単語抽出ツール(1):単語抽出ツールの概要
データの標準化作業、特に標準単語候補の作成に役立つことができる単語抽出ツールの概要を見てください。
1. 単語抽出ツールの概要
1.1。単語抽出ツールを開発した理由
データ標準化初期作業の中で最も難しい作業は、標準単語として登録する候補群をできるだけ多く、かつ早く収集する作業である。データ標準チェックツール(参照: データ標準チェックツール_1。概要)を標準単語候補群を抽出するのに活用することができるが、次の困難がある。
- Database table, column comment 資料に特殊文字 (#, $, %, ., \ などの記号や行分離文字など) が多く含まれている場合、これを削除または精製する努力がかなり必要である。
- 単語の頻度がわかりにくく、単一の単語でのみ登録するのか、複合語でのみ登録するのか、単一の単語と複合語の両方を登録するのかという判断が難しい
- 標準単語が確定した後、後で複合語が識別され、すでに登録されている標準用語の物理名に影響を及ぼす場合、標準命名規則に例外が生じ、管理が難しくなることがある
単語抽出ツールは、このような困難を少しでも解消しようと開発した。特に、次のような場合に役立つと期待する。
- 現行データ標準辞書がない場合でも、標準単語の数が少ない場合
- 仕事が非常にユニークで、参照に適したデータ標準辞書がない場合
- Database table, column comment が大きすぎて手作業で単語を抽出するのに時間がかかる場合
- またはその逆に、データベーステーブル、列コメントに内容がほとんどないため、標準単語を抽出するのに不適切であり、作業マニュアルなどの文書から抽出するのが適切な場合
- その他、文書から単語や頻度抽出が必要な場合
1.2.単語抽出ツールの概念
単語抽出ツールは、さまざまな形式のファイルを入力として受け取り、自然言語処理形態素アナライザを用いて単語、複合語を抽出し、その頻度とソース(ファイル名、table名、column名など)をExcelファイルに出力するツールです。
韓国語自然言語処理(NLP、Natural Language Processing)形態素分析器であるMecabを使用し、Python v3.8で開発した。韓国語自然言語処理形態素分析器の中で公開された図書館は、Kkma、Komoran、Hannanum、Okt(旧名称Twitter)、Mecabが代表的だ。この中でMecabを選んだ理由は性能が一番良いからだ。
自然言語処理形態素アナライザの性能比較は、以下のリンクで確認できます。
参照: https://konlpy.org/ko/latest/morph/#comparison-between-pos-tagging-classes
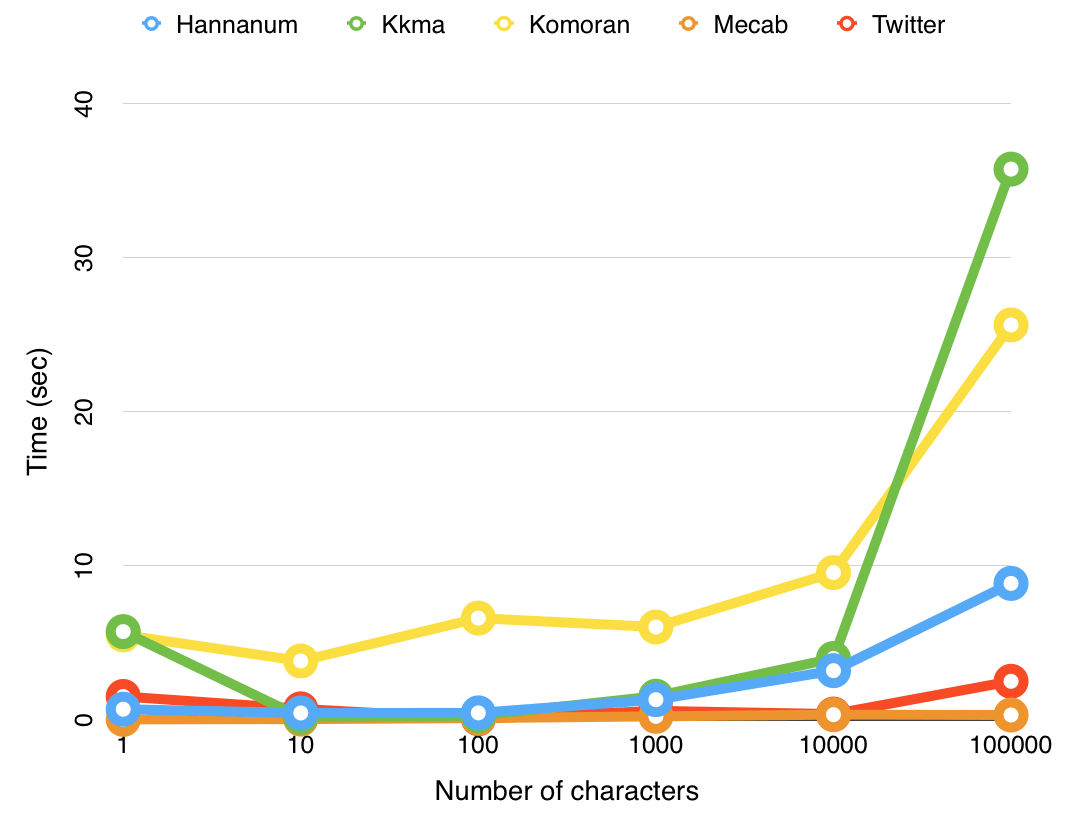
入力文字数の増加による実行時間は次のようにまとめることができます。 (左から右へ行くほど実行時間が短縮され、性能が良くなる)
Kkma > Komoran > Hannanum > Okt(Twitter) > Mecab
参考までに、上記のリンクは KoNLPyパッケージを開発した方のサイトです。 KoNLPyはPythonベースで複数の形態素アナライザを一つにまとめて提供するパッケージです。
KoNLPy: https://konlpy.org/ko/latest/
1.3。単語抽出ツールの仕組み
入力データ、処理ロジック、出力データについて簡単に説明します。
1.3.1。単語抽出ツール入力材料
入力データは、次の2つのいずれかまたは両方を指定できます。
- 資料:MS Word、PowerPoint、Textファイル
- この記事を書いている現在の時点(2021-08-29)では、HWP、PDF形式はまだサポートされていません。
- DB Table, Column comment 資料: Excel ファイル
- Table comment データ項目: Database, Schema, Table Name, Table Comment
- Column comment データ項目: Database, Schema, Table Name, Table Comment, Column Name, Column Comment
▼ Table comment 資料の例は次の通りである。
| データベース | スキーマ | テーブル名 | Table Comment |
| DB1 | OWNER1 | COMTCADMINISTCODE | 行政コード |
| DB1 | OWNER1 | COMTCADMINISTCODERECPTNLOG | 行政コード受信ログ |
| DB1 | OWNER1 | COMTCCMMNCLCODE | 共通分類コード |
| DB1 | OWNER1 | COMTCCMMNCODE | 共通コード |
| DB1 | OWNER1 | COMTCCMMNDETAILCODE | 共通詳細コード |
▼ Column comment 資料の例は次の通りである。上記TableリストのうちCOMTCADMINISTCODE(行政コード)のcolumnリストである。
| データベース | スキーマ | テーブル名 | 列名 | Column Comment |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE | 行政区域区分 |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE | 行政区域コード |
| DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT | 使用可否 |
| DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM | 行政区域名 |
| DB1 | OWNER1 | COMTCADMINISTCODE | UPPER_ADMINIST_ZONE_CODE | 上行政区域コード |
| DB1 | OWNER1 | COMTCADMINISTCODE | CREAT_DE | 作成日 |
| DB1 | OWNER1 | COMTCADMINISTCODE | ABL_DE | 廃止日 |
| DB1 | OWNER1 | COMTCADMINISTCODE | FRST_REGIST_PNTTM | 初登録時点 |
| DB1 | OWNER1 | COMTCADMINISTCODE | FRST_REGISTER_ID | 最初の登録者ID |
| DB1 | OWNER1 | COMTCADMINISTCODE | LAST_UPDT_PNTTM | 最終修正時点 |
| DB1 | OWNER1 | COMTCADMINISTCODE | LAST_UPDUSR_ID | 最終修正者ID |
*上記の例資料は、電子政府標準フレームワークv3.8の「共通コンポーネントテーブル構成情報」ページでtable、column comment scriptを活用して作成しました。
(出典: https://www.egovframe.go.kr/wiki/doku.php?id=egovframework:com:v3.8:init_table)
1.3.2。単語抽出ツール処理ロジック
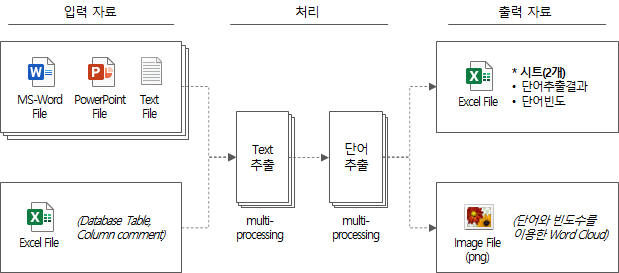
全体の処理ロジックを簡単にまとめると、次のようになります。
- 入力データを順番に開いてテキスト(行単位、table/column単位)を抽出
- 自然言語形態素分析器パッケージであるMecabを用いて、名詞1個、名詞n個、接頭辞+名詞n個、名詞n個+接尾辞、接頭辞+名詞n個+接尾辞の形である単語候補群抽出
- 全入力資料から抽出した単語の頻度を求め、単語抽出結果を出力ファイルとして保存
- 単語リストと頻度でword cloudをpngファイルとして生成して保存
- 全体の所要時間を出力して終了
上記の処理過程を簡単に図式化すれば次の通りである。
1.3.3。単語抽出ツール出力データ
入力データを処理した結果である出力データは、ExcelファイルとWord cloud形式のイメージ(png)ファイルの2つです。
Excelファイルは2つのシートで構成されています。以下は、DB Table、Column comment資料を入力にした場合の例です。
▼「単語抽出結果」シート例
| いいえ | Word | FileName | FileType | ページ | Text | DB | スキーマ | テーブル | Column |
| 1 | 行政 | table,column comments.xlsx | column | 0 | 行政区域区分 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 2 | ゾーン | table,column comments.xlsx | column | 0 | 行政区域区分 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 3 | 区分 | table,column comments.xlsx | column | 0 | 行政区域区分 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 4 | 行政区域区分[複合語] | table,column comments.xlsx | column | 0 | 行政区域区分 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_SE |
| 5 | 行政 | table,column comments.xlsx | column | 0 | 行政区域コード | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 6 | ゾーン | table,column comments.xlsx | column | 0 | 行政区域コード | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 7 | コード | table,column comments.xlsx | column | 0 | 行政区域コード | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 8 | 行政区域コード[複合語] | table,column comments.xlsx | column | 0 | 行政区域コード | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_CODE |
| 9 | 使用 | table,column comments.xlsx | column | 0 | 使用可否 | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 10 | かどうか | table,column comments.xlsx | column | 0 | 使用可否 | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 11 | 使用可否[複合語] | table,column comments.xlsx | column | 0 | 使用可否 | DB1 | OWNER1 | COMTCADMINISTCODE | USE_AT |
| 12 | 行政区 | table,column comments.xlsx | column | 0 | 行政区域名 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 13 | 駅名 | table,column comments.xlsx | column | 0 | 行政区域名 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
| 14 | 行政区域名[複合語] | table,column comments.xlsx | column | 0 | 行政区域名 | DB1 | OWNER1 | COMTCADMINISTCODE | ADMINIST_ZONE_NM |
- 「Text」列:入力データから抽出された元の値であり、この例ではtable、column commentに対応します。
- 「Word」列:TextでMecabを使用して抽出した単語候補です。複合語は suffix で「[複合語]」を指定する。
- 12行「行政区」、13行「駅名」は、Mecabから「行政区域名」から抽出した単語である。
- 実際に使用する単語とは異なって抽出され、精度が100%ではないことが分かる。
▼「単語頻度」シート例
| 言葉 | Freq | Source |
| コード | 110 | DB1.OWNER1.COMTCADMINISTCODE.ADMINIST_ZONE_CODE(行政区域コード) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CHANGE_SE_CODE(変更区分コード) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.CTPRVN_CODE(試行コード) … |
| 番号 | 103 | DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OPERT_SN(作業シリアル番号) DB1.OWNER1.COMTCZIP.ZIP(郵便番号) DB1.OWNER1.COMTHCONFMHISTORY.CONFM_NO(承認番号) … |
| 人 | 88 | DB1.OWNER1.COMTNADBKMANAGE.ADBK_NM(アドレス帳名) DB1.OWNER1.COMTCCMMNCLCODE.CL_CODE_NM(分類コード名) DB1.OWNER1.COMTCCMMNDETAILCODE.CODE_NM(コード名) … |
| 仕事 | 85 | DB1.OWNER1.COMTCADMINISTCODE.CREAT_DE(作成日) DB1.OWNER1.COMTCADMINISTCODE.ABL_DE(廃止日) DB1.OWNER1.COMTCADMINISTCODERECPTNLOG.OCCRRNC_DE(発生日) … |
| 情報 | 77 | DB1.OWNER1.COMTHDBMNTRNGLOGINFO.LOG_INFO(ログ情報) DB1.OWNER1.COMTNBACKUPRESULT.ERROR_INFO(エラー情報) DB1.OWNER1.COMTNINDVDLINFOPOLICY.INDVDL_INFO_POLICY_ID(個人情報ポリシーID) … |
| かどうか | 75 | DB1.OWNER1.COMTCADMINISTCODE.USE_AT(使用不可) DB1.OWNER1.COMTNANNVRSRYMANAGE.REPTIT_AT(繰り返し可否) DB1.OWNER1.COMTNBANNER.REFLCT_AT (反映なし) … |
- 「単語」列:「単語抽出結果」シートの「Word」列を重複除去した文字列値である。これは標準単語として登録する候補です。
- 「Freq」列:単語が何回使用されたかを示す頻度。結果リストは、この頻度の高い単語から低い単語に逆順に並べられています。
- 「Source」列:対応する単語のソースを示します。最大10個のソースを表示します。
- ソースが Table の場合 形式: DB.Schema.TableName(Table comment)
- ソースが Column の場合 形式: DB.Schema.TableName.ColumnName(Column comment)
- ソースがFileの場合形式:ファイル名:ページ番号:Text
抽出単語の頻度で生成したWord cloud画像の例は次のとおりです。頻度の多い単語が大きく表示されます。

単語抽出ツールはPythonで開発されたツールであり、実行前にPythonや必要なpackageインストールなどの環境構成プロセスが必要です。次に、環境構成プロセスを見てみましょう。
<< 関連記事のリスト >>

















