后虚拟环境名(wordextr)出现在前面,则正常激活。
(base) C:\Users\ymlee>conda activate wordextr (wordextr) C:\Users\ymlee>
2.4.在虚拟环境中安装 Python
运行以下命令。
(wordextr) C:\Users\ymlee>conda install python
输出如下所示:
(wordextr) C:\Users\ymlee>conda install python
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: C:\Users\ymlee\miniconda3\envs\wordextr
added / updated specs:
- python
The following NEW packages will be INSTALLED:
ca-certificates pkgs/main/win-64::ca-certificates-2021.7.5-haa95532_1
certifi pkgs/main/win-64::certifi-2021.5.30-py39haa95532_0
openssl pkgs/main/win-64::openssl-1.1.1l-h2bbff1b_0
pip pkgs/main/win-64::pip-21.2.4-py38haa95532_0
python pkgs/main/win-64::python-3.9.7-h6244533_1
setuptools pkgs/main/win-64::setuptools-58.0.4-py39haa95532_0
sqlite pkgs/main/win-64::sqlite-3.36.0-h2bbff1b_0
tzdata pkgs/main/noarch::tzdata-2021a-h5d7bf9c_0
vc pkgs/main/win-64::vc-14.2-h21ff451_1
vs2015_runtime pkgs/main/win-64::vs2015_runtime-14.27.29016-h5e58377_2
wheel pkgs/main/noarch::wheel-0.37.0-pyhd3eb1b0_1
wincertstore pkgs/main/win-64::wincertstore-0.2-py39h2bbff1b_0
Proceed ([y]/n)?
只需按 Enter 或键入 y 并按 Enter 即可开始安装。作为参考,如果您不想安装它,请键入 n 并按 Enter。
2.5.安装所需的包
使用以下命令安装必要的包:由于conda没有提供wordcloud和eunjeon,所以必须用pip安装。
conda install pywin32 conda install pandas conda install Jinja2 conda install xlsxwriter pip install wordcloud pip install eunjeon
每个包的用途如下。
- pywin32:用于在 OLE 自动化中打开和读取 MS Word、PowerPoint 和 Excel 文件
- pandas:用于管理内存中的取词结果,最后保存到excel文件中
- Jinja2、xlsxwriter:用于pandas中的ExcelWriter
- wordcloud:用于可视化取词结果
- eunjeon:使用韩语语素分析器 Mecab
安装eunjeon时,“需要Microsoft Visual C++ 14.0或更高版本。”如果发生错误,请从以下 URL 下载并安装“可再发行软件包和构建工具”中的“Microsoft Build Tools 2015 Update 3”,然后重试。
https://visualstudio.microsoft.com/ko/vs/older-downloads/#microsoft-build-tools-2015-update-3
安装时选择“Desktop development using C++”并安装。 (下图为安装后截取的画面,与安装时的画面略有不同)
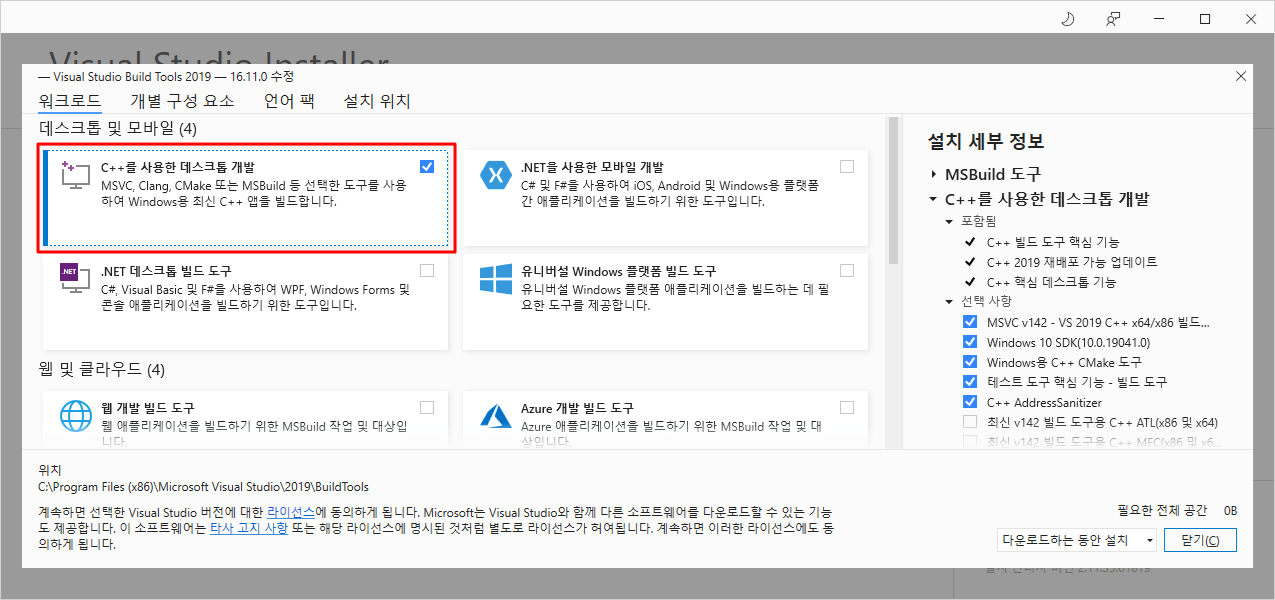
安装“Microsoft Build Tools 2015 Update 3”后,使用以下命令安装 eunjeon。
pip install eunjeon
如果 eunjeon 安装完成,您可以删除“Microsoft Build Tools 2015 Update 3”。
从开始菜单运行'Visual Studio Installer',取消选择“使用C++的桌面开发”,然后单击右下角的“修改”按钮将其删除。


至此,环境的配置就完成了。接下来,我们将了解如何运行单词提取工具并检查结果。
<< 相关文章列表 >>


















(wordextr) E:\WordExtractor>python word_extractor.py –in_path .\in –out_path .\out
我是一个初学者,第一次使用Python。我按照上面的方法运行并得到以下结果。好像是路线指定有问题,但我是新手,解决不了。我将感谢您的帮助(输入和输出文件夹已正确创建)。
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
————————————————————
单词提取器 v0.41 开始 — 2023-11-20 03:13:07.584787
##### 参数 #####
多进程计数:32
db_comment_file:无
in_path: .\in
输出路径:.\输出
————————————————————
[2023-11-20 03:13:07.586789] 开始获取文件列表...
[2023-11-20 03:13:07.586789] 完成获取文件列表。
— 文件列表 —
E:\WordExtractor\in\test.txt
[2023-11-20 03:13:07.588790] 开始获取文件文本...
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
E:\WordExtractor\word_extractor.py:382: SyntaxWarning: 无效的转义序列 '\o'
use_description = “””— 描述 —
E:\WordExtractor\word_extractor.py:406: SyntaxWarning: 无效的转义序列 '\i'
parser.add_argument('–in_path', required=False, help='输入文件(ppt, doc, txt)路径名(例如.\in) ')
E:\WordExtractor\word_extractor.py:407: SyntaxWarning: 无效的转义序列 '\o'
parser.add_argument('–out_path', required=True, help='输出文件(xlsx, png)路径名(例如.\out)')
get_txt_text: E:\WordExtractor\in\test.txt
multiprocessing.pool.RemoteTraceback:
“””
回溯(最近一次调用最后一次):
文件“C:\ProgramData\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 125 行,在worker中
结果 = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
文件“C:\ProgramData\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 48 行,在 mapstar 中
返回列表(地图(*args))
^^^^^^^^^^^^^^^^
文件“E:\WordExtractor\word_extractor.py”,第 367 行,在 get_file_text 中
df_text = get_txt_text(文件名)
^^^^^^^^^^^^^^^^^^^^^^^
文件“E:\WordExtractor\word_extractor.py”,第 238 行,get_txt_text
df_text = df_text.append(sr_text, ignore_index=True)
^^^^^^^^^^^^^^
文件“C:\ProgramData\miniconda3\envs\wordextr\Lib\site-packages\pandas\core\generic.py”,第 6204 行,在 __getattr__ 中
返回对象.__getattribute__(self, name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError:“DataFrame”对象没有属性“append”。您的意思是:“_append”吗?
“””
上述异常是导致以下异常的直接原因:
回溯(最近一次调用最后一次):
文件“E:\WordExtractor\word_extractor.py”,第 559 行,位于
主要的()
文件“E:\WordExtractor\word_extractor.py”,第 460 行,在 main 中
mp_text_result = pool.map(get_file_text, file_list)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“C:\ProgramData\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 367 行,在地图中
返回 self._map_async(func, iterable, mapstar, chunksize).get()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
文件“C:\ProgramData\miniconda3\envs\wordextr\Lib\multiprocessing\pool.py”,第 774 行,在 get 中
提高自我价值
AttributeError:“DataFrame”对象没有属性“append”
(wordextr) E:\WordExtractor>
你好很高兴见到你。
由于这是我没有遇到过的错误,因此很难立即告诉您如何解决它。
你能检查一下并告诉我Python版本、numpy和pandas版本吗?
我认为你需要检查一下,因为版本不同。
作为参考,我实现并测试的环境版本如下。
– Python:3.9.6(如何检查:python –版本)
– numpy:1.20.3(如何检查:pip list)(您也可以立即检查下面的 pandas)
– 熊猫:1.3.1
我也有同样的错误。我按照你分享的包的版本运行了一下,成功了。
你好。我有一个关于 Anaconda 安装的问题。我想使用公司内部的单词提取工具,但是由于Anaconda是付费的,所以公司建议使用miniforge。安装miniforge后使用单词提取工具,功能上会有什么区别吗?
我没有使用过miniforge,所以不知道功能上会不会有区别。
安装miniconda的目的是为了轻松创建和管理虚拟环境,而不是为了方便安装包。
尝试这个:
– 使用 venv 或 virtualenv 代替 miniconda(请参阅: https://richwind.co.kr/193)
– “2.5。将“安装必要的包”内容中的“conda install”更改为“pip install”。
我希望这会顺利。
首先,我安装了miniforge,并在Miniforge Prompt下执行了上述过程,但什么也没发生。
而且您提到的“Microsoft Build Tools 2015 Update 3”安装得不好,所以我安装了Microsoft Build Tools 2022并收到了eunjeon。
现在我将尝试提取工具并向您提供反馈 🙂
希望运行顺利^^