4.自定义SQL分区方式并行处理案例(DBMS_PARALLEL_EXECUTE)
让我们看一下使用Oracle DBMS_PARALLEL_EXECUTE 的用户自定义SQL 分区并行的情况。包括编写用户自定义SQL、测试环境、作业创建、作业划分、作业执行、作业完成确认和删除。
这是上一篇文章的延续。
3. NUMBER列分区法并行处理案例(DBMS_PARALLEL_EXECUTE)
* 参考甲骨文文档: DBMS_PARALLEL_EXECUTE – CREATE_CHUNKS_BY_SQL 过程 (oracle.com)
4.自定义SQL分区并行处理案例
4.1.自定义 SQL 分区方法概述
通过用户定义的 SQL 进行分区在以下情况下很有用。
- 在 ROWID 分区方法不支持的情况下进行分区(例如,通过 DB Link 对远程表进行 ROWID 分区)
- 根据 NUMBER 列以外的列(VARCHAR2、DATE 等)进行拆分
这里就第一种情况通过DB Link划分ROWID的情况进行说明。
如果您尝试使用 CREATE_CHUNKS_BY_ROWID 通过 DB Link 拆分表的 ROWID,发生错误。
-- 1단계: 작업생성
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)');
END;
/
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE
.CREATE_CHUNKS_BY_ROWID(TASK_NAME => 'DPE_TEST(BY ROWID, VIA DBLINK)',
TABLE_OWNER => USER,
-- TABLE _NAME을 “T1@DL_MS949”로 DB Link 지정
TABLE_NAME => 'T1@DL_MS949',
BY_ROW => TRUE,
CHUNK_SIZE => 10000);
END;
/
--> 실행 오류 메시지
ORA-29491: 조각에 부적합한 테이블
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 27행
ORA-06512: "SYS.DBMS_PARALLEL_EXECUTE", 121행
ORA-06512: 4행
在这种情况下,可以通过CREATE_CHUNKS_BY_SQL 来创建和应用在DB Link 上划分表的ROWID 的SQL。
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL ( task_name IN VARCHAR2, sql_stmt IN CLOB, by_rowid IN BOOLEAN);
sql_stmt是CLOB类型,使用时几乎没有长度限制,但这里建议使用流水线函数,而不是直接描述SQL。
4.2.编写自定义 SQL
创建一个用户定义的类型,并创建一个返回该类型结果集的流水线函数,如下所示。
-- 1. TYPE 생성 (Pipe-Lined function에서 return하기 위함)
CREATE OR REPLACE TYPE TP_ROWID_RANGE AS OBJECT (
START_ROWID VARCHAR2(50)
,END_ROWID VARCHAR2(50)
);
CREATE OR REPLACE TYPE TL_ROWID_RANGE AS TABLE OF TP_ROWID_RANGE;
-- 2. Function 생성
CREATE OR REPLACE FUNCTION FN_SPLIT_BY_ROWID(
I_OWNER IN VARCHAR2, I_TABLE_NAME IN VARCHAR2, I_CHUNKS IN NUMBER)
RETURN TL_ROWID_RANGE
PIPELINED
AS
CURSOR C_ROWID_RANGE (CP_OWNER VARCHAR2, CP_TABLE_NAME VARCHAR2, CP_CHUNKS NUMBER)
IS
SELECT GRP,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, LO_FNO, LO_BLOCK, 0 ) MIN_RID,
DBMS_ROWID.ROWID_CREATE( 1, DATA_OBJECT_ID, HI_FNO, HI_BLOCK, 10000 ) MAX_RID
FROM (
SELECT DISTINCT GRP,
FIRST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_FNO,
FIRST_VALUE(BLOCK_ID)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) LO_BLOCK,
LAST_VALUE(RELATIVE_FNO)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_FNO,
LAST_VALUE(BLOCK_ID+BLOCKS-1)
OVER (PARTITION BY GRP ORDER BY RELATIVE_FNO, BLOCK_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) HI_BLOCK,
SUM(BLOCKS) OVER (PARTITION BY GRP) SUM_BLOCKS
FROM (
SELECT RELATIVE_FNO, BLOCK_ID, BLOCKS,
TRUNC( (SUM(BLOCKS) OVER (ORDER BY RELATIVE_FNO, BLOCK_ID)-0.01) /
(SUM(BLOCKS) OVER ()/ CP_CHUNKS) ) GRP
FROM DBA_EXTENTS@DL_MS949
WHERE SEGMENT_NAME = UPPER(CP_TABLE_NAME)
AND OWNER = UPPER(CP_OWNER)
ORDER BY BLOCK_ID
)
),
(SELECT DATA_OBJECT_ID
FROM DBA_OBJECTS@DL_MS949
WHERE OWNER = UPPER(CP_OWNER)
AND OBJECT_NAME = UPPER(CP_TABLE_NAME))
ORDER BY GRP
;
BEGIN
FOR ROWID_RANGE IN C_ROWID_RANGE(I_OWNER, I_TABLE_NAME, I_CHUNKS) LOOP
PIPE ROW(TP_ROWID_RANGE(ROWID_RANGE.MIN_RID, ROWID_RANGE.MAX_RID));
END LOOP;
RETURN;
END;
/
上述函数中使用的SQL是在DBA_EXTENTS的基础上以块为单位进行ROWID划分,参考Thomas Kyte建议的技术,稍微修改为使用DB Link。
* 参考网址: https://asktom.oracle.com/pls/asktom/f?p=100:11:0::::P11_QUESTION_ID:10498431232211
DB Link是通过指定DL_MS949来使用的,如果还想动态指定DB Link,可以将上述函数的cursor SQL改成动态SQL使用。
如果用这个函数对LEG.SUB_MON_STAT表(总数7426)按ROWID进行分区,则如下。
-- DL_MS949 DB Link상의 LEG owner, SUB_MON_STAT table에 대해 4개의 Chunk로 ROWID 분할
SELECT ROWNUM RNO, START_ROWID, END_ROWID
FROM TABLE(FN_SPLIT_BY_ROWID('LEG', 'SUB_MON_STAT', 4))
;
| Row# | START_ROWID | END_ROWID |
| 1 | AAAQXFAAEAAAACIAAA | AAAQXFAAEAAAAC3CcQ |
| 2 | AAAQXFAAEAAAAC4AAA | AAAQXFAAAEAAAADHCcQ |
| 3 | AAAQXFAAAEAAAADIAAA | AAAQXFAAAEAAAADXCcQ |
| 4 | AAAQXFAAAEAAAADYAAA | AAAQXFAAAEAAAADnCcQ |
用这里生成的ROWID拆分数据时,用下面的SQL检查整个数据是否有遗漏。
SELECT R.RNO, COUNT(*) CNT
FROM SUB_MON_STAT S
,(
SELECT 1 RNO, 'AAAQXFAAEAAAACIAAA' START_ROWID, 'AAAQXFAAEAAAAC3CcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 2 RNO, 'AAAQXFAAEAAAAC4AAA' START_ROWID, 'AAAQXFAAEAAAADHCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 3 RNO, 'AAAQXFAAEAAAADIAAA' START_ROWID, 'AAAQXFAAEAAAADXCcQ' END_ROWID FROM DUAL
UNION ALL
SELECT 4 RNO, 'AAAQXFAAEAAAADYAAA' START_ROWID, 'AAAQXFAAEAAAADnCcQ' END_ROWID FROM DUAL
) R
WHERE S.ROWID BETWEEN R.START_ROWID AND END_ROWID
GROUP BY R.RNO
ORDER BY R.RNO
;
执行结果如下。 (CNT 可能因每个测试环境而异。)
| RNO(块号) | 碳纳米管 |
| 1 | 1,790 |
| 2 | 2,206 |
| 3 | 2,209 |
| 4 | 1,221 |
CNT总和为7426,等于表的总行数,确认无遗漏。这里每个RNO划分的行数分别为1790、2206、2209、1221,不相等。这和ROWID分区方法中描述的不等分的原因是一样的。
4.3.创建测试环境和测试表
目标数据库在
- 使用 DB Link 的源数据库的桌子假设导入一个测试场景,进行如下环境配置。
- 当目标表是分区表并且 DML 是 INSERT
- 当按分区数进行分区并以分区键为单位处理数据时,直接路径 I/O 有望成为可能。 (我还没有测试过,但似乎可以)
- 需要在 INSERT 语法中使用 /*+ APPEND */ 提示并将分区设置为 NOLOGGING
- 如果目标表是非分区表
- 直接路径 I/O 是不可能的,只有传统的 I/O 是可能的
- 由于 UNDO 的数量可能非常大,因此有必要提前确保空闲存储空间。
- 如果将块大小设置为较小的大小,则可以在一定程度上限制 UNDO 的大小。
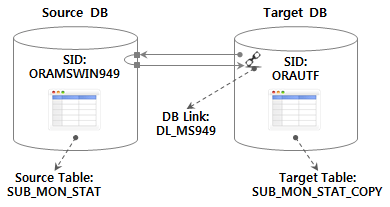
目标数据库该表是使用以下 DDL 预先创建的。
CREATE TABLE SUB_MON_STAT_COPY AS SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM, RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT FROM SUB_MON_STAT@DL_MS949 WHERE 1=2;
4.4.创造就业
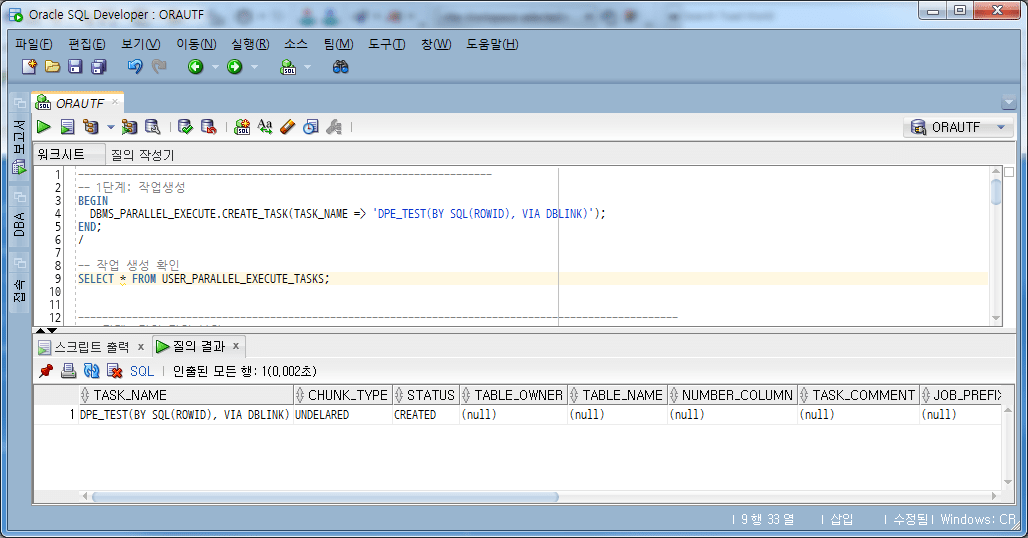
4.4.1.创造就业
-- 1단계: 작업생성 BEGIN DBMS_PARALLEL_EXECUTE.CREATE_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; / -- 작업 생성 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;
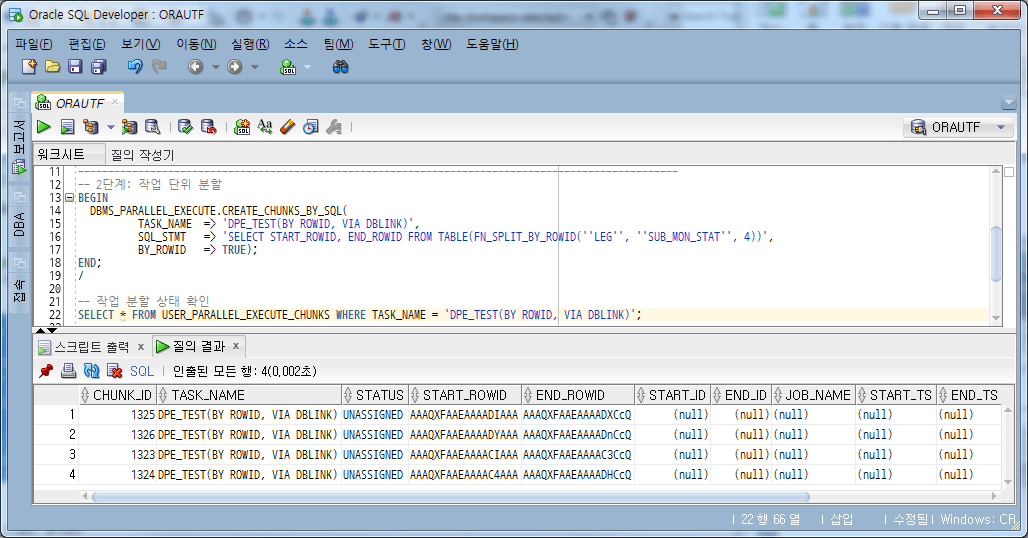
4.4.2.拆分工作单元
使用 FN_SPLIT_BY_ROWID 函数,将工作单元指定/拆分为 4 个。
-- 2단계: 작업 단위 분할
BEGIN
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_SQL(
TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => 'SELECT START_ROWID, END_ROWID FROM TABLE(FN_SPLIT_BY_ROWID(''LEG'', ''SUB_MON_STAT'', 4))',
BY_ROWID => TRUE);
END;
/
-- 작업 분할 상태 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
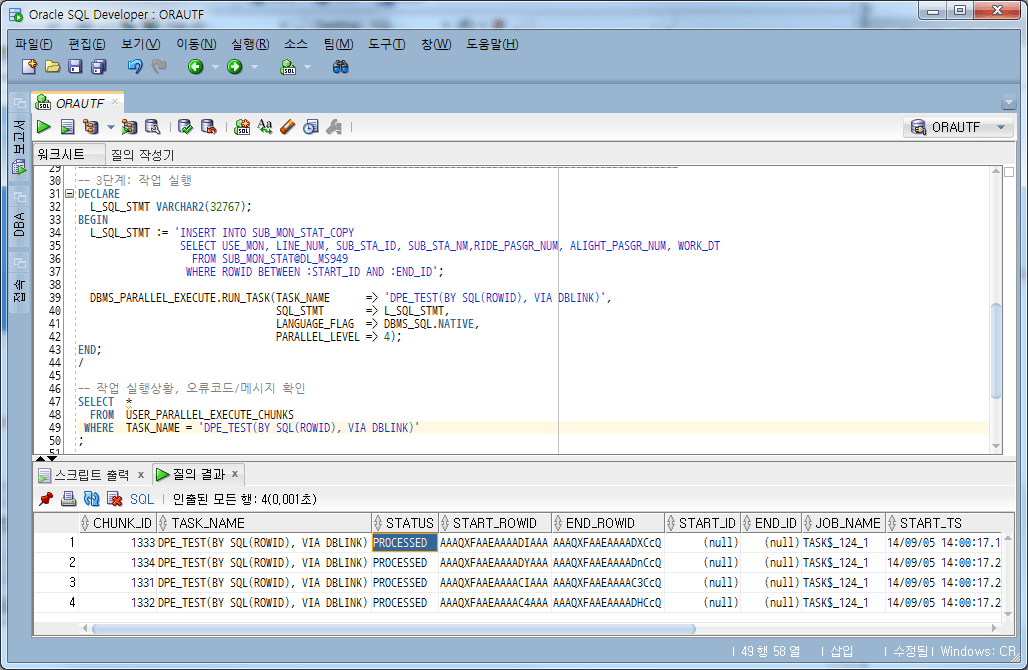
4.5.作业运行
通过在 WHERE 子句中指定 ROWID 条件来执行任务。这里任务数设置为4,与工作单元数相同。
-- 3단계: 작업 실행
DECLARE
L_SQL_STMT VARCHAR2(32767);
BEGIN
L_SQL_STMT := 'INSERT INTO SUB_MON_STAT_COPY
SELECT USE_MON, LINE_NUM, SUB_STA_ID, SUB_STA_NM,RIDE_PASGR_NUM, ALIGHT_PASGR_NUM, WORK_DT
FROM SUB_MON_STAT@DL_MS949
WHERE ROWID BETWEEN :START_ID AND :END_ID';
DBMS_PARALLEL_EXECUTE.RUN_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)',
SQL_STMT => L_SQL_STMT,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 4);
END;
/
-- 작업 실행상황, 오류코드/메시지 확인
SELECT *
FROM USER_PARALLEL_EXECUTE_CHUNKS
WHERE TASK_NAME = 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)';
4.6.确认任务完成并删除
您可以使用以下 SQL 检查作业完成情况。
-- 작업 완료 확인 SELECT * FROM USER_PARALLEL_EXECUTE_TASKS;

DROP_TASK( ) 删除作业。
-- 4단계: 작업삭제 BEGIN DBMS_PARALLEL_EXECUTE.DROP_TASK(TASK_NAME => 'DPE_TEST(BY SQL(ROWID), VIA DBLINK)'); END; /
五、注意事项
上面,我们查看了如何使用 DBMS_PARALLEL_EXECUTE。这是我几年前在一个项目中通过DB Link搜索并行加载包含CLOB列的表时发现的方法。我希望我对任何想要使用它的人都解释得足够好。
如果您有任何问题,请在评论中留下。
相关文章:
 Oracle 字符集转换(7):5.4。 KO16MSWIN949 环境 CSSCAN 执行结果
Oracle 字符集转换(7):5.4。 KO16MSWIN949 环境 CSSCAN 执行结果
 Oracle 字符集转换(6):5.3。 US7ASCII环境CSSCAN执行结果
Oracle 字符集转换(6):5.3。 US7ASCII环境CSSCAN执行结果
 Oracle字符集转换(五):5.Oracle推荐实践
Oracle字符集转换(五):5.Oracle推荐实践
 DBMS_PARALLEL_EXECUTE 说明 目录
DBMS_PARALLEL_EXECUTE 说明 目录
 3. NUMBER列分区法并行处理案例(DBMS_PARALLEL_EXECUTE)
3. NUMBER列分区法并行处理案例(DBMS_PARALLEL_EXECUTE)
 2.5.工作单元拆分细节检查(DBMS_PARALLEL_EXECUTE)
2.5.工作单元拆分细节检查(DBMS_PARALLEL_EXECUTE)
 2. ROWID分区方法并行处理案例(DBMS_PARALLEL_EXECUTE)
2. ROWID分区方法并行处理案例(DBMS_PARALLEL_EXECUTE)
 1. DML任务中的并行性概述(DBMS_PARALLEL_EXECUTE)
1. DML任务中的并行性概述(DBMS_PARALLEL_EXECUTE)









