Release Word Extraction Tool v0.41: 增加DBSchema出现频率项
* 也请参考新发布的v0.42 修复bug。
发布 Word Extractor v0.42:错误修复 – 生产力技能 (prodskill.com)
在之前分发的词提取工具(v0.40)中补充添加和提取DBSchema出现频率项的功能后分发。 DBSchema_Freq 项通知词源分布了多少个 DB-Schemas。
参考: 分词工具(一):分词工具概述

1. 分词工具结果变化
之前分发的工具的词提取结果示例如下。
▼ 更改前的“词频”表示例 (v0.40)
| 单词 | 频率 | 来源 |
| 代码 | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(行政区域代码) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(更改标识码) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(尝试代码) …… |
| 数字 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(作业流水号) DB1.OWNER1.COMTCZIP.ZIP(邮政编码) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(批准号) …… |
| 人数 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(地址簿名称) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(分类代号) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM(代号) …… |
DBSchema_Freq 项添加到从 v0.41 提取的结果中,如下所示。
▼ 更改后的“词频”表示例 (v0.41)
| 单词 | 频率 | 来源 | DBSchema_Freq |
| 代码 | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(行政区域代码) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(更改标识码) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(尝试代码) …… | 10 |
| 数字 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(作业流水号) DB1.OWNER1.COMTCZIP.ZIP(邮政编码) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(批准号) …… | 9 |
| 人数 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(地址簿名称) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(分类代号) DB1.OWNER1.COMTCCMNDETAILCODE.CODE_NM(代号) …… | 5 |
DBSchema_Freq 项通知词源分布了多少个 DB-Schemas。可以更详细地提供选择标准候选词所需的信息。
- 当频率(Freq)高但DBSchema频率(DBSchema_Freq)低时
- 该词仅在特定的 DB-Schema 中密集出现
- 当频率(Freq)和DBSchema频率(DBSchema_Freq)都很高时
- 这个词均匀分布在整个 DB-Schema 中
- 当频率(Freq)较低但DBSchema频率(DBSchema_Freq)相对较高时
- 该词被审查为包含而不是排除在规范词候选者中
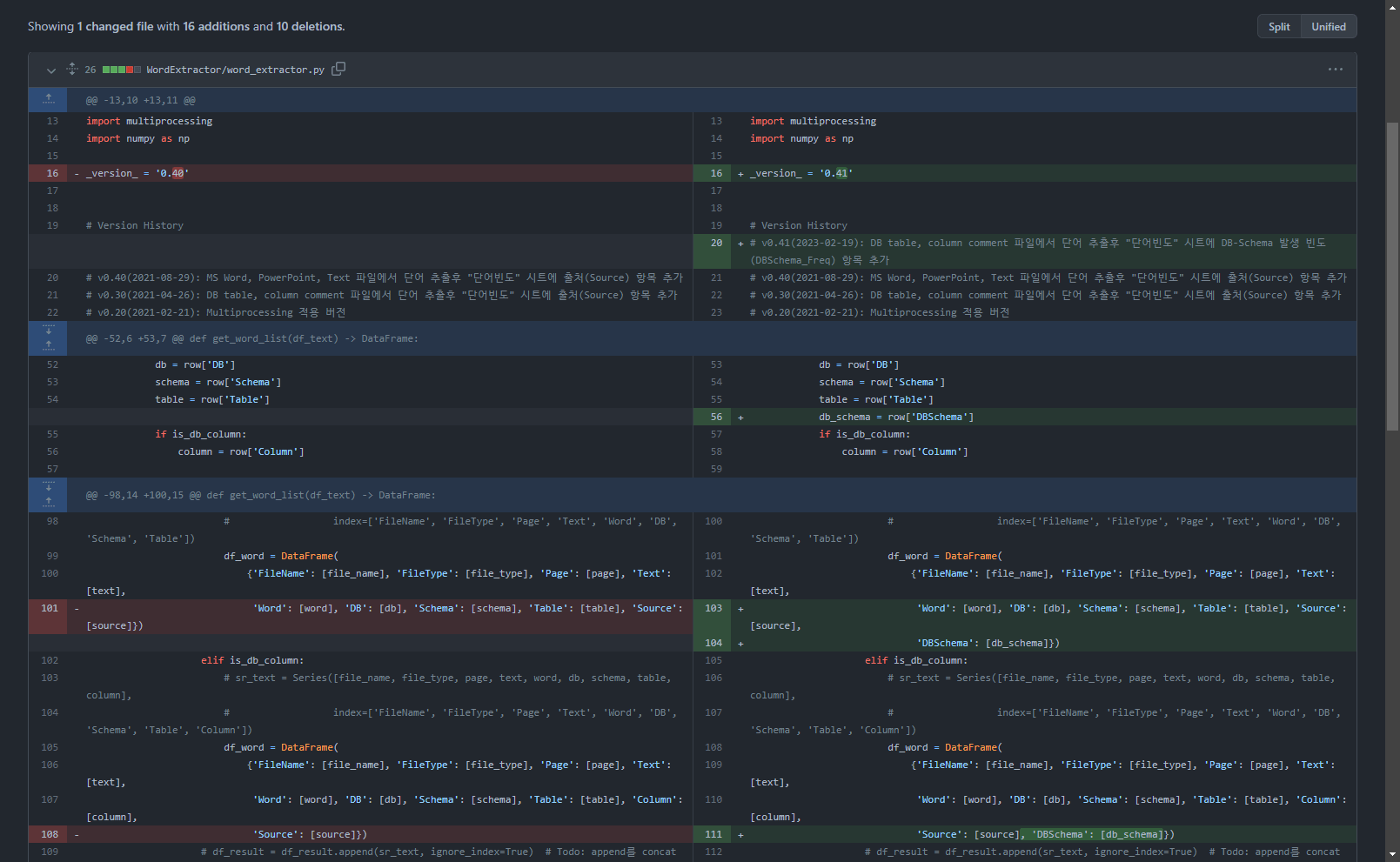
2.源码改动
三个函数发生了变化。
2.1.更改了 get_db_comment_text 函数
添加第343行:在包含文本提取结果的dataframe变量df_text中创建一个DBSchema列并创建一个值。
df_text['DBSchema'] = df_text['DB'] + '.' + df_text['Schema'] # DB.Schema 값 생성(2023-02-19)
2.2.更改 get_word_list 函数
添加第104、111行:将DBSchema值添加到分词结果dataframe
if len(words) >= 1:
# print(nouns, text)
for word in words:
# print(noun, '\t', text)
if not is_db:
# sr_text = Series([file_name, file_type, page, text, word],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'Source': [source]})
elif is_db_table:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Source': [source],
'DBSchema': [db_schema]})
elif is_db_column:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table, column],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table', 'Column'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Column': [column],
'Source': [source], 'DBSchema': [db_schema]})
2.3.更改主函数
2.3.1.变更前的主要功能内容
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
2.3.2.变更后的主要功能内容
df_group = df_result.groupby('Word').agg({
'Word': 'count',
'Source': lambda x: '\n'.join(list(x)[:10]),
'DBSchema': 'nunique'
}).rename(columns={
'Word': 'Freq',
'Source': 'Source',
'DBSchema': 'DBSchema_Freq'
})
这段代码对df_result中的词(word)进行分组,df_result是一个dataframe变量,作为词提取的结果(groupby),得到去除重复的DBSchema值的个数(nunique),并将该项命名为DBSchema_Freq。
作为参考,这段代码是我写的测试代码。 聊天GPT这是提供给并要求简化的代码。在简化之前,它是一个复杂的代码,分为两个数据框,分别应用 lambda 和 nunique,然后将它们合并为一个。最近 聊天GPT 佩服能力
2.4. v0.41 中更改的源代码的完整详细信息
您可以在下面的 github 链接中查看更改的详细信息。
3. 下载并运行词提取工具 (v0.41)
您可以在下面的链接中查看更改后的 word_extractor.py 文件。
DAToolset/ToolsForDataStandard (github.com) 中的 ToolsForDataStandard/word_extractor.py
执行方式同v0.40。请参考以下信息。
词提取工具 v0.41 未经过充分测试,可能会引入错误或错误。请在评论中留下任何错误、错误、查询等。


















你好!
当使用从没有DB注释的文件中提取单词的方法时,这是三种执行方法之一
(python word_extractor.py –in_path .\in –out_path .\out)
txt, word, ppt 全部
miniconda3\envs\wordextr\lib\site-packages\pandas\core\apply.py”,第 601 行,在 normalize_dictlike_arg raise KeyError(f”Column(s) {cols_sorted} 不存在”)
KeyError:“列 ['DBSchema'] 不存在”
它正在退出并出现错误。
输入 DB 注释文件的执行方法 2 和 3 没有错误。
我把 'DBSchema': [db_schema] 放在第 97 行,但是这次
在 get_grouper raise KeyError(gpr) KeyError: 'Word' 错误被显示。
谢谢
感谢您报告错误。
您在未测试仅从文件中提取单词的情况下进行了部署。
我们将很快重新发布经过测试和错误修复的版本。
重新发布 v0.42 并修复了错误。
https://prodskill.com/ko/word-extractor-v0-42-bug-fix-for-dbschema/
谢谢