単語抽出ツール(4):単語抽出ツールソースコード説明(1)
Pythonで実装された単語抽出ツールのソースコードを見てください。
前の記事で続く内容だ。
単語抽出ツール(3):単語抽出ツールの実行方法と結果を確認する方法
4. 単語抽出ツールのソースコード
4.1。概要
4.1.1.ソースコードを入れる
この単語抽出ツールのソースコードは、私がPythonで作った使いやすいツールの中でほぼ最初に書いたコードです。まだ手に慣れていないときに必要な機能を実装するだけに重点を置いてみると、Pythonの長所である簡潔さとは遠い。 PythonスタイルではなくCスタイルに近い。
テキスト抽出の結果、単語抽出結果を別々のクラスで作成するかと思うが、試しにpandasのDataFrameを使ってみたが思ったよりうまく動作してただDataFrameを使用した。おまけとしてDataFrameが提供するgroupby、to_excel関数を使用して実装するのに時間を大幅に短縮しました。
“「“2.1.2。形態素分析器の選択: Mecab「で述べたように、単語抽出に自然言語形態素アナライザMecabを使用しました。他の形態素アナライザを使用したい場合は、get_word_list関数を修正して使用してください。
本文に挿入したコードの行番号は、githubにアップロードしたソースコードの行番号と同じに設定し、コメントもなるべく除外せずすべて含めた。
4.1.2.単語抽出ツール関数呼び出し関係
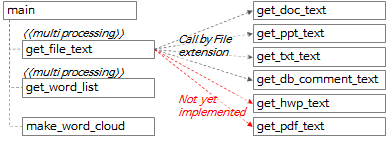
関数全体の呼び出し関係は、上の図式と以下の内容のように要約できます。
- main関数でget_file_text関数を呼び出して、各ファイルから行単位、段落(paragraph)単位のテキストを抽出する。
- get_file_text関数内で、ファイル拡張子に従ってget_doc_text、get_ppt_text、get_txt_text、get_db_comment_text関数を呼び出します。
- get_hwp_text、get_pdf_text関数はまだ実装しておらず、後で必要な時点で実装する予定です。 (もし実装した経験があったり、実装したコードを知っていればコメントとして残してほしい。)
- get_file_text関数実行結果をget_word_list関数に渡して単語候補群を抽出する。
- get_file_text関数とget_word_list関数はmultiprocessingとして扱われます。
- make_word_cloud関数を呼び出してword cloudイメージを作成します。
4.2。 main関数
4.2.1. argument parsing
def main():
"""
지정한 경로 하위 폴더의 File들에서 Text를 추출하고 각 Text의 명사를 추출하여 엑셀파일로 저장
:return: 없음
"""
# region Args Parse & Usage set-up -------------------------------------------------------------
# parser = argparse.ArgumentParser(usage='usage test', description='description test')
usage_description = """--- Description ---
* db_comment_file과 in_path중 하나는 필수로 입력
* 실행 예시
1. File에서 text, 단어 추출: in_path, out_path 지정
python word_extractor.py --multi_process_count 4 --in_path .\\test_files --out_path .\out
2. DB comment에서 text, 단어 추출: db_comment_file, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --out_path .\out
3. File, DB comment 에서 text, 단어 추출: db_comment_file, in_path, out_path 지정
python word_extractor.py --db_comment_file "table,column comments.xlsx" --in_path .\\test_files --out_path .\out
* DB Table, Column comment 파일 형식
- 첫번째 sheet(Table comment): DBName, SchemaName, Tablename, TableComment
- 두번째 sheet(Column comment): DBName, SchemaName, Tablename, ColumnName, ColumnComment"""
# ToDo: 옵션추가: 복합어 추출할지 여부, 영문자 추출할지 여부, 영문자 길이 1자리 제외여부, ...
parser = argparse.ArgumentParser(description=usage_description, formatter_class=argparse.RawTextHelpFormatter)
# name argument 추가
parser.add_argument('--multi_process_count', required=False, type=int,
help='text 추출, 단어 추출을 동시에 실행할 multi process 개수(지정하지 않으면 (logical)cpu 개수로 설정됨)')
parser.add_argument('--db_comment_file', required=False,
help='DB Table, Column comment 정보 파일명(예: comment.xlsx)')
parser.add_argument('--in_path', required=False, help='입력파일(ppt, doc, txt) 경로명(예: .\in) ')
parser.add_argument('--out_path', required=True, help='출력파일(xlsx, png) 경로명(예: .\out)')
args = parser.parse_args()
if args.multi_process_count:
multi_process_count = int(args.multi_process_count)
else:
multi_process_count = multiprocessing.cpu_count()
db_comment_file = args.db_comment_file
if db_comment_file is not None and not os.path.isfile(db_comment_file):
print('db_comment_file not found: %s' % db_comment_file)
exit(-1)
in_path = args.in_path
out_path = args.out_path
print('------------------------------------------------------------')
print('Word Extractor v%s start --- %s' % (_version_, get_current_datetime()))
print('##### arguments #####')
print('multi_process_count: %d' % multi_process_count)
print('db_comment_file: %s' % db_comment_file)
print('in_path: %s' % in_path)
print('out_path: %s' % out_path)
print('------------------------------------------------------------')
- 行395:argparseパッケージのArgumentParserオブジェクトを作成します。
- 行 397~404: 必要な argument を追加し、実行時に指定した argument を parsing する。
- 行406~425: argument を内部変数に設定し、設定された値を出力する。
4.2.2。処理するファイルのリストを抽出する
file_list = []
if in_path is not None and in_path.strip() != '':
print('[%s] Start Get File List...' % get_current_datetime())
in_abspath = os.path.abspath(in_path) # os.path.abspath('.') + '\\test_files'
file_types = ('.ppt', '.pptx', '.doc', '.docx', '.txt')
for root, dir, files in os.walk(in_abspath):
for file in sorted(files):
# 제외할 파일
if file.startswith('~'):
continue
# 포함할 파일
if file.endswith(file_types):
file_list.append(root + '\\' + file)
print('[%s] Finish Get File List.' % get_current_datetime())
print('--- File List ---')
print('\n'.join(file_list))
if db_comment_file is not None:
file_list.append(db_comment_file)
- 行436:処理対象ファイルに対応するファイル拡張子のリストを定義する。
- 行437~444:実行時に指定した argument 中 in_path 子のフォルダ全体を再帰探索しながら各ファイルが対象ファイルかどうかを判断し、対象ファイルであれば file_list に追加する。
- 行 451~452: 実行時に指定した argument 中に db_comment_file があれば file_list に追加する。
4.2.3。 Multi processingでget_file_textを実行する
print('[%s] Start Get File Text...' % get_current_datetime())
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_text_result = pool.map(get_file_text, file_list)
df_text = pd.concat(mp_text_result, ignore_index=True)
print('[%s] Finish Get File Text.' % get_current_datetime())
# 여기까지 text 추출완료. 아래에 단어 추출 시작
- 行455~456:実行時に指定したmulti_process_countだけprocessを実行し、各processでfile_lsitを入力としてget_file_text関数を実行し、その結果をmp_text_resultに入れる。
- 行457:DataFrameのlist形式であるmp_text_resultの各list itemをまとめて1つのDataFrameであるdf_textにする。
4.2.4。 Multi processingでget_word_listを実行する
# ---------- 병렬 실행 ----------
print('[%s] Start Get Word from File Text...' % get_current_datetime())
df_text_split = np.array_split(df_text, multi_process_count)
# mp_result = []
with multiprocessing.Pool(processes=multi_process_count) as pool:
mp_result = pool.map(get_word_list, df_text_split)
df_result = pd.concat(mp_result, ignore_index=True)
if 'DB' not in df_result.columns:
df_result['DB'] = ''
df_result['Schema'] = ''
df_result['Table'] = ''
df_result['Column'] = ''
print('[%s] Finish Get Word from File Text.' % get_current_datetime())
# ------------------------------
- 行463:df_textの行をmulti_process_countに分割し、各分割されたDataFrameをdf_text_split(list type)に格納します。
- たとえば、df_textに1000行があり、multi_process_countが4の場合、それぞれ250行の4つのDataFrameが作成され、この4つのDataFrameをitemに持つdf_text_split変数が作成されます。
- 行465~466:実行時に指定したmulti_process_countだけprocessを実行し、各processでdf_text_splitを入力としてget_word_list関数を実行し、その結果をmp_resultに入れる。
- 行468:DataFrameのlist形式であるmp_resultの各list itemをまとめて1つのDataFrameであるdf_resultにする。
- 行469〜473:df_result.columnsに 'DB'がない場合、つまりdb_comment_fileが指定されていない場合は、後続の処理ロジックを単純化し、エラーを防ぐために 'DB'、 'Schema'、 'Table'、 'Column 'という名前の列を空の値として追加します。
4.2.5。単語の頻度を求めて make_word_cloud を実行する
print('[%s] Start Get Word Frequency...' % get_current_datetime())
# df_group = pd.DataFrame(df_result.groupby(by='Word').size().sort_values(ascending=False))
df_result_subset = df_result[['Word', 'Source']] # 빈도수를 구하기 위해 필요한 column만 추출
# df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: list(x)])
df_group = df_result_subset.groupby(by='Word').agg(['count', lambda x: '\n'.join(list(x)[:10])])
df_group.index.name = 'Word' # index명 재지정
df_group.columns = ['Freq', 'Source'] # column명 재지정
df_group = df_group.sort_values(by='Freq', ascending=False)
print('[%s] Finish Get Word Frequency.' % get_current_datetime())
# df_group['Len'] = df_group['Word'].str.len()
# df_group['Len'] = df_group['Word'].apply(lambda x: len(x))
print('[%s] Start Make Word Cloud...' % get_current_datetime())
now_dt = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
make_word_cloud(df_group, now_dt, out_path)
print('[%s] Finish Make Word Cloud.' % get_current_datetime())
- 行480:df_resultから 'Word'、 'Source'列のみを選択してdf_result_subset DataFrameを作成します。
- 行482:df_result_subsetを「Word」列にグループ化してカウントを取得し、「Source」の最初の10個の値を抽出して行分離記号で連結してdf_group DataFrameを作成します。
- 行483~484:df_group DataFrameのindex名を「Word」、column名をそれぞれ「Freq」、「Source」と指定する。
- 行485:df_groupを「Freq」(単語の頻度)に逆並べ替える。
- 行491:df_groupをmake_word_cloud関数に渡して、word cloudイメージを作成して保存します。
4.2.6。抽出された単語リストと単語頻度Excelファイルとして保存し、ランタイム出力、終了
print('[%s] Start Save the Extract result to Excel File...' % get_current_datetime())
df_result.index += 1
excel_style = {
'font-size': '10pt'
}
df_result = df_result.style.set_properties(**excel_style)
df_group = df_group.style.set_properties(**excel_style)
out_file_name = '%s\\extract_result_%s.xlsx' % (out_path, now_dt) # 'out\\extract_result_%s.xlsx' % now_dt
print('start writing excel file...')
with pd.ExcelWriter(path=out_file_name, engine='xlsxwriter') as writer:
df_result.to_excel(writer,
header=True,
sheet_name='단어추출결과',
index=True,
index_label='No',
freeze_panes=(1, 0),
columns=['Word', 'FileName', 'FileType', 'Page', 'Text', 'DB', 'Schema', 'Table', 'Column'])
df_group.to_excel(writer,
header=True,
sheet_name='단어빈도',
index=True,
index_label='단어',
freeze_panes=(1, 0))
workbook = writer.book
worksheet = writer.sheets['단어빈도']
wrap_format = workbook.add_format({'text_wrap': True})
worksheet.set_column("C:C", None, wrap_format)
# print('finished writing excel file')
print('[%s] Finish Save the Extract result to Excel File...' % get_current_datetime())
end_time = time.time()
# elapsed_time = end_time - start_time
elapsed_time = str(datetime.timedelta(seconds=end_time - start_time))
print('------------------------------------------------------------')
print('[%s] Finished.' % get_current_datetime())
print('overall elapsed time: %s' % elapsed_time)
print('------------------------------------------------------------')
- 行495〜501:Excelフォントサイズを10ポイントで指定し、保存するExcelファイルのパスとファイル名を設定します。
- 行504〜521:pandas ExcelWriterを使用してdf_result、df_group DataFrameをExcelファイルとして保存します。
- 行526~532:実行に要した時間を計算して出力して終了する。
内容が長くなって文を二つに分けて上げる。次の記事に続きます。
<< 関連記事のリスト >>


















こんにちは
アップロードした単語抽出ツールのソードコードと「pdfplumber」を活用してget_pdf_text機能を作成しました。
コメントやメールでお見せできますか?
こんにちは!
アップロードした単語抽出ツールのソースコードを活用して、get_pdf_text関数を実装してみました。
既存のコードのうち、ファイル拡張子関連部分にpdfを追加し、get_pdf_tex関数を追加したときに動作することを確認しました。
修正すべき部分を教えてください。処理します。
pip install pdfplumberが必要です。
import pdfplumber
def get_pdf_text(file_name) -> DataFrame:
start_time = time.time()
print('\r\nget_txt_text: ' + file_name)
df_text = pd.DataFrame()
pdf_file = pdfplumber.open(file_name)
page=0
for pg in pdf_file.pages:
texts = pg.extract_text()
page += 1
for text in texts.split():
if text.strip() != ”:
sr_text = Series([file_name, 'pdf', page, text, f'{file_name}:{page}:{text}'],
index=['FileName', 'FileType', 'Page', 'Text', 'Source'])
df_text = df_text.append(sr_text, ignore_index=True)
print('text count: %s' % str(df_text.shape[0]))
print('page count: %d' % page)
pdf_file.close()
end_time = time.time()
elapsed_time = str(datetime.timedelta(seconds=end_time – start_time))
print('[pid:%d] get_pdf_text elapsed time: %s' % (os.getpid(), elapsed_time))
return df_text
get_pdf_text関数ソースコードを共有していただきありがとうございます。
作成したソースコードはインデントになっていますが、WordPressのコメントでインデントが表示されないので、見方が少し不便ですね。
インデントが表示されるように設定しましょう。
インデントを見せるように設定するときは、もしインデントされているオリジナルのソースコードが必要な場合は、もう一度アップロードします。