1. DML任务中的并行性概述(DBMS_PARALLEL_EXECUTE)
介绍 DBMS_PARALLEL_EXECUTE,它可以从 Oracle 11g R2 开始使用,并检查用例。
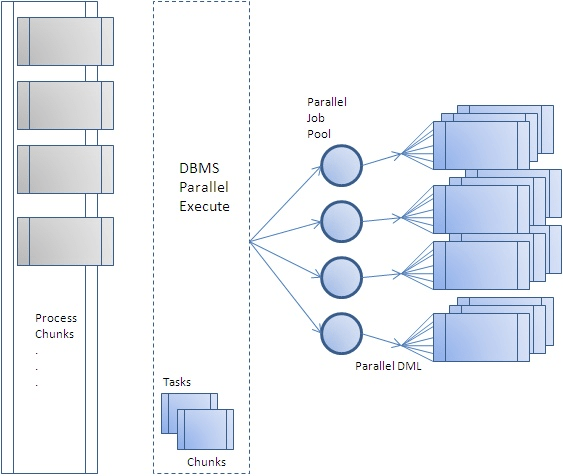
图片来源: https://blogs.oracle.com/warehousebuilder/parallel-processing-with-dbmsparallelexecute
一、DML任务并行处理概述
1.1. DML并行处理方法
当您想使用尽可能多的资源快速处理数据库中的一个 DML(INSERT、UPDATE、DELETE)作业时,使用并行处理。并行处理有两种主要方法。
第一种方法是在执行一个 SQL 时指定并行度作为提示(Parallel DML,单事务),第二种方法是通过指定数据范围(Program Parallel DML,多事务)来执行多个 SQL。)am .
在大多数情况下,第一种方法,即 Parallel DML 方法,在数据一致性方面具有优势,因为它是作为单个事务处理的。但是,如果第一种方法无法应用或者您想自己定义工作单元的大小或范围,则最好应用第二种方法。 (所以第二种方法也叫DIY(Do It Yourself)并行DML)
无法应用并行 DML 的情况示例如下。
- 用于选择包含 LOB 列的表的 DML
- 数据库链接上的 DML
- 在 PL/SQL 单元中并行处理 DML,而不是在复杂过程中实现的 SQL 单元或过程单元
- 未在 PL/SQL 中实现并在 Java 等语言中运行的 DML
执行Program Parallel DML的步骤会根据情况略有不同,但大体如下。
- 工作目标的选择
- 选择并行度和工作单元的划分(Partition、date、number、ROWID等)->按工作单元创建.sql文件
- 任务执行和监控 -> 在单个会话(SQL*Plus 等)中执行每个 .sql 文件
- 确认任务完成->验证行数比较、总和比较等。
当需求或情况发生变化,需要更改并行度(DOP)或需要返工时,重复执行步骤2和步骤3,管理和确认并不简单。每当需要更改时,都必须一遍又一遍地手动重复类似的任务,这很不方便。
1.2. DBMS_PARALLEL_EXECUTE 概念
在使用Program Parallel方式时,使用DBMS_PARALLEL_EXECUTE可以更方便的执行和管理这个任务。
* 参考甲骨文文件: http://docs.oracle.com/cd/E11882_01/appdev.112/e40758/d_parallel_ex.htm#ARPLS233
(作为参考,DBMS_PARALLEL_EXECUTE 在内部使用 JOB,因此必须将 CREATE JOB 权限授予执行用户。)
DBMS_PARALLEL_EXECUTE 是 Oracle 11g R2 中作为新特性引入的包。主要子程序列表如下表所示,完整列表和解释可以在Oracle文档中找到。
| 子程序 | 解释 |
| CREATE_TASK 过程 | 创建任务 |
| CREATE_CHUNKS_BY_NUMBER_COL 程序 | 按 NUMBER 列创建块 |
| CREATE_CHUNKS_BY_ROWID 程序 | 使用 ROWID 创建块 |
| CREATE_CHUNKS_BY_SQL 过程 | 使用自定义 SQL 创建块 |
| DROP_TASK 程序 | 删除任务 |
| DROP_CHUNKS 程序 | 消除块 |
| RESUME_TASK 程序 | 重新运行停止的任务 |
| RUN_TASK 程序 | 执行任务 |
| STOP_TASK 过程 | 停止任务 |
| TASK_STATUS 程序 | 返回任务当前状态 |
应用 DBMS_PARALLEL_EXECUTE 的步骤与执行 Program Parallel DML 的步骤几乎相似,如下所示。
- 创建任务 (CREATE_TASK)
- 划分工作单元(chunk)(提供ROWID、NUMBER、SQL三种方法)
- CREATE_CHUNKS_BY_ROWID
- CREATE_CHUNKS_BY_NUMBER_COL
- 创建_CHUNKS_BY_SQL
- 运行任务 (RUN_TASK)
- 任务完成后删除(DROP_TASK)
1.3.为 DBMS_PARALLEL_EXECUTE 测试创建表和数据
使用以下脚本创建要测试的表和数据。
-- 테스트 테이블과 데이터 생성
DROP TABLE Z_DPE_TEST_TAB PURGE;
CREATE TABLE Z_DPE_TEST_TAB (
ID NUMBER(10)
,MSG VARCHAR2(100)
,VAL NUMBER
,AUDSID NUMBER
) NOLOGGING;
-- 100만건 테스트 데이터 생성
INSERT /*+ APPEND */ INTO Z_DPE_TEST_TAB (ID, MSG)
SELECT LEVEL AS ID
,'Test Data ID: ' || TO_CHAR(LEVEL)
FROM DUAL
CONNECT BY LEVEL <= 1000000;
COMMIT;
测试中要用到4个列,每个列的用途如下。
| 列名 | 用法 |
| ID | 用于标识表中每一行的值 |
| 味精 | 提供描述的值 |
| 值 | 测试执行中更新的随机值 |
| 澳元ID | 检查运行测试的会话数的值。 它用 SYS_CONTEXT('USERENV','SESSIONID') 更新。 |
作为参考,进行该测试的环境如下。
- DBMS:Oracle 11g R2 Enterprise 11.2.0.1.0 32 位(在 Windows 7 x64 上)
- 硬件:CPU i5-5200U 2.20GHz,内存 8GB,SSD 250GB
下面我们通过划分每个工作单元(chunk)的方式来看一个案例。















非常感谢!