単語抽出ツールv0.41展開:単語のDBSchema発生頻度エントリを追加
*バグを修正して新しく配布したv0.42も一緒に参照してください。
単語抽出ツール v0.42 配布: Bug fix – 生産性 Skill (prodskill.com)
既存に配布した単語抽出ツール(v0.40)で単語のDBSchema発生頻度項目を追加して抽出する機能を補完して配布する。 DBSchema_Freqエントリは、その単語のソースがいくつのDB-Schemaに分布しているかを示します。

ソース: https://stocksnap.io/photo/dictionary-page-ELRF6CYOHI
1. 単語抽出ツールの結果の変更
以前に配布したツールの単語抽出結果の例は次のとおりです。
▼変更前「単語頻度」シート例(v0.40)
| 言葉 | Freq | Source |
| コード | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(行政区域コード) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(変更区分コード) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(試行コード) … |
| 番号 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(作業シリアル番号) DB1.OWNER1.COMTCZIP.ZIP(郵便番号) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(承認番号) … |
| 人 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(アドレス帳名) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(分類コード名) DB1.OWNER1.COMTCCMMNDETAILCODE.CODE_NM(コード名) … |
v0.41で抽出した結果には、次のようにDBSchema_Freqエントリが追加されます。
▼変更後「単語頻度」シート例(v0.41)
| 言葉 | Freq | Source | DBSchema_Freq |
| コード | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(行政区域コード) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(変更区分コード) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(試行コード) … | 10 |
| 番号 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(作業シリアル番号) DB1.OWNER1.COMTCZIP.ZIP(郵便番号) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(承認番号) … | 9 |
| 人 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(アドレス帳名) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(分類コード名) DB1.OWNER1.COMTCCMMNDETAILCODE.CODE_NM(コード名) … | 5 |
DBSchema_Freqエントリは、その単語のソースがいくつのDB-Schemaに分布しているかを示します。標準単語候補群を選別するのに必要な情報をもう少し詳細に提供することができる。
- 頻度(Freq)は高いがDBSchema頻度(DBSchema_Freq)は低い場合
- その単語は特定のDB-Schemaにのみ集中的に発生しています
- 頻度(Freq)とDBSchema頻度(DBSchema_Freq)の両方が高い場合
- その単語はDB-Schema全体に均等に分布しています
- 頻度(Freq)は低いがDBSchema頻度(DBSchema_Freq)が比較的高い場合
- その単語は標準単語候補に除外せずに含める
2. ソースコードの変更
3つの関数に変更があります。
2.1。 get_db_comment_text関数の変更
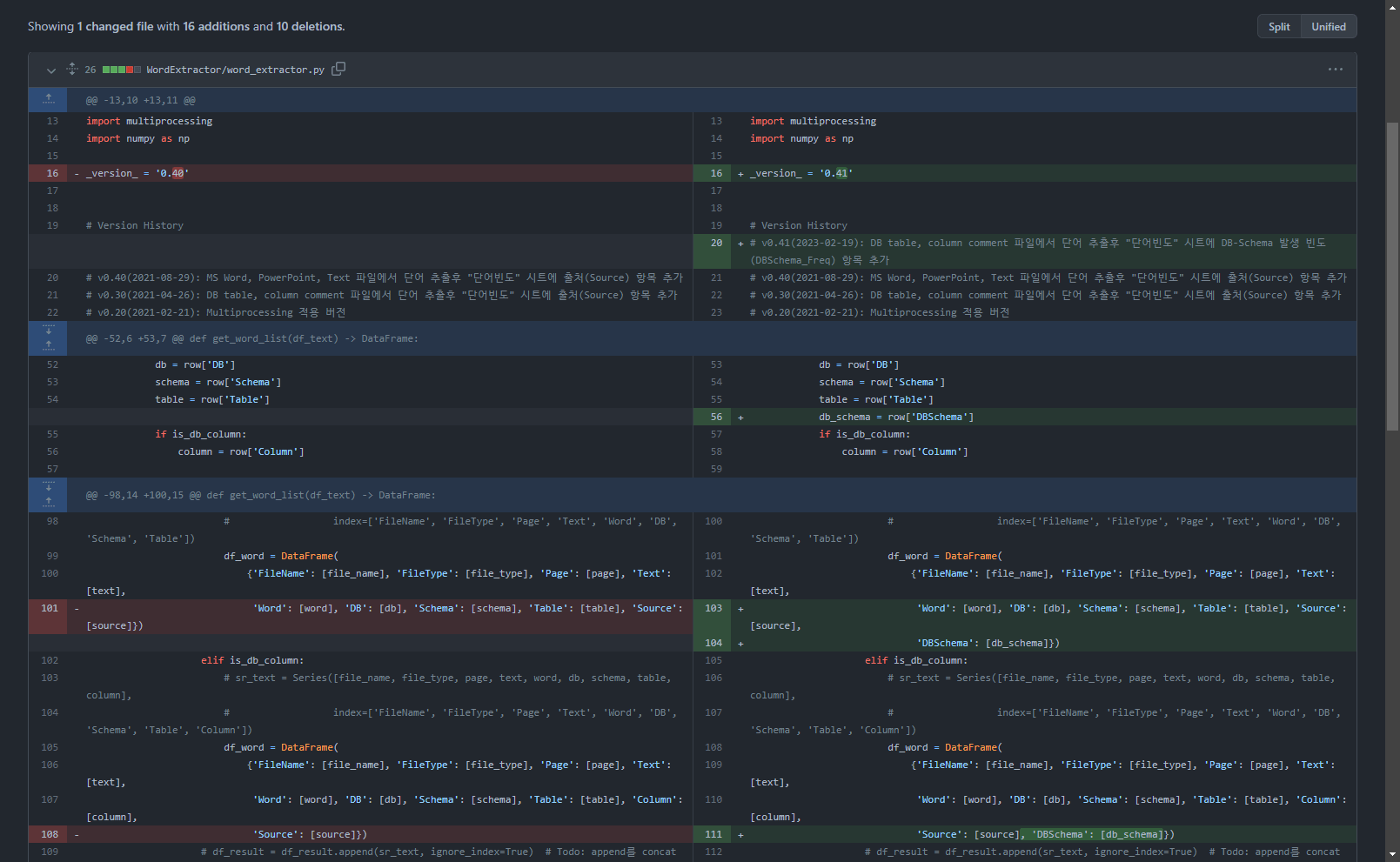
行343を追加:テキスト抽出結果を含むdataframe変数df_textにDBSchema列を作成して値を生成する
df_text['DBSchema'] = df_text['DB'] + '.' + df_text['Schema'] # DB.Schema 값 생성(2023-02-19)
2.2. get_word_list関数の変更
行104、111を追加:単語抽出結果データフレームにDBSchema値を追加する
if len(words) >= 1:
# print(nouns, text)
for word in words:
# print(noun, '\t', text)
if not is_db:
# sr_text = Series([file_name, file_type, page, text, word],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'Source': [source]})
elif is_db_table:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Source': [source],
'DBSchema': [db_schema]})
elif is_db_column:
# sr_text = Series([file_name, file_type, page, text, word, db, schema, table, column],
# index=['FileName', 'FileType', 'Page', 'Text', 'Word', 'DB', 'Schema', 'Table', 'Column'])
df_word = DataFrame(
{'FileName': [file_name], 'FileType': [file_type], 'Page': [page], 'Text': [text],
'Word': [word], 'DB': [db], 'Schema': [schema], 'Table': [table “” not found /]
, 'Column': [column],
'Source': [source], 'DBSchema': [db_schema]})
2.3。 main 関数の変更
2.3.1.変更前のmain関数の内容
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
2.3.2。変更後のmain関数の内容
df_group = df_result.groupby('Word').agg({
'Word': 'count',
'Source': lambda x: '\n'.join(list(x)[:10]),
'DBSchema': 'nunique'
}).rename(columns={
'Word': 'Freq',
'Source': 'Source',
'DBSchema': 'DBSchema_Freq'
})
このコードは、単語抽出結果 dataframe 変数 df_result で Word (単語) で囲み (groupby) DBSchema 値の重複を除去した個数 (nunique) を求め、その項目の名称を DBSchema_Freq と命名する。
ちなみに、このコードは作成したテストコードを ChatGPTに与えて、単純化(simplification)してもらうよう要求してもらったコードだ。単純化する前は、2つのデータフレームに分けてそれぞれlambdaとnuniqueを適用してから、もう1つにmergeする複雑なコードでした。最近 ChatGPT 能力に感心している。
2.4。 v0.41で変わったソースコードの詳細
以下のgithubリンクで変更された内容を詳細に確認できます。
3. 単語抽出ツール(v0.41)のダウンロードと実行
以下のリンクから変更されたword_extractor.pyファイルを確認できます。
ToolsForDataStandard/word_extractor.py at main · DAToolset/ToolsForDataStandard (github.com)
実行方法はv0.40と同じです。以下の内容を参考にしてください。
単語抽出ツールv0.41は十分にテストされていないため、エラーやバグが発生する可能性があります。使用中のエラー、バグ、問い合わせなどはコメントで残してほしい。


















こんにちは!
3つの実行方法の1つであるDBコメントなしでFileから単語を抽出する方法を使用したとき
(python word_extractor.py –in_path .\in –out_path .\out)
txt、word、pptすべて
miniconda3\envs\wordextr\lib\site-packages\pandas\core\apply.py”, line 601, in normalize_dictlike_arg raise KeyError(f”Column(s) {cols_sorted} do not exist”)
KeyError: “Column(s) ['DBSchema'] do not exist”
エラーが発生しながら終了しています。
DB commentファイルが入る2回、3回実行方法はエラーなく動作しています。
97行目に 'DBSchema': [db_schema] を入れてみましたが今回は
in get_grouper raise KeyError(gpr) KeyError: 'Word' というエラーが発生した状況です。
ありがとうございます。
バグ教えてくれてありがとう。
Fileからのみ単語を抽出する場合をテストせずに配布しました。
すぐにテストしてバグ修正したバージョンを再配布します。
バグを修正したv0.42を再デプロイしました。
https://prodskill.com/ko/word-extractor-v0-42-bug-fix-for-dbschema/
ありがとうございます。